AWS 기술 블로그
Category: Advanced (300)

AWS Backup를 활용하여 백업 데이터 복원 테스트를 구현하기
미션 크리티컬 애플리케이션은 전자상거래부터 의료에 이르기까지 다양한 분야를 지원하므로, 견고한 백업 전략은 단순한 모범 사례가 아닌 필수 요소입니다. 랜섬웨어와 같은 위협이 점점 더 정교해지는 상황에서 AWS 사용자에게는 백업 보유만으로는 충분하지 않습니다. 조직들은 재해가 발생했을 때 이러한 안전장치가 제대로 작동할 것이라는 확신이 필요합니다. 수동 테스트는 필수적이지만 IT 리소스를 소모합니다. 정기적인 자동화된 복원 테스트를 통해 조직은 효율성 향상뿐만 아니라 백업 무결성 검증, […]
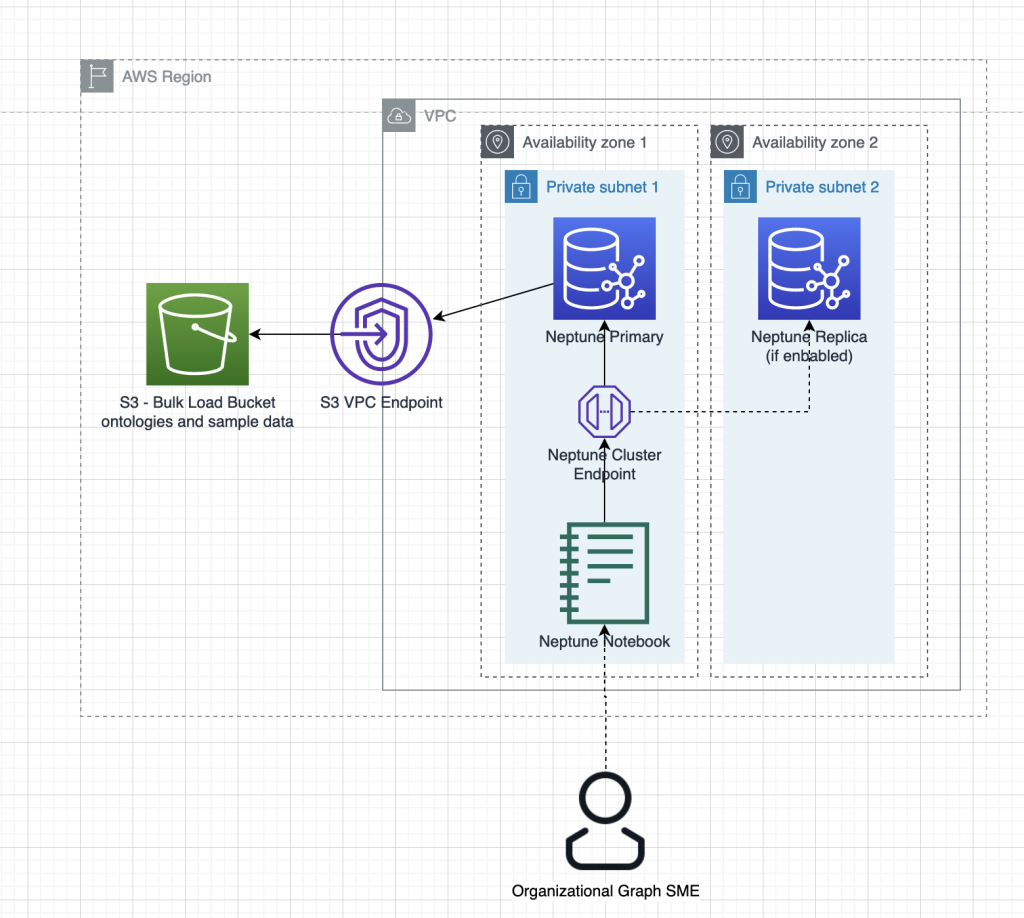
Amazon Neptune에서 온톨로지를 사용한 모델 기반 지식 그래프 만들기
본 게시글은 AWS Database Blog에 게시된 Model-driven graphs using OWL in Amazon Neptune by Mike Havey을 한국어 번역 및 편집하였습니다. Amazon Neptune은 비즈니스 객체 간의 관계를 지식 그래프로 구축하는 데 사용할 수 있는 AWS에서 제공하는 그래프 데이터베이스 서비스입니다. 지식 그래프를 구축할 때, 이러한 관계의 표현을 관리하기 위한 적합한 모델은 무엇일까요? 그래프를 즉석에서 구축하기보다는 우리를 안내할 […]

