AWS 기술 블로그
Amazon EKS에서vLLM Deep Learning Container를 사용하여LLM 배포하기
“이 글은 AWS Architecture Blog에 게시된 ‘Deploy LLMs on Amazon EKS using vLLM Deep Learning Containers by Vishal Naik’ 를 한국어 번역 및 편집하였습니다”
조직들은 대규모 언어 모델(LLM)을 효율적으로 확장 배포할 때 상당한 어려움에 직면합니다. 주요 과제로는 GPU 리소스 활용 최적화, 네트워크 인프라 관리, 모델 가중치에 대한 효율적인 접근 제공 등이 있습니다. 분산 추론 워크로드를 실행할 때, 조직들은 종종 여러 노드에 걸친 모델 작업 오케스트레이션의 복잡성에 부딪힙니다. 일반적인 문제로는 사용 가능한 GPU에 모델 구성 요소를 효과적으로 분배하고, 처리 유닛 간의 원활한 통신을 조정하며, 낮은 지연 시간과 높은 처리량으로 일관된 성능을 유지하는 것이 포함됩니다.
vLLM은 빠른 LLM 추론 및 서빙을 위한 오픈 소스 라이브러리입니다. vLLM AWS 딥 러닝 컨테이너(DLC)는 Amazon Elastic Compute Cloud(Amazon EC2), Amazon Elastic Container Service(Amazon ECS) 및 Amazon Elastic Kubernetes Service(Amazon EKS)에서 vLLM을 배포하는 고객을 위해 최적화되었으며, 추가 비용 없이 제공됩니다. 이러한 컨테이너는 즉시 사용 가능한 사전 구성된 테스트 환경을 패키징하여, vLLM을 효율적으로 실행하는 데 필요한 드라이버 및 라이브러리와 같은 종속성을 포함하고, 고성능 다중 노드 추론 워크로드를 위한 Elastic Fabric Adapter(EFA)에 대한 기본 지원을 제공합니다. 더 이상 추론 환경을 처음부터 구축할 필요가 없습니다. 대신 vLLM DLC를 설치하면 자동으로 환경을 설정하고 구성하여 대규모 추론 워크로드를 바로 배포할 수 있습니다.
이 포스트에서는 Amazon EKS에서 vLLM용 AWS DLC를 사용하여 DeepSeek-R1-Distill-Qwen-32B 모델을 배포하는 방법을 보여주며, 이러한 목적에 맞게 구축된 컨테이너가 이 강력한 오픈 소스 추론 엔진의 배포를 어떻게 단순화하는지 보여줍니다. 이 솔루션은 성능과 비용 효율성을 유지하면서 LLM 배포의 복잡한 인프라 문제를 해결하는 데 도움이 될 수 있습니다.
AWS DLCs
AWS DLC는 생성형 AI 실무자들에게 Amazon EC2, Amazon EKS 및 Amazon ECS 전반에 걸쳐 파이프라인과 워크플로우에서 생성형 AI 모델을 훈련하고 배포할 수 있는 최적화된 Docker 환경을 제공합니다. AWS DLC는 자체적으로 AI/ML 환경을 구축하고 유지하기를 선호하며, 인프라에 대한 인스턴스 수준의 제어를 원하고, 자체 훈련 및 추론 워크로드를 관리하는 자체 관리형 머신 러닝(ML) 고객을 대상으로 합니다. DLC는 훈련 및 추론을 위한 Docker 이미지로 제공되며, PyTorch 및 TensorFlow와 함께 사용할 수 있습니다. DLC는 최신 버전의 프레임워크와 드라이버로 유지되고, 호환성 및 보안 테스트를 거치며, 추가 비용 없이 제공됩니다. 또한 레시피 가이드를 따라 빠르게 사용자 정의할 수 있습니다. 생성형 AI 환경의 구성 요소로 AWS DLC를 사용하면 운영 및 인프라 팀의 부담을 줄이고, AI/ML 인프라의 TCO를 낮추며, 생성형 AI 제품 개발을 가속화하고, 생성형 AI 팀이 조직의 데이터에서 생성형 AI 기반 인사이트를 도출하는 가치 있는 작업에 집중할 수 있도록 돕습니다.
