O blog da AWS
Usando o CRaC para reduzir os tempos de inicialização do Java no Amazon EKS
Por Islam Mahgoub, Raglin Anthony, Owen Hawkins e Sascha Moellering, Traduzido ao Português por Daniel Abib
A modernização de aplicativos é uma área de foco para organizações de diferentes tamanhos e setores atingirem objetivos de negócios, como redução do tempo de lançamento no mercado, maior eficiência de custos e melhor experiência do cliente. Os contêineres e as plataformas de orquestração de contêineres têm sido um dos principais facilitadores dessas iniciativas de modernização. Muitos clientes usam o Kubernetes como uma plataforma de orquestração de contêineres e usam o Amazon Elastic Kubernetes Service (Amazon EKS) para provisionar e gerenciar facilmente clusters de Kubernetes na nuvem da AWS e em datacenters locais.
Muitos dos aplicativos legados que estão sendo modernizados são escritos em Java. Além disso, Java é uma das linguagens de programação mais populares usadas para criar novos microsserviços utilizando estruturas como o Spring Boot. A criação de um novo contêiner baseado em Java às vezes sofre com o tempo de inicialização prolongado — o tempo necessário para iniciar o servidor de aplicativos subjacente e várias atividades de inicialização geralmente são os principais contribuintes para isso. O tempo de inicialização estendido significa menos capacidade de resposta para escalar eventos. Também afeta negativamente as atividades operacionais, como a reciclagem de nós de trabalhadores, em que vários contêineres são encerrados e reprogramados em novos nós de trabalho ao mesmo tempo e consomem recursos.
O Coordinated Restore at Checkpoint (CRaC) é um projeto OpenJDK que fornece um início rápido e desempenho imediato para aplicativos Java. Ele permite iniciar um aplicativo Java e uma JVM a partir de uma imagem em um formato aquecido. A imagem é criada a partir de um processo Java em execução em um momento arbitrário (“checkpoint”). O início da imagem (“restauração”) continua a partir do ponto em que o checkpoint foi feito. Inicialmente, a Azul iniciou o projeto OpenJDK CRaC e lançou um JDK com suporte para CRaC. Uma distribuição alternativa do OpenJDK com suporte ao CRaC é oferecida pela Bellsoft.
Neste artigo, demonstramos como o CRaC pode ser aproveitado em um pipeline de integração contínua (CI) criado usando o AWS CodePipeline e o AWS CodeBuild para criar uma imagem de contêiner aquecida do aplicativo. Em seguida, nós o implantamos no Amazon EKS. Fizemos algumas comparações para mostrar a melhoria no tempo de inicialização alcançada com o CRaC.
Você pode encontrar o código da implementação no GitHub.
Visão geral da solução
O diagrama a seguir mostra a arquitetura de um exemplo de implementação do CRaC. É composto pelos seguintes componentes:
- Um repositório Git que contém o código-fonte do aplicativo de exemplo. O AWS CodeCommit, um serviço de controle de fonte seguro, altamente escalável e totalmente gerenciado, é usado para hospedar o repositório.
- Um pipeline de CI que orquestra as várias atividades envolvidas no processo de criação. O CodePipeline, um serviço de entrega contínua totalmente gerenciado que automatiza os pipelines de lançamento, é usado para criar o pipeline de CI. O CodeBuild, um serviço de CI totalmente gerenciado que compila o código-fonte, executa testes e produz pacotes de software prontos para implantação, está executando as tarefas de construção e produzindo a imagem final do contêiner que é implantada no cluster EKS.
- Um registro de imagens de contêiner aonde a imagem do contêiner é armazenada e recuperada pelo runtime. Amazon Elastic Container Registry (Amazon ECR) — um registro de contêineres totalmente gerenciado que oferece hospedagem de alto desempenho é usado para armazenamento de imagens de contêineres.
- Um cluster Kubernetes em que a imagem do contêiner é implantada. O Amazon EKS, um serviço gerenciado do Kubernetes para executar o Kubernetes na nuvem da AWS e em datacenters locais, é usado para fornecer o cluster necessário.