보이저엑스의 ComfyUI 워크플로우 기반 AI 비디오 생성 파이프라인 구축 여정
보이저엑스(VoyagerX)의 Vrew는 AI기술을 활용해 쉽고 편한 영상 편집 경험을 제공하는 서비스입니다. 자동 자막 생성으로 영상 속 대사를 자동으로 텍스트로 변환해 주고, 이를 문서처럼 편집할 수 있는 편리한 UX를 제공합니다. 또한 AI를 활용한 대본 생성, 목소리 생성, 이미지 생성으로 영상편집 초보자도 쉽게 사용할 수 있습니다. 최근 오픈소스 비디오 생성 모델이 다수 공개되면서, 저희 서비스에도 AI 비디오 […]
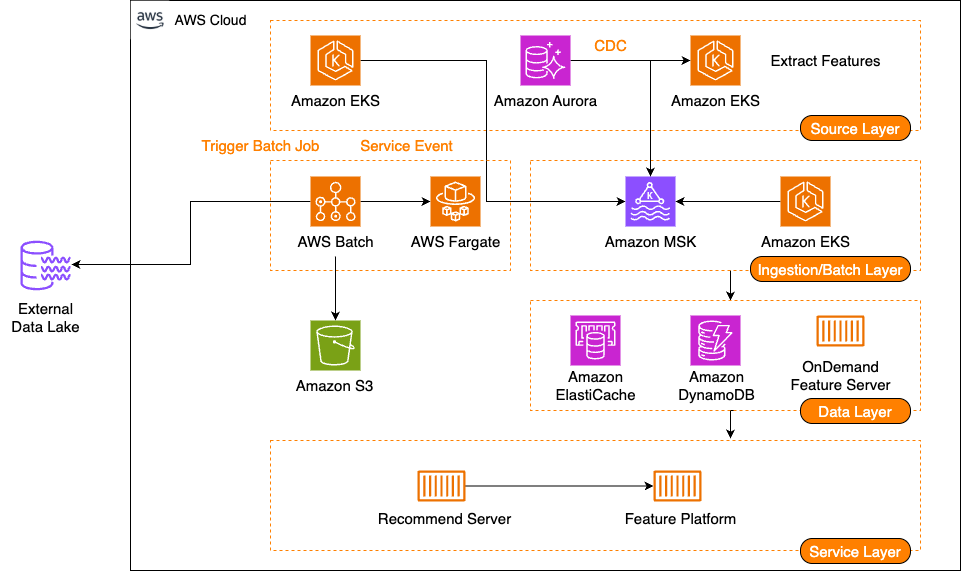
당근의 AWS 기반 피처 플랫폼 구축 여정, Part 2: 피처 수집
해당 포스트는 당근의 김현호님, 서진형님, 권민재님과 함께 작성했으며, 이전에 AWS 글로벌 블로그에 포스팅한 영문 블로그와 동일한 내용입니다. 이 시리즈의 1부에서는 당근이 개발한 새로운 피처 플랫폼에 대해 다루었습니다. 이 플랫폼은 피처 서빙, 스트림 수집 파이프라인, 배치 수집 파이프라인의 세 가지 주요 구성 요소로 이루어져 있습니다. 또한 요구사항, 솔루션 아키텍처, 다단계 캐시를 활용한 피처 서빙에 대해 설명했습니다. […]

당근의 AWS 기반 피처 플랫폼 구축 여정, Part 1: 구축 배경과 피처 서빙
해당 포스트는 당근의 김현호님, 서진형님, 권민재님과 함께 작성했으며, AWS 글로벌 블로그에 포스팅한 영문 블로그와 동일한 내용입니다. 당근은 대한민국을 대표하는 지역생활 커뮤니티로서, 동네에서 가능한 모든 연결에 중심을 둔 서비스입니다. 단순한 중고 거래를 넘어 이웃, 지역 가게, 공공 기관 간의 연결을 강화하고, 따뜻하고 활발한 동네를 만드는 것을 핵심 가치로 삼고 있습니다. 당근은 추천 시스템을 활용해 사용자에게 관심사와 […]

Vueron의 혁신적인 SaaS 전환기 – AWS SBT로 30일만에 이룬 성과
1. Vueron 소개 Vueron은 자율주행과 스마트 인프라를 위한 LiDAR 인지 소프트웨어와 AI 개발 플랫폼인 VueX 을 제공하는 기업입니다. Vueron은 북미, 아시아를 중심으로 다수의 글로벌 프로젝트를 수행해 왔으며, 정확성, 실시간성, 안전성을 핵심 가치로 삼아 OEM, Tier 1, 로보틱스, 스마트시티 분야 파트너들과 협력하고 있습니다. VueX는 데이터 수집부터 라벨링(가공), 학습, 검증, 배포 과정을 하나의 파이프라인으로 연결하여, 대규모 3D […]

Amazon S3 Vectors와 Amazon OpenSearch Service로 벡터 검색 최적화하기
본 게시글은 AWS Big Data Blog에 게시된 ‘Optimizing vector search using Amazon S3 Vectors and Amazon OpenSearch Service by Sohaib Katariwala, Bobby Mohammed, Sorabh Hamirwasia, Mark Twomey, and Pallavi Priyadarshini’을 한국어 번역 및 편집하였습니다. 참고: 본 블로그 내용은 7월 15일 기준으로, Amazon S3 Vectors와 Amazon OpenSearch Service의 통합 기능은 프리뷰 버전으로, 변경될 수 있습니다. 벡터 임베딩(Vector Embeddings)과 유사성 검색(Similarity […]

Dedicated Log Volumes를 사용한 Amazon RDS for PostgreSQL의 벤치마크
이 글은 AWS Database Blog에 게시된 “Benchmark Amazon RDS for PostgreSQL with Dedicated Log Volumes”을 한국어 번역 및 편집하였습니다. 오늘날의 데이터 중심 환경에서 조직들은 성능 저하 없이 까다로운 워크로드를 처리할 수 있는 미션 크리티컬 데이터베이스를 확보해야 합니다. Amazon Relational Database Service(Amazon RDS)는 이러한 요구사항을 충족하는 비용 효율적이고 안정적이며 확장성이 뛰어난 관리형 서비스입니다. PostgreSQL에서는 다른 많은 […]

Amazon Route 53 Resolver DNS Firewall로 하이브리드 워크로드 보호하기
본 게시물은 AWS Networking & Content Delivery Blog에 Yaniv Rozenboim님, Yossi Cohen님이 공저한 “Securing hybrid workloads using Amazon Route 53 Resolver DNS Firewall” 원문을 한국어로 번역 및 편집한 글입니다. 2021년 출시 이후, Amazon Route 53 Resolver DNS Firewall은 Amazon Web Services(AWS) 사용자가 Amazon Virtual Private Cloud(Amazon VPC) 리소스에서 발생하는 아웃바운드 DNS 쿼리를 모니터링하고 제어할 수 […]

.NET 앱 현대화를 위해 Visual Studio IDE에서 Amazon Q Developer를 이용한 에이전틱 코딩 경험 공유
많은 개발자들이 레거시 코드를 새로운 플랫폼 환경으로 이전하는 것을 꺼리는 데는 이유가 있습니다. 대부분의 개발자들도 동의하듯이, 코드를 작성하는 시간보다 기존 코드를 읽고 이해하는 시간이 더 많이 듭니다. 시간이 지나면 내가 작성한 코드조차 낯설게 보이는 것도 같은 맥락입니다. 결국, 과거의 코드를 이해하지 못한 채 (그것이 내가 작성했든 아니든) 해당 애플리케이션을 새로운 플랫폼으로 이전하는 것은 불가능합니다. 또한, […]