솔루션 개요
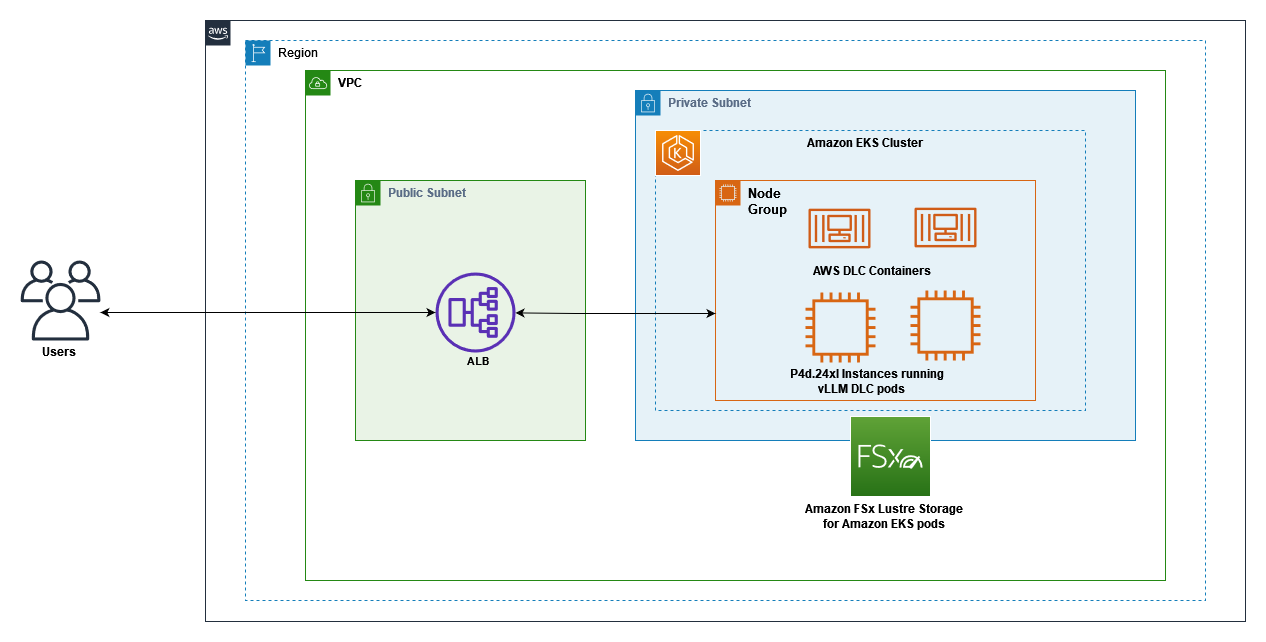
다음 다이어그램은 Amazon EKS, EFA 네트워킹을 갖춘 GPU 지원 EC2 인스턴스, 그리고 Amazon FSx for Lustre 스토리지 간의 상호작용을 보여줍니다. 클라이언트 요청은 애플리케이션 로드 밸런서(ALB)를 통해 EKS 노드에서 실행 중인 vLLM 서버 파드로 흐르며, 이 파드는 FSx for Lustre에 저장된 모델 가중치에 접근합니다. 이 아키텍처는 최적의 비용 효율성으로 LLM 추론 워크로드를 제공하기 위한 확장 가능한 고성능 솔루션을 제공합니다.
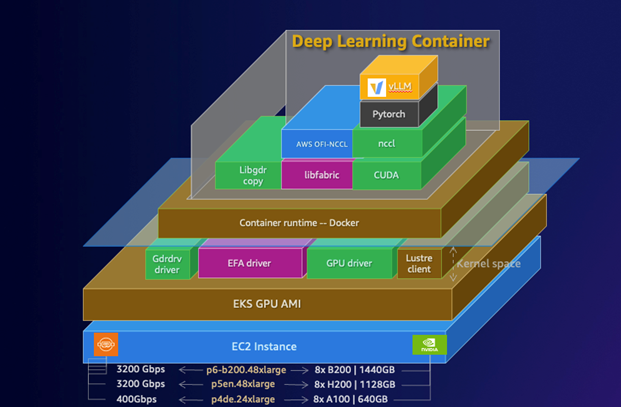
다음 다이어그램은 AWS에서의 DLC 스택을 보여줍니다. 이 스택은 EC2 인스턴스 기반부터 컨테이너 런타임, 필수 GPU 드라이버, PyTorch와 같은 ML 프레임워크에 이르는 종합적인 아키텍처를 보여줍니다. 계층화된 다이어그램은 CUDA, NCCL 및 기타 중요 구성 요소가 고성능 딥 러닝 워크로드를 지원하기 위해 어떻게 통합되는지 보여줍니다.
vLLM DLC는 여러 GPU와 노드에 걸친 텐서 병렬 처리 및 파이프라인 병렬 처리를 기본 지원하여 고성능 추론에 특별히 최적화되어 있습니다. 이러한 최적화를 통해 DeepSeek-R1-Distill-Qwen-32B와 같은 대규모 모델을 효율적으로 확장할 수 있으며, 이는 그렇지 않으면 배포 및 관리가 어려울 수 있습니다. 또한 이 컨테이너는 최적화된 CUDA 구성과 EFA 드라이버를 포함하여 분산 추론 워크로드의 최대 처리량을 촉진합니다. 이 솔루션은 다음 AWS 서비스 및 구성 요소를 사용합니다.
- vLLM용 AWS DLC – 배포를 단순화하고 성능을 최대화하는 사전 구성된 최적화된 Docker 이미지
- EKS 클러스터 – 컨테이너 오케스트레이션을 위한 Kubernetes 컨트롤 플레인 제공
- P4d.24xlarge 인스턴스 – 각각 8개의 NVIDIA A100 GPU를 갖춘 EC2 P4d 인스턴스로, 관리형 노드 그룹으로 구성
- Elastic Fabric Adapter – 고성능 컴퓨팅 애플리케이션이 효율적으로 확장할 수 있게 해주는 네트워크 인터페이스
- FSx for Lustre – 모델 가중치를 저장하기 위한 고성능 파일 시스템
- LeaderWorkerSet 패턴 – 분산 구성에서 vLLM을 배포하기 위한 커스텀 Kubernetes 리소스
- AWS Load Balancer Controller – 외부 접근을 위한 ALB 관리
이러한 구성 요소를 결합함으로써, 우리는 최소한의 운영 오버헤드로 낮은 지연 시간과 높은 처리량의 LLM 서빙 기능을 제공하는 추론 시스템을 만들 수 있습니다.
사전 준비 사항
시작하기 전에 다음과 같은 사전 준비 사항이 필요합니다.
- EC2 P4 인스턴스에 접근할 수 있는 AWS 계정 (필요한 경우 할당량 증가 요청이 필요할 수 있습니다)
- 다음 도구가 설치된 터미널에 대한 접근:
- 다음 권한을 가진 AWS Identity and Access Management(IAM) 역할 또는 사용자로 구성된 AWS CLI 프로필(vllm-profile):
- EKS 클러스터 및 노드 그룹 생성, 관리, 삭제 (자세한 내용은 AWS 클라우드에서 Kubernetes 클러스터 생성 참조)
- 가상 프라이빗 클라우드(VPC), 서브넷, 보안 그룹 및 인터넷 게이트웨이를 포함한 EC2 리소스 생성, 관리, 삭제 (자세한 내용은 Amazon EC2의 자격 증명 기반 정책 참조)
- IAM 역할 생성 및 관리 (자세한 내용은 자격 증명 기반 정책 및 리소스 기반 정책 참조)
- AWS CloudFormation 스택 생성, 업데이트 및 삭제
- FSx 파일 시스템 생성, 삭제 및 설명 (자세한 내용은 Amazon FSx for Lustre의 자격 증명 및 액세스 관리 참조)
- Elastic Load Balancer 생성 및 관리
이 솔루션은 Amazon EKS, P4d 인스턴스, FSx for Lustre를 사용할 수 있는 AWS 리전에 배포할 수 있습니다. 이 가이드에서는 us-west-2 리전을 사용합니다. 전체 배포 과정은 약 60~90분이 소요됩니다.
필요한 구성 파일이 포함된 GitHub 리포지토리를 복제합니다.
# Clone the repository
git clone https://github.com/aws-samples/sample-aws-deep-learning-containers.git
cd vllm-samples/deepseek/eksEKS 클러스터 생성
# Update the region in eks-cluster.yaml if needed
sed -i "s|region: us-east-1|region: us-west-2|g" eks-cluster.yaml
# Create the EKS cluster
eksctl create cluster -f eks-cluster.yaml --profile vllm-profile이 작업은 완료하는 데 약 15~20분이 소요됩니다. 이 시간 동안 eksctl은 다음 스크린샷과 같이 EKS 클러스터에 필요한 리소스를 프로비저닝하는 CloudFormation 스택을 생성합니다.
다음 코드로 클러스터 생성을 확인할 수 있습니다:
Amazon EKS 콘솔에서도 생성된 클러스터를 확인할 수 있습니다.
EFA 지원으로 노드 그룹 생성
다음으로, EFA가 활성화된 P4d.24xlarge 인스턴스로 관리형 노드 그룹을 생성합니다. 이러한 인스턴스는 각각 8개의 NVIDIA A100 GPU를 갖추고 있어 LLM 추론을 위한 상당한 계산 능력을 제공합니다. 고성능 ML 워크로드를 위해 p4d.24xlarge와 같은 EFA 지원 인스턴스를 배포할 때는 보안 및 최적화된 네트워킹을 용이하게 하기 위해 프라이빗 서브넷에 배치해야 합니다. 노드 그룹 구성에서 프라이빗 서브넷의 가용 영역을 동적으로 식별하고 사용함으로써, LLM을 사용한 분산 훈련 및 추론에 필수적인 고처리량, 저지연 통신을 지원하면서 적절한 네트워크 격리를 유지할 수 있습니다. 다음 코드를 사용하여 가용 영역을 식별합니다.
# Get the VPC ID from the EKS cluster
VPC_ID=$(aws --profile vllm-profile eks describe-cluster --name vllm-cluster \
--query "cluster.resourcesVpcConfig.vpcId" --output text)
# Find the one of private subnet's availability zone
PRIVATE_AZ=$(aws --profile vllm-profile ec2 describe-subnets \
--filters "Name=vpc-id,Values=$VPC_ID" "Name=map-public-ip-on-launch,Values=false" \
--query "Subnets[0].AvailabilityZone" --output text)
echo "Selected private subnet AZ: $PRIVATE_AZ"
# update the nodegroup_az section with the private AZ value
sed -i "s|availabilityZones: \[nodegroup_az\]|availabilityZones: \[\"$PRIVATE_AZ\"\]|g" large-model-nodegroup.yaml
# Verify the change
grep "availabilityZones" large-model-nodegroup.yaml
# Create the node group with EFA support
eksctl create nodegroup -f large-model-nodegroup.yaml --profile vllm-profile이 작업은 완료하는 데 약 10~15분이 소요됩니다. EFA 구성은 다중 노드 배포에 특히 중요한데, 이는 노드 간에 고처리량, 저지연 네트워킹을 가능하게 하기 때문입니다. 이는 서로 다른 노드의 GPU 간 통신이 병목 현상이 될 수 있는 분산 추론 워크로드에 중요합니다. 노드 그룹이 생성된 후, kubectl을 구성하여 클러스터에 연결합니다.
# Configure kubectl to connect to the cluster
aws eks update-kubeconfig --name vllm-cluster --region us-west-2 --profile vllm-profile노드가 준비되었는지 확인합니다.
# Check node status
kubectl get nodes다음은 예상되는 출력의 예시입니다.
NAME STATUS ROLES AGE VERSION
ip-192-168-xx-xx.us-west-2.compute.internal Ready <none> 5m v1.31.7-eks-xxxx
ip-192-168-yy-yy.us-west-2.compute.internal Ready <none> 5m v1.31.7-eks-xxxxAmazon EKS 콘솔에서도 생성된 노드 그룹을 확인할 수 있습니다.
NVIDIA 디바이스 파드 확인
GPU 지원을 제공하는 Amazon EKS 최적화 AMI(ami-0ad09867389dc17a1)를 사용하고 있기 때문에, NVIDIA 디바이스 플러그인이 이미 클러스터에 포함되어 있어 별도로 설치할 필요가 없습니다. NVIDIA 디바이스 플러그인이 실행 중인지 확인합니다.
# Check NVIDIA device plugin pods
kubectl get pods -n kube-system | grep nvidia다음은 예상되는 출력의 예시입니다.
nvidia-device-plugin-daemonset-xxxxx 1/1 Running 0 3m48s
nvidia-device-plugin-daemonset-yyyyy 1/1 Running 0 3m48s클러스터에서 GPU를 사용할 수 있는지 확인합니다.
# Check available GPUs
kubectl get nodes -o json | jq '.items[].status.capacity."nvidia.com/gpu"'다음은 예상되는 출력입니다.
"8"
"8"FSx for Lustre 파일 시스템 생성
최적의 성능을 위해, 모델 가중치를 저장할 FSx for Lustre 파일 시스템을 생성합니다. FSx for Lustre는 데이터에 대한 높은 처리량과 낮은 지연 시간의 접근을 제공하므로, 대규모 모델 가중치를 효율적으로 로드하는 데 필수적입니다. 다음 코드를 사용합니다:
# Create a security group for FSx Lustre
FSX_SG_ID=$(aws --profile vllm-profile ec2 create-security-group --group-name fsx-lustre-sg \
--description "Security group for FSx Lustre" \
--vpc-id $(aws --profile vllm-profile eks describe-cluster --name vllm-cluster \
--query "cluster.resourcesVpcConfig.vpcId" --output text) \
--query "GroupId" --output text)
echo "Created security group: $FSX_SG_ID"
# Add inbound rules for FSx Lustre
aws --profile vllm-profile ec2 authorize-security-group-ingress --group-id $FSX_SG_ID \
--protocol tcp --port 988-1023 \
--source-group $(aws --profile vllm-profile eks describe-cluster --name vllm-cluster \
--query "cluster.resourcesVpcConfig.clusterSecurityGroupId" --output text)
aws --profile vllm-profile ec2 authorize-security-group-ingress --group-id $FSX_SG_ID \
--protocol tcp --port 988-1023 \
--source-group $FSX_SG_ID
# Create the FSx Lustre filesystem
SUBNET_ID=$(aws --profile vllm-profile eks describe-cluster --name vllm-cluster \
--query "cluster.resourcesVpcConfig.subnetIds[0]" --output text)
echo "Using subnet: $SUBNET_ID"
FSX_ID=$(aws --profile vllm-profile fsx create-file-system --file-system-type LUSTRE \
--storage-capacity 1200 --subnet-ids $SUBNET_ID \
--security-group-ids $FSX_SG_ID --lustre-configuration DeploymentType=SCRATCH_2 \
--tags Key=Name,Value=vllm-model-storage \
--query "FileSystem.FileSystemId" --output text)
echo "Created FSx filesystem: $FSX_ID"
# Wait for the filesystem to be available (typically takes 5-10 minutes)
echo "Waiting for filesystem to become available..."
aws --profile vllm-profile fsx describe-file-systems --file-system-id $FSX_ID \
--query "FileSystems[0].Lifecycle" --output text
# You can run the above command periodically until it returns "AVAILABLE"
# Example: watch -n 30 "aws --profile vllm-profile fsx describe-file-systems --file-system-id $FSX_ID --query FileSystems[0].Lifecycle --output text"
# Get the DNS name and mount name
FSX_DNS=$(aws --profile vllm-profile fsx describe-file-systems --file-system-id $FSX_ID \
--query "FileSystems[0].DNSName" --output text)
FSX_MOUNT=$(aws --profile vllm-profile fsx describe-file-systems --file-system-id $FSX_ID \
--query "FileSystems[0].LustreConfiguration.MountName" --output text)
echo "FSx DNS: $FSX_DNS"
echo "FSx Mount Name: $FSX_MOUNT"파일 시스템은 1.2TB의 저장 용량, 고성능을 위한 SCRATCH_2 배포 유형, 그리고 EKS 노드에서의 접근을 허용하는 보안 그룹으로 구성됩니다. FSx for Lustre 콘솔에서도 FSx for Lustre 파일 시스템을 확인할 수 있습니다.

AWS FSx CSI 드라이버 설치
Kubernetes 파드에서 FSx for Lustre 파일 시스템을 마운트하기 위해 AWS FSx CSI 드라이버를 설치합니다. 이 드라이버를 통해 Kubernetes는 FSx for Lustre 볼륨을 동적으로 프로비저닝하고 마운트할 수 있습니다.
# Check AWS FSx CSI Driver pods
kubectl get pods -n kube-system | grep fsx다음은 예상되는 출력의 예시입니다.
fsx-csi-controller-xxxx 4/4 Running 0 24s
fsx-csi-controller-yyyy 4/4 Running 0 24s
fsx-csi-node-xxxx 3/3 Running 0 24s
fsx-csi-node-yyyy 3/3 Running 0 24sFSx for Lustre를 위한 Kubernetes 리소스 생성
FSx for Lustre 파일 시스템을 사용하기 위해 필요한 Kubernetes 리소스를 생성합니다.
# Update the storage class with your subnet and security group IDs
sed -i "s|<subnet-id>|$SUBNET_ID|g" fsx-storage-class.yaml
sed -i "s|<sg-id>|$FSX_SG_ID|g" fsx-storage-class.yaml
# Update the PV with your FSx Lustre details
sed -i "s|<fs-id>|$FSX_ID|g" fsx-lustre-pv.yaml
sed -i "s|<fs-id>.fsx.us-west-2.amazonaws.com|$FSX_DNS|g" fsx-lustre-pv.yaml
sed -i "s|<mount-name>|$FSX_MOUNT|g" fsx-lustre-pv.yaml
# Apply the Kubernetes resources
kubectl apply -f fsx-storage-class.yaml
kubectl apply -f fsx-lustre-pv.yaml
kubectl apply -f fsx-lustre-pvc.yaml리소스가 성공적으로 생성되었는지 확인합니다.
# Check storage class
kubectl get sc fsx-sc
# Check persistent volume
kubectl get pv fsx-lustre-pv
# Check persistent volume claim
kubectl get pvc fsx-lustre-pvc
다음은 예상되는 출력의 예시입니다:
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
fsx-sc fsx.csi.aws.com Retain Immediate false 1m
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
fsx-lustre-pv 1200Gi RWX Retain Bound default/fsx-lustre-pvc fsx-sc 1m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
fsx-lustre-pvc Bound fsx-lustre-pv 1200Gi RWX fsx-sc 1m이러한 리소스에는 다음이 포함됩니다.
- FSx for Lustre 볼륨을 프로비저닝하는 방법을 정의하는 StorageClass
- 기존 FSx for Lustre 파일 시스템을 나타내는 PersistentVolume
- 파드가 파일 시스템을 마운트하는 데 사용할 PersistentVolumeClaim
AWS Load Balancer Controller 설치
vLLM 서비스를 외부에 노출하기 위해 AWS Load Balancer Controller를 설치합니다. 이 컨트롤러는 Kubernetes 서비스와 인그레스를 위한 ALB를 관리합니다. 자세한 내용은 Helm을 사용한 AWS Load Balancer Controller 설치를 참조하세요.
# Download the IAM policy document
curl -o iam-policy.json https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/main/docs/install/iam_policy.json
# Create the IAM policy
aws --profile vllm-profile iam create-policy --policy-name AWSLoadBalancerControllerIAMPolicy --policy-document file://iam-policy.json
# Create an IAM OIDC provider for the cluster
eksctl utils associate-iam-oidc-provider --profile vllm-profile --region=us-west-2 --cluster=vllm-cluster --approve
# Create an IAM service account for the AWS Load Balancer Controller
ACCOUNT_ID=$(aws --profile vllm-profile sts get-caller-identity --query "Account" --output text)
eksctl create iamserviceaccount \
--profile vllm-profile \
--cluster=vllm-cluster \
--namespace=kube-system \
--name=aws-load-balancer-controller \
--attach-policy-arn=arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy \
--override-existing-serviceaccounts \
--approve
# Install the AWS Load Balancer Controller using Helm
helm repo add eks https://aws.github.io/eks-charts
helm repo update
# Install the CRDs
kubectl apply -f https://raw.githubusercontent.com/aws/eks-charts/master/stable/aws-load-balancer-controller/crds/crds.yaml
# Install the controller
helm install aws-load-balancer-controller eks/aws-load-balancer-controller \
-n kube-system \
--set clusterName=vllm-cluster \
--set serviceAccount.create=false \
--set serviceAccount.name=aws-load-balancer-controllerAWS Load Balancer Controller가 실행 중인지 확인합니다.
# Check AWS Load Balancer Controller pods
kubectl get pods -n kube-system | grep aws-load-balancer-controller
# Install the LeaderWorkerSet controller
helm install lws oci://registry.k8s.io/lws/charts/lws \
--version=0.6.1 \
--namespace lws-system \
--create-namespace \
--wait --timeout 300sALB용 보안 그룹 구성
ALB 전용 보안 그룹을 생성하고 클라이언트 IP 주소에서 포트 80으로의 인바운드 트래픽을 허용하도록 구성합니다. 또한 ALB 보안 그룹에서 vLLM 서비스 포트로 트래픽을 허용하도록 노드 보안 그룹을 구성합니다.
# Verify ALB security group
aws --profile vllm-profile ec2 describe-security-groups --group-ids $ALB_SG --query "SecurityGroups[0].IpPermissions"
The following is the expected output for the ALB security group:
[
{
"FromPort": 80,
"IpProtocol": "tcp",
"IpRanges": [
{
"CidrIp": "USER_IP/32"
}
],
"ToPort": 80
}
]
# Verify node security group rules
aws --profile vllm-profile ec2 describe-security-groups --group-ids $NODE_SG --query "SecurityGroups[0].IpPermissions"vLLM 서버 배포
마지막으로, LeaderWorkerSet 패턴을 사용하여 vLLM 서버를 배포합니다. AWS DLC는 일반적으로 LLM 배포와 관련된 복잡성을 최소화하는 최적화된 환경을 제공합니다. vLLM DLC는 다음과 같은 기능이 사전 구성되어 있습니다:
- 최대 GPU 활용을 위한 최적화된 CUDA 라이브러리
- 고속 노드 간 통신을 위한 EFA 드라이버 및 구성
- 분산 컴퓨팅을 위한 Ray 프레임워크 설정
- 텐서 및 파이프라인 병렬 처리를 지원하는 성능 조정된 vLLM 설치
이 미리 패키징된 솔루션은 배포 시간을 크게 단축하고, 복잡한 환경 설정, 종속성 관리, 그리고 전문 지식이 필요한 성능 튜닝의 필요성을 줄여줍니다.
# Deploy the vLLM server
# First, verify that the AWS Load Balancer Controller is running
kubectl get pods -n kube-system | grep aws-load-balancer-controller
# Wait until the controller is in Running state
# If it's not running, check the logs:
# kubectl logs -n kube-system deployment/aws-load-balancer-controller
# Apply the LeaderWorkerSet
kubectl apply -f vllm-deepseek-32b-lws.yaml배포는 즉시 시작되지만, 대용량 GPU 지원 컨테이너 이미지를 가져오는 동안 파드가 ContainerCreating 상태로 몇 분간(5-15분) 유지될 수 있습니다. 컨테이너가 시작된 후에는 DeepSeek 모델을 다운로드하고 로드하는 데 추가 시간(10-15분)이 소요됩니다. 다음 코드로 진행 상황을 모니터링할 수 있습니다.
# Monitor pod status
kubectl get pods
# Check pod logs
kubectl logs -f <pod-name>
Here is the out put of one of the pods
Kubectl logs -f vllm-deepseek-32b-lws-0 
파드가 실행 중일 때 예상되는 출력은 다음과 같습니다.
NAME READY STATUS RESTARTS AGE
vllm-deepseek-32b-lws-0 1/1 Running 0 10m
vllm-deepseek-32b-lws-0-1 1/1 Running 0 10m또한 ALB가 vLLM 서비스로 트래픽을 라우팅하도록 구성하는 인그레스 리소스를 배포합니다.
# Apply the ingress (only after the controller is running)
kubectl apply -f vllm-deepseek-32b-lws-ingress.yaml다음 코드로 인그레스 상태를 확인할 수 있습니다.
# Check ingress status
kubectl get ingress
다음은 예상되는 출력의 예시입니다.
NAME CLASS HOSTS ADDRESS PORTS AGE
vllm-deepseek-32b-lws-ingress alb * k8s-default-vllmdeep-xxxxxxxx-xxxxxxxxxx.us-west-2.elb.amazonaws.com 80 5m배포 테스트하기
배포가 완료되면 vLLM 서버를 테스트할 수 있습니다. 서버는 다음과 같은 API 엔드포인트를 제공합니다:
- /v1/completions – 텍스트 완성을 위한 엔드포인트
- /v1/chat/completions – 채팅 완성을 위한 엔드포인트
- /v1/embeddings – 임베딩 생성을 위한 엔드포인트
- /v1/models – 사용 가능한 모델 목록을 위한 엔드포인트
# Test the vLLM server
# Get the ALB endpoint
export VLLM_ENDPOINT=$(kubectl get ingress vllm-deepseek-32b-lws-ingress -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
echo "vLLM endpoint: $VLLM_ENDPOINT"
# Test the completions API
curl -X POST http://$VLLM_ENDPOINT/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"prompt": "Hello, how are you?",
"max_tokens": 100,
"temperature": 0.7
}'다음은 예상되는 출력의 예시입니다.
{
"id": "cmpl-xxxxxxxxxxxxxxxxxxxxxxxx",
"object": "text_completion",
"created": 1717000000,
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"choices": [
{
"index": 0,
"text": " I'm doing well, thank you for asking! How about you? Is there anything I can help you with today?",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 5,
"total_tokens": 105,
"completion_tokens": 100
}
}채팅 완성 API도 테스트할 수 있습니다.
# Test the chat completions API
curl -X POST http://$VLLM_ENDPOINT/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"messages": [{"role": "user", "content": "What are the benefits of using FSx Lustre with EKS?"}],
"max_tokens": 100,
"temperature": 0.7
}'
오류가 발생하면 vLLM 파드의 로그를 확인하세요.
# Troubleshooting
kubectl logs -f <pod-name>성능 고려 사항
Elastic Fabric Adapter
EFA는 분산 추론 워크로드에 상당한 성능 이점을 제공합니다.
- 지연 시간 감소 – 노드 간 GPU 통신에 대한 더 낮고 일관된 지연 시간
- 높은 처리량 – 노드 간 데이터 전송을 위한 더 높은 처리량
- 향상된 확장성 – 여러 노드에 걸쳐 더 나은 확장 효율성
- 더 나은 성능 – 분산 추론 워크로드에 대해 크게 향상된 성능
FSx for Lustre 통합
모델 저장소로 FSx for Lustre를 사용하면 다음과 같은 여러 이점이 있습니다.
- 영구 저장소 – 모델 가중치가 FSx for Lustre 파일 시스템에 저장되어 파드 재시작 시에도 유지됩니다
- 더 빠른 로딩 – 최초 다운로드 이후에는 모델 로딩이 훨씬 빠릅니다
- 공유 저장소 – 여러 파드가 동일한 모델 가중치에 접근할 수 있습니다
- 고성능 – FSx for Lustre는 모델 가중치에 대한 고처리량, 저지연 접근을 제공합니다
Application Load Balancer
AWS Load Balancer Controller와 ALB를 함께 사용하면 다음과 같은 여러 이점이 있습니다.
- 경로 기반 라우팅 – ALB는 URL 경로를 기반으로 다양한 서비스로 트래픽을 라우팅하는 것을 지원합니다
- SSL/TLS 종료 – ALB는 SSL/TLS 종료를 처리하여 파드의 부하를 줄일 수 있습니다
- 인증 – ALB는 Amazon Cognito 또는 OIDC를 통한 인증을 지원합니다
- AWS WAF – ALB는 추가 보안을 위해 AWS WAF와 통합될 수 있습니다
- 액세스 로그 – ALB는 감사 및 분석을 위해 Amazon Simple Storage Service(Amazon S3) 버킷에 요청을 로깅할 수 있습니다
정리
추가 요금이 발생하지 않도록 이 게시물에서 생성한 리소스를 정리하세요. 제공된 ./cleanup.sh 스크립트를 실행하여 Kubernetes 리소스(인그레스, LeaderworkerSet, PersistentVolumeClaim, PersistentVolume, AWS Load Balancer Controller, 스토리지 클래스), IAM 리소스, FSX for Lustre 파일 시스템 및 EKS 클러스터를 정리합니다:
CloudFormation 스택 삭제 실패 문제 해결을 포함한 더 자세한 정리 지침은 GitHub 리포지토리의 README.md 파일을 참조하세요.
결론
이 포스트에서는 GPU 지원, EFA, FSx for Lustre 통합과 함께 vLLM을 사용하여 Amazon EKS에서 DeepSeek-R1-Distill-Qwen-32B 모델을 배포하는 방법을 보여주었습니다. 이 아키텍처는 LLM 추론 워크로드를 제공하기 위한 확장 가능한 고성능 시스템을 제공합니다. vLLM용 AWS 딥 러닝 컨테이너는 환경 구성, 종속성 관리, 성능 튜닝의 복잡성을 최소화하여 LLM 배포를 단순화하는 간소화되고 최적화된 환경을 제공합니다. 이러한 사전 구성된 컨테이너를 사용함으로써, 조직은 배포 일정을 단축하고 LLM 애플리케이션에서 가치를 도출하는 데 집중할 수 있습니다. AWS DLC와 Amazon EKS, NVIDIA A100 GPU가 탑재된 P4d 인스턴스, EFA, 그리고 FSx for Lustre를 결합함으로써, Kubernetes의 유연성과 확장성을 유지하면서 LLM 추론을 위한 최적의 성능을 달성할 수 있습니다. 이 솔루션은 조직이 다음과 같은 일을 하는 데 도움이 됩니다.
- 대규모로 LLM을 효율적으로 배포
- 컨테이너 오케스트레이션으로 GPU 리소스 활용 최적화
- EFA로 노드 간 네트워킹 성능 향상
- 고성능 스토리지로 모델 로딩 가속화
- 확장 가능한 고성능 추론 API 제공
이 배포를 위한 전체 코드와 구성 파일은 GitHub 리포지토리에서 사용할 수 있습니다. 여러분이 직접 시도해보고 특정 사용 사례에 맞게 조정해 보시기를 권장합니다.