AWS 기술 블로그
Category: Amazon Bedrock

Agentic AI 기반 플랫폼 – 7주만에 기획부터 배포까지, Part1: AI-DLC 방법론과 유용한 도구들
들어가며 최근 저자들은 단 2명이서 7주 만에 Agentic AI 기반 플랫폼을 엔드투엔드로 구축했습니다. 디자이너도 없었고 기획자도 없었습니다. MCP(Model Context Protocol) 생성, AI Agent 생성부터 실시간 테스트 환경까지 갖춘 플랫폼이었고, 단순한 아이디어에서부터 실제 동작하는 웹 애플리케이션까지, 2주의 기획, 2주의 문서작업 및 세부 사항 협의, 3주의 개발 및 배포 기간이 소요되었습니다. 예전의 전통적인 개발 방법으로는 상상도 못할 […]

LG유플러스, Bedrock AgentCore를 활용한 손쉬운 클라우드 Agent 구현 사례
UCMP 소개 오늘날 대부분의 기업들은 AWS, GCP, Azure 등 다양한 클라우드 환경을 활용해 서비스를 개발하고 있습니다. 하지만 클라우드 사업자마다 계정 구조와 운영 정책이 달라 사용자 입장에서는 환경마다 서로 다른 방식으로 관리해야 하는 불편함이 있습니다. 이러한 문제를 해결하고 일관된 사용자 경험으로 클라우드를 운영할 수 있도록 LG유플러스는 자체 클라우드 관리 플랫폼 UCMP(Uplus Cloud Management Platform)를 구축해 멀티 […]
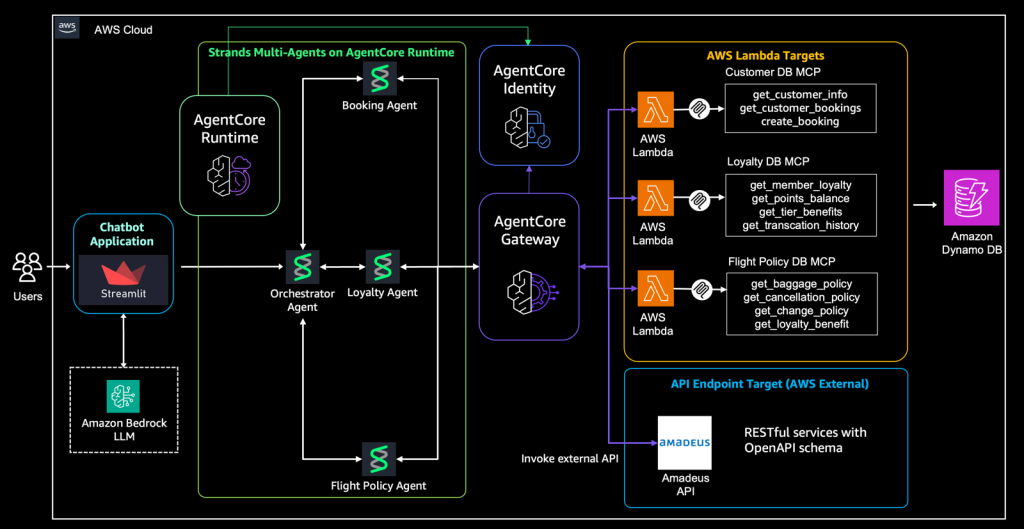
Amazon Bedrock AgentCore를 활용한 멀티에이전트 운영과 접근제어
AI 에이전트를 처음 구축할 때 가장 단순한 접근 방식은 하나의 에이전트가 외부 서비스(API, MCP)를 직접 호출하도록 구성하는 것 입니다. 이러한 구조는 초기 PoC 단계에서는 구현이 간단하고, 빠르게 아이디어를 검증하는 데 효과적입니다. 그러나 에이전트 기반 시스템을 엔터프라이즈 환경으로 확장하기 시작하면, 이러한 접근 방식은 곧 한계에 부딪히게 됩니다. 에이전트의 수가 증가하고 외부 API, MCP 내부 서비스가 지속적으로 […]

Agentic AI 부터 Physical AI 까지: Bedrock, MCP, AWS IoT로 구축하는 자율 산업 안전 로봇
1. 서론: Physical AI – 디지털 지능과 물리적 행동의 융합 1.1 배경 최근에는 LLM과 멀티모달 모델이 발전하면서 단순 자동화를 넘어 스스로 계획하고 판단하고 실세계에 직접 작용하는 Agentic AI와 디지털 세계를 넘어 물리적 세계와 상호작용하는 Physical AI의 필요성이 높아지고 있습니다. 지금까지 우리가 경험한 AI 시스템은 대부분 디지털 환경 내에서만 작동했습니다. 챗봇과 대화하고, 이미지를 생성하고, 문서를 요약하는 […]

AWS re:Invent 2025 요약: 자동차 및 제조업 하이라이트
본 블로그는 Emily O’Kelly와 Andreas Bogner, Ali Zagros, Chandana Keswarkar가 작성한 블로그를 번역, 편집하였습니다. Amazon Web Services re:Invent 2025가 12월 5일 라스베이거스에서 성공적으로 마무리되었으며, 63,000명 이상의 현장 참석자와 200만 명 이상의 라이브스트림 시청자가 함께했습니다. 5일간의 학습과 네트워킹 기간 동안 전 세계 비즈니스 리더들은 클라우드와 AI 기술을 활용하여 경쟁 우위를 확보하고 고객 경험을 향상시키는 방법을 탐구했습니다. […]

TwelveLabs Marengo를 활용한 Amazon Bedrock에서의 영상 이해 기술 구현
이 글은 Artificial Intelligence 블로그에 게시된 글 (Unlocking video understanding with TwelveLabs Marengo on Amazon Bedrock)을 한국어로 번역 및 편집하였습니다. 미디어와 엔터테인먼트, 광고, 교육, 그리고 기업 교육에서 사용되는 콘텐츠는 시각, 청각, 그리고 동작 요소를 결합하여 이야기를 전달하고 정보를 전달합니다. 이러한 콘텐츠는 각 단어의 의미가 명확한 텍스트와 달리 훨씬 더 복잡합니다. 이로 인해 비디오 콘텐츠를 이해해야 […]

클로봇의 Amazon Bedrock 과 LangGraph 를 활용한 건설현장 해충 방역 전문 AI 챗봇 개발기
1. 회사 소개 클로봇은 이기종 로봇 자율주행 솔루션과 관제 솔루션을 기반으로 안내, 이송, 청소·방역, 안전·보안, 물류, 제조 등 다양한 분야에 로봇 서비스를 제공하는 기업입니다. 클로봇은 글로벌 네트워크를 구축해 고객이 필요로 하는 로봇 하드웨어(서비스 로봇, 물류 로봇, 산업용 로봇)를 소싱해 공급하고 있습니다. 아울러 클로봇은 원천 기술에 객체 인식, 깊이(거리)·자세 추정 등 AI 인지 모듈을 통합해 주행 […]

VMS Solutions의 AI Agent 기반 내부 생산성 개선기: Strands Agents를 통한 자체 에이전트 구축 여정
VMS Solutions (브이엠에스 솔루션스)는 반도체와 디스플레이 제조 공정의 생산 계획을 최적화하는 AI 솔루션 기업으로, 2024년 가트너 아시아태평양 Supply Chain Planning 분야 Notable Vendor로 선정되었습니다. 25년 이상 글로벌 제조업체의 공급망 최적화를 지원해온 VMS Solutions는 이제 자사 내부에도 AI 혁신을 적용하고 있습니다. 그 결과물이 바로 인프라 운영과 개발 관련 질의를 자동화하는 AI 에이전트 기반 챗봇 솔루션 ‘AIto’입니다. […]

Strands Agents와 Amazon Bedrock AgentCore를 활용해 포스트잇 워크숍을 파워포인트로 정리하기
디자인 씽킹 워크숍, 브레인스토밍 세션, 이벤트스토밍 워크숍 등에서 포스트잇은 빠질 수 없는 도구입니다. 다양한 전문가와 기관이 포스트잇을 활용하여 참가자들의 아이디어를 빠르게 수집하고 시각화하면서 워크샵을 진행합니다. 하지만 워크샵이 끝나고 나면 진짜 일이 시작됩니다. 수백 개의 포스트잇을 일일이 읽고, 유사한 내용끼리 묶고, 이를 보고서나 프레젠테이션으로 정리하는 작업에 약 2~3일의 시간이 소요됩니다. <AnyCompany의 SWOT 워크숍 예시> 본 포스팅에서는 […]

Amazon Bedrock AgentCore Memory: 기억하는 AI 에이전트 만들기
AI 에이전트에게 기억이란? ChatGPT가 세상에 나온 지 어느덧 3년이 지났고 이제 생성형 AI는 단순한 신기함을 넘어 우리의 일상과 업무 프로세스 깊숙이 녹아들었습니다. 우리는 AI와 자유롭게 대화하며 마치 사람과 이야기하듯 자연스럽게 질문을 던지고 답변을 받습니다. 하지만 우리가 당연하게 느끼는 이 ‘대화의 연속성‘ 뒤에는 기술적 난제가 숨겨져 있습니다. 바로 생성형 AI 모델의 본질적인 특성, Statelessness입니다. 생성형AI 모델 […]