Figura 1: Arquitetura da implementação do exemplo
O pipeline de CI é estendido para executar a nova versão do código, aquecê-la, capturar um checkpoint usando o CRaC e publicar a imagem com arquivos no checkpoint do CRaC no registro de contêineres (Amazon ECR). O aplicativo é iniciado no ambiente de destino, restaurando-o a partir dos arquivos do checkpoint, em vez de iniciá-lo do zero. Isso leva a uma redução significativa no tempo de inicialização e elimina o aumento no consumo de recursos computacionais que geralmente é observado durante o tempo de inicialização do aplicativo Java.
O fluxo de alto nível desta abordagem de captura instantânea que se aplica aos aplicativos Java em geral, está descrito neste artigo. No decorrer do post, documentamos uma abordagem específica do Spring Boot 3.2 e discutimos suas vantagens e desvantagens:
- Após a confirmação de uma nova versão do código, o pipeline de CI no CodePipeline verifica o código-fonte
- Uma compilação executada no CodeBuild é iniciada e executa o seguinte:
- Compila a nova versão do código que produz um arquivo JAR e cria uma imagem que contém o arquivo JAR
- Executa um contêiner a partir da imagem com o aplicativo em execução dentro
- Aquece o aplicativo enviando tráfego que simula o tráfego esperado no ambiente de destino e, em seguida, captura um checkpoint
- Cria uma imagem que contém o arquivo JAR e os arquivos de checkpoint CRaC
- Envia as imagens para o Amazon ECR
- Os manifestos K8s que implantam o aplicativo são aplicados aos clusters EKS que compõem o ambiente de destino. Para fins de comparação, duas implantações são criadas: uma que aponta para a imagem sem arquivos de checkpoint CRaC, onde o aplicativo é iniciado do zero, e outra que aponta para a imagem com arquivos de checkpoint CRaC, onde o aplicativo é iniciado, restaurando-o do checkpoint capturado.
Nosso aplicativo de exemplo é um serviço simples de Create Read Update Delete (CRUD) baseado em REST que implementa funcionalidades básicas de gerenciamento de clientes. Todos os dados são mantidos em uma tabela do Amazon DynamoDB acessada usando o AWS SDK para Java V2.
A funcionalidade REST está localizada na classe CustomerController, que usa a anotação Spring Boot RestController. Essa classe invoca o CustomerService, que usa a implementação do repositório de dados Spring, CustomerRepository. Esse repositório implementa as funcionalidades para acessar uma tabela do DynamoDB com o SDK para Java V2. Todas as informações relacionadas ao usuário são armazenadas em um Plain Old Java Object (POJO) chamado Customer.
Detalhes da implementação
Como já mencionado, usamos o CRaC para criar arquivos de checkpoint a fim de salvar o status de uma JVM “quente” na forma de arquivos. Esse estado pode ser restaurado lendo os arquivos do checkpoint, o que leva a uma melhoria significativa no desempenho da inicialização. Os arquivos do checkpoint podem ser salvos como uma camada adicional em uma imagem de contêiner. Também testamos outras opções, como salvar em um Amazon Elastic Filesystem (Amazon EFS) ou em um bucket do Amazon Simple Storage Service (Amazon S3).
A persistência do estado atual da JVM em um arquivo naturalmente tem certas implicações: por exemplo, ela pode conter segredos ou outros dados confidenciais. Se o aplicativo criar e manter manipuladores de arquivos ou conexões de rede, eles deverão ser fechados antes do checkpoint e restabelecidos após a restauração. O Spring Boot oferece suporte total a isso para as dependências contidas no Spring Boot. No entanto, se bibliotecas externas forem usadas, deve-se verificar se o suporte ao CRaC está implementado e, se não, uma lógica adicional deve ser escrita.
Em nosso exemplo, usamos o SDK para Java V2, que não tinha suporte para CRaC quando a publicação foi realizada. Portanto, a conexão com o DynamoDB deve ser reconstruída após o carregamento do snapshot. Os agentes Java, que são especificados na forma de parâmetros da JVM quando o aplicativo é iniciado, são um caso especial. Os agentes geralmente são usados para ferramentas de APM que instrumentam automaticamente o aplicativo e geram métricas. Eles também devem suportar o ciclo de vida do CRaC e implementar os ganchos de tempo de execução correspondentes.
O fluxo de alto nível descrito anteriormente é detalhado nas subseções a seguir.
Etapa 1 — Verificando a fonte
O ambiente de CI (neste caso, CodePipeline) é acionado por confirmações no repositório Git configurado (repositório CodeCommit neste exemplo de implementação). Ao ser acionado, o código-fonte é verificado e ele segue para a próxima etapa, que é a execução de um projeto do CodeBuild.
Etapa 2 — Construir
O projeto CodeBuild executa as seguintes etapas:
Etapa 2.a — Compilando o código-fonte e criando a imagem do contêiner
Um processo de criação de imagem de contêiner de vários estágios é usado para criar uma imagem de contêiner com o aplicativo JAR. Vamos examinar mais de perto o Dockerfile usado para criar a imagem do contêiner:
Usamos o OpenJDK 17 com o CRaC da Azul como imagem principal para a construção. Na primeira etapa, copiamos o arquivo pom do Maven e o código-fonte na imagem, instalamos o Maven usando o SDKMAN e iniciamos a compilação. Começamos o segundo estágio da compilação com a mesma imagem principal, instalamos alguns pacotes ausentes e copiamos os scripts necessários e o arquivo JAR que criamos no primeiro estágio de nossa compilação. Etapa 2.b — Executando o aplicativo dentro do ambiente de CI docker run é usado para executar o aplicativo no ambiente de CI. Os parâmetros de configuração são passados para o contêiner como variáveis de ambiente do sistema operacional por meio das opções —env/-e. Um sistema de arquivos disponível no ambiente de CI é montado no contêiner por meio das opções —volume/-v e disponibilizado para o processo Java executado dentro do contêiner para armazenar os arquivos do checkpoint e mantê-los além da vida útil do contêiner. Esse exemplo de implementação é baseado no OpenJDK 17 com CRaC da Azul, que usa o CRIU para verificar/restaurar processos Java. O CRIU precisa controlar o PID para verificação e restauração. Anteriormente, isso exigia o recurso CAP_SYS_ADMIN, mas não é uma prática recomendada executar aplicativos Java com as permissões elevadas. O recurso CAP_CHECKPOINT_RESTORE foi introduzido no Linux 5.9 para resolver esse problema. Os recursos do Linux CHECKPOINT_RESTORE (e o recurso SYS_PTRACE, que também é necessário para verificação e restauração) são concedidos por meio da opção --cap-add. Um exemplo de comando docker run é fornecido da seguinte forma:
Nota
Conforme mencionado anteriormente, o recurso do sistema CAP_CHECKPOINT_RESTORE foi introduzido no kernel Linux 5.9, enquanto as instâncias subjacentes do CodeBuild estão executando o kernel Linux 4.14. Portanto, tivemos que executar o docker no modo privilegiado dentro do CodeBuild para capturar o checkpoint.
Passo 2.c — Aquecendo o aplicativo e capturando o checkpoint
Como escrevemos o arquivo de snapshot em nosso exemplo? Depois de criar a imagem do contêiner, ela é iniciada pela primeira vez e (idealmente) o aplicativo é aquecido com uma carga de trabalho o mais próxima possível do uso produtivo. Só então a JVM fica “quente”. Depois disso, o arquivo de checkpoint é gravado com a ajuda do CRaC e do CRIU. A seção relevante do script bash que implementa essa funcionalidade pode ser vista a seguir. Essa é uma abordagem geral que funciona para todas as cargas de trabalho baseadas em JVM, independentemente da estrutura usada.
Esse script bash inicia o aplicativo, usa o siege para aquecê-lo e o jcmd para criar o arquivo de instantâneo.
Passo 2.d — Criando uma imagem de contêiner que contém o arquivo JAR e os arquivos de checkpoint CRaC
Agora, os arquivos do checkpoint estão em um sistema de arquivos no ambiente de CI. Uma nova imagem de contêiner é criada a partir da imagem de contêiner que contém o arquivo JAR do aplicativo no qual o arquivo de checkpoint foi adicionado como uma camada adicional.
Esse Dockerfile para criar a nova imagem de contêiner que contém os arquivos de checkpoint é mostrado a seguir. A imagem do contêiner produzida é usada para iniciar o aplicativo no ambiente de destino restaurando os arquivos do checkpoint.
Etapa 2.e — Enviando as imagens do contêiner para o Amazon ECR
O AWS CLI é usado para enviar as imagens de contêiner criadas para o Amazon ECR.
Etapa 3 — Aplicando manifestos K8s para implantar o aplicativo no Amazon EKS
Um ponto importante sobre a implantação no Amazon EKS são os recursos do Linux que precisam ser concedidos ao Pod em que o aplicativo Java é restaurado. Conforme mencionado anteriormente, os recursos CAP_CHECKPOINT_RESTORE e SYS_PTRACE são necessários. O trecho de YAML a seguir mostra como conceder esses recursos ao Pod (consulte o repositório do GitHub para ver os manifestos YAML completos para implantação no K8s):
Alterações no aplicativo para oferecer suporte ao CRaC
Nesta seção, discutimos as mudanças que precisam ser feitas no aplicativo para oferecer suporte ao CRaC.
Implementando o recurso CRaC
O CRaC exige que o aplicativo feche todos os arquivos abertos e conexões de rede antes que o checkpoint seja capturado. Além disso, talvez seja necessário atualizar as configurações após a restauração para atender às diferenças entre o ambiente em que o checkpoint é capturado e o ambiente em que ele é restaurado (como URL de conexão do banco de dados). Para facilitar isso, o CRaC fornece uma API que permite que as classes sejam notificadas quando um checkpoint estiver prestes a ser feito e quando uma restauração ocorrer. A API fornece uma interface, org.CRaC.Resource, que deve ser implementada para as classes que precisam ser notificadas. Há apenas dois métodos, beforeCheckpoint() e afterRestore(), que são usados como retornos de chamada pela JVM. Todos os recursos no aplicativo devem ser registrados na JVM, o que pode ser obtido obtendo um contexto CRaC e usando o método register(). Mais detalhes sobre isso podem ser encontrados na documentação da Azul.
O aplicativo de exemplo usado nessa implementação interage com o DynamoDB por meio do AWS SDK. Primeiro, um cliente é criado e, em seguida, esse cliente é usado para realizar operações em uma tabela do DynamoDB. Cada cliente mantém seu próprio pool de conexões HTTP. Para capturar o checkpoint, as conexões no pool (conexões de rede) precisam ser fechadas. Isso é feito fechando o cliente no método beforeCheckpoint() e recriando-o em afterRestore().
O trecho de código a seguir mostra como a classe CustomerRepository — que implementa o repositório de dados Spring e é responsável por criar, ler, atualizar e excluir dados do cliente em uma tabela do DynamoDB — é alterada para lidar com os requisitos do CRaC para conexões de rede por meio da interface org.CRaC.Resource:
Podemos ver aqui como implementamos os dois métodos beforeCheckpoint() e afterRestore() da interface Resource. Desenvolvedores com experiência atual no AWS Lambda SnapStart devem observar que esses ganchos de runtime também são usados para salvar e recarregar o estado. No nosso caso, fechamos a conexão com o DynamoDB e a restabelecemos.
Gerenciamento de configuração
Se o checkpoint for capturado em um ambiente (como um ambiente de CI) diferente daquele em que foi restaurado (como um ambiente de produção) e as configurações forem carregadas antes que o checkpoint seja capturado, as configurações precisarão ser atualizadas como parte da restauração do checkpoint para corresponder ao ambiente de destino.
Há vários mecanismos que podem ser usados para gerenciamento de configuração em Java, incluindo variáveis de ambiente do sistema operacional, parâmetros da linha de comando, propriedades do sistema Java e arquivos de configuração (como arquivos application.properties para aplicativos Spring). Os valores das variáveis de ambiente do sistema operacional em um aplicativo restaurado de um checkpoint são aqueles do ambiente em que o checkpoint é capturado. Portanto, as propriedades do sistema Java foram usadas para gerenciamento de configuração nessa implementação, em vez de variáveis de ambiente.
O Spring Framework fornece abstração de ambiente para facilitar o gerenciamento de configurações; e suporta vários mecanismos de gerenciamento de configuração. Isso inclui variáveis de ambiente do sistema operacional, propriedades do sistema Java e outros mecanismos.
Conforme descrito no trecho de código anterior, o método afterRestore() chama o método loadConfig(), que carrega as configurações das propriedades do sistema Java por meio do Environment Abstraction:
Se você estiver usando variáveis de ambiente do sistema operacional para gerenciamento de configuração e acessando-as por meio do Environment Abstraction, não precisará alterar o código para alternar para as propriedades do sistema Java. O Environment Abstraction suporta os dois mecanismos e dá precedência às propriedades do sistema Java sobre as variáveis de ambiente do sistema operacional. Consulte a documentação do Spring para obter mais detalhes.
A propriedade do sistema Java é definida no comando que executa o aplicativo com o valor que existe em uma variável de ambiente do sistema operacional:
O ambiente do sistema operacional é definido por meio do K8s Deployment e o valor é recuperado de um ConfigMap:
Gerenciamento de credenciais da AWS
Para que o aplicativo interaja com o DynamoDB, ele precisa das credenciais da AWS. No ambiente de CI (onde o checkpoint é capturado), uma função do AWS Identity and Access Management (IAM) é assumida e as credenciais temporárias são fornecidas ao aplicativo como propriedades do sistema Java. Portanto, o SystemPropertyCredentialsProvider é usado como provedor de credenciais. O ambiente de destino é baseado no Amazon EKS. Portanto, as funções do IAM para contas de serviço (IRSA) são usadas para interagir com a API da AWS. Isso requer o uso de WebIdentityTokenFileCredentialsProvider como provedor de credenciais.
O modo de parâmetro de configuração é usado para instruir o código sobre se deve usar SystemPropertyCredentialsProvider ou WebIdentityTokenFileCredentialsProvider.
Nota
Outra opção para resolver esse problema é usar DefaultCredentialsProvider. No ambiente de CI (onde o checkpoint é capturado), as credenciais são passadas como parâmetros do sistema Java; nesse caso, a cadeia de fornecedores de credenciais padrão usa SystemPropertyCredentialsProvider. No ambiente de destino (Amazon EKS), o token de identidade da web é injetado pelo Amazon EKS, então a cadeia de fornecedores de credenciais padrão usa WebIdentityTokenFileCredentialsProvider. O DefaultCredentialsProvider verifica as configurações e decide qual provedor usar no momento do carregamento da classe. Portanto, o checkpoint deve ser capturado antes disso para que essa opção funcione.
Alguns clientes preferem capturar o checkpoint no mesmo ambiente em que ele foi restaurado para evitar a complexidade envolvida na alteração das configurações e no tratamento das credenciais da AWS.
Suporte embutido Spring para CRaC
O Spring tem suporte embutido ao CRaC desde a versão 6.1 (e ao Spring Boot desde a versão 3.2), o que significa, entre outras coisas, que o CRaC está integrado ao Spring Lifecycle (mais informações sobre isso podem ser encontradas neste post do Spring Framework). Na documentação, você encontra a seguinte seção: “Quando a propriedade do sistema JVM -Dspring.context.checkpoint=onRefresh é definida, um checkpoint é criado automaticamente na inicialização durante a fase LifecycleProcessor.onRefresh. Após a conclusão dessa fase, todos os singletons inicializados sem lentidão foram instanciados e os retornos de chamada InitializingBean#afterPropertiesSet foram invocados; mas o ciclo de vida não foi iniciado e o ContextRefreshedEvent ainda não foi publicado. ”
Com essa abordagem, é possível capturar o código da estrutura, mas não o código do aplicativo. Além disso, não temos uma JVM totalmente aquecida que será capturada. Isso significa que o tempo de inicialização é maior em comparação com a abordagem geral.
O processo automático de captura instantânea é mais simples do que o manual. O processo Java é iniciado com os parâmetros correspondentes e, depois de concluído, é feita uma verificação para ver se os arquivos que armazenam o estado atual estão no sistema de arquivos.
Para restaurar o estado e executar nosso aplicativo, podemos simplesmente usar o seguinte:
Externalizando arquivos de checkpoint
Algumas organizações podem querer evitar manter arquivos de checkpoint na imagem do contêiner, e os motivos para isso incluem:
- Reduzindo o tamanho da imagem do contêiner
- Não alterar a natureza dos dados armazenados no Amazon ECR para conter dados de microsserviços na memória e evitar revisitar os controles de segurança configurados para eles
Para resolver essas preocupações, as seguintes mitigações podem ser consideradas:
-
- Armazenar os arquivos do checkpoint no Amazon EFS e montá-los no pod. Observamos que a restauração do processo Java de amostra leva dois segundos quando os arquivos do checkpoint são armazenados no Amazon EFS versus 0,3 segundos quando os arquivos do checkpoint fazem parte da imagem do contêiner.
- Armazenar os arquivos do checkpoint no Amazon S3 e sincronizar com o sistema de arquivos do pod no momento da inicialização. Observamos que as operações de sincronização levam seis segundos para arquivos de checkpoint de 170 MB nos nós de trabalho do m5.large (um endpoint público do S3 foi usado para esse teste).
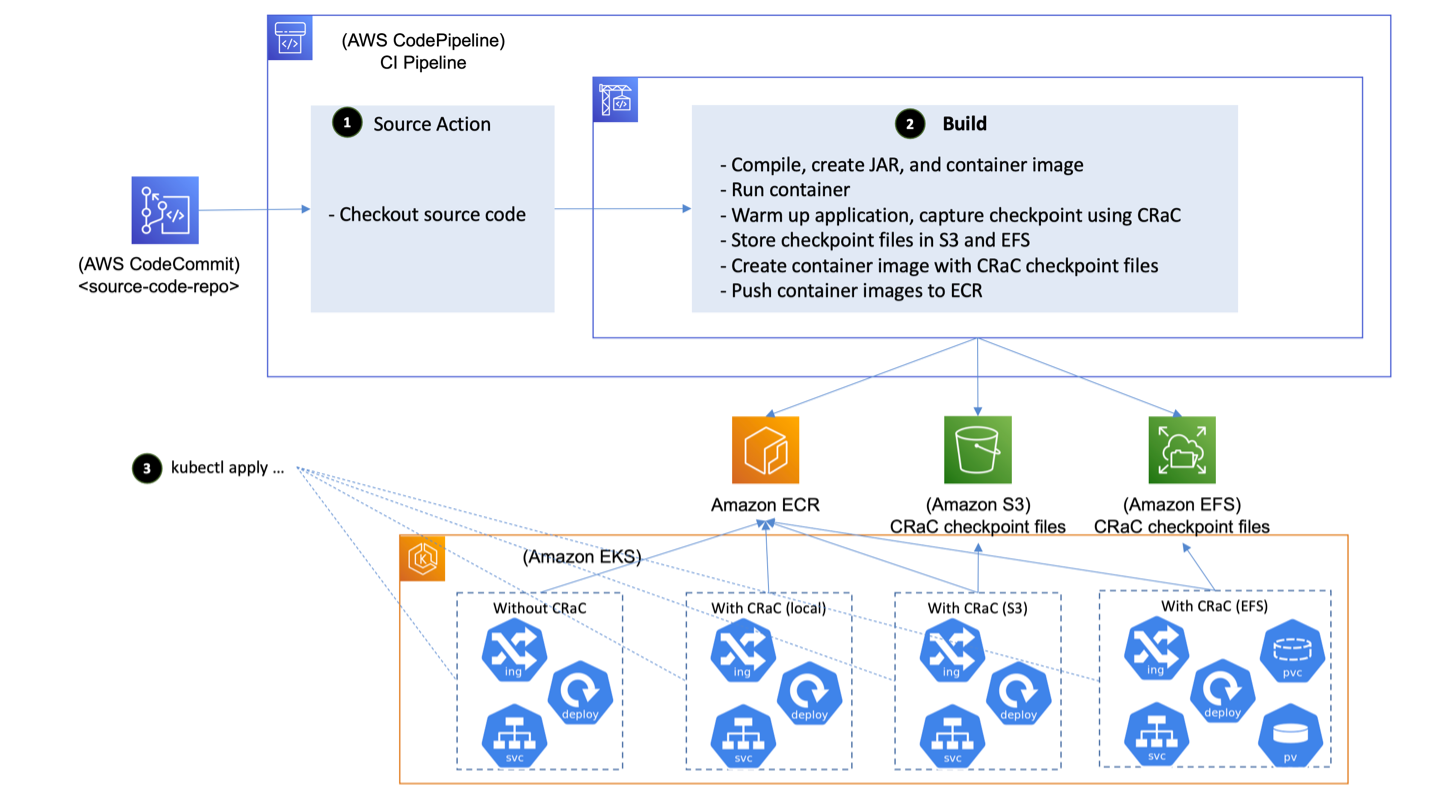
Figura 2: Exemplo de implementação com diferentes back-ends de armazenamento.
Pré-requisitos
Você precisará do seguinte para concluir as etapas desta postagem:
Uma instância do AWS Cloud 9 com os seguintes componentes instalados:
-
-
- Interface de linha de comando da AWS (AWS CLI) versão 2
- O AWS Cloud Development Kit (AWS CDK) versão 2.122.0 ou superior
- npm versão 10.3.0 ou superior
- kubectl versão 1.28
- git-remote-codecommit
-
Passo a passo
A primeira etapa é criar a infraestrutura usando um aplicativo de CDK da AWS. Todas as etapas necessárias para criar a infraestrutura e criar o aplicativo podem ser encontradas no repositório do GitHub.
Considerações sobre desempenho
Vamos investigar o impacto do uso do Azul JDK com suporte a CRaC em comparação com um OpenJDK padrão.
Medição e resultados
Testamos configurações diferentes para nossos testes de desempenho. Primeiro, testamos os seguintes cenários para a abordagem geral (o checkpoint é capturado após o aquecimento do aplicativo executando o comando jcmd):
-
-
- Imagem do contêiner sem CRaC
- Imagem do contêiner com CRaC, arquivo de checkpoint armazenado como uma camada adicional na imagem do contêiner
- Imagem de contêiner com CRaC, arquivo de checkpoint armazenado no Amazon EFS
- Imagem de contêiner com CRaC, arquivo de checkpoint armazenado no Amazon S3
-
Os resultados são os seguintes:
| Implantação | Tamanho dos arquivos do checkpoint (MB, não compactado) | Tamanho da imagem no Amazon ECR (MB) | Tempo para baixar os arquivos do Checkpoint (segundos) | Tempo de inicialização (segundos) | Tempo total de inicialização (segundos) |
| Sem CRaC | — | 349,97 | — | 12 | 12 |
| CRaC — Imagem do contêiner | 232 |
397,39 (contém arquivos CRaC) |
— | 0,3 | 0,3 |
| CRaC — EFS | 232 | 349,97 | — | 2 | 2 |
| CRaC — CLI do S3 | 232 |
463,38 (contém AWS CLI) |
6 | 0,3 | 6.3 |
Em segundo lugar, testamos os mesmos cenários, mas com o checkpoint capturado automaticamente por meio da integração CRaC integrada ao Spring (o checkpoint é capturado apenas para a estrutura, não para o aplicativo). Os resultados são os seguintes:
| Implantação | Tamanho dos arquivos do checkpoint (MB, não compactado) | Tamanho da imagem no Amazon ECR (MB) | Tempo para baixar os arquivos do Checkpoint (segundos) | Tempo de inicialização (segundos) | Tempo total de inicialização (segundos) |
| Sem CRaC | — | 354,3 | — | 19 | 19 |
| CRaC — Imagem do contêiner | 184 |
389,91 (contém arquivos CRaC) |
— | 2.5 | 2.5 |
| CRaC — EFS | 184 | 354,3 | — | 4.2 | 4.2 |
| CRaC — CLI do S3 | 184 |
467,71 (contém AWS CLI) |
7.5 | 2.5 | 10 |
Como pode ser visto, a configuração sem CRaC é a mais lenta. A variante mais rápida é aquela com CRaC (checkpoint após aquecimento usando o comando jcmd) e o armazenamento do checkpoint na imagem como uma camada adicional com 0,3 segundos. Essa é uma melhora impressionante de 97,5 por cento. Usar o checkpoint automático por meio da integração integrada do Spring com o CRaC é um pouco mais lento.
Compensações / Tocas / Tradeoffs
Conforme já indicado, o CRaC adiciona uma complexidade considerável ao processo de construção para capturar pontos de verificação. Além disso, ao pré-aquecer a JVM, deve-se tomar cuidado para garantir que uma grande proporção dos caminhos no código seja coberta para obter o melhor resultado possível. O CRaC ainda é uma tecnologia relativamente nova: no momento em que escrevo este post, apenas a distribuição OpenJDK da Azul e da Bellsoft suportava o CRaC. Além disso, existem muitas bibliotecas de terceiros que ainda não oferecem suporte ao CRaC. O mesmo se aplica aos agentes Java.
Um desafio adicional é o gerenciamento de configurações e o gerenciamento de credenciais da AWS. Conforme explicado anteriormente, se o checkpoint for capturado em um ambiente diferente do ambiente em que foi restaurado, talvez seja necessária alguma adaptação.
Outro desafio é que só é garantido que um checkpoint seja executado em uma CPU que tenha os recursos da CPU usada para capturar o checkpoint. Isso ocorre porque o CRaC não pode reconfigurar uma JVM já em execução para parar de usar alguns dos recursos da CPU ao ser restaurada em uma CPU sem esses recursos. É possível especificar um destino genérico de CPU usando -XX:CPUFeatures=generic para pontos de verificação. Isso significa que a JVM usa somente recursos de CPU que estão disponíveis em cada CPU x86-64. No entanto, isso pode ter impactos negativos no desempenho. Você pode encontrar mais informações sobre isso na documentação da Azul.
Limpando
Depois que você terminar, os seguintes recursos precisarão ser excluídos:
-
-
- os recursos K8s do aplicativo de exemplo implantados no cluster Amazon EKS e, em seguida, o próprio cluster Amazon EKS
- o pipeline de CI que cria as imagens do contêiner e captura/armazena o checkpoint (isso inclui o repositório Amazon ECR que armazena as imagens do contêiner)
- a instância do AWS Cloud9 se não for mais necessária
-
As instruções exatas de limpeza podem ser encontradas no repositório do GitHub.
Conclusão
Neste artigo, demonstramos o impacto do CRaC no tempo de inicialização de um aplicativo Spring Boot executado no Amazon EKS. Exatamente o mesmo padrão também pode ser usado para o Amazon ECS. Começamos com uma implementação típica de um aplicativo Spring Boot sem CRaC, adicionamos várias configurações para a localização do checkpoint e medimos o impacto. Em nossos testes de desempenho, descobrimos que a configuração com o arquivo de checkpoint armazenado como uma camada adicional na imagem do contêiner tem o maior impacto no desempenho de inicialização do aplicativo.
Esperamos ter lhe dado algumas ideias sobre como você pode otimizar seu aplicativo Java existente para reduzir o tempo de inicialização. Sinta-se à vontade para enviar aprimoramentos ao aplicativo de amostra no repositório de origem.
Este contéudo é uma tradução do blog original em inglês (link aqui).
Biografia dos autores
 |
Islam Mahgoub é arquiteto de soluções sênior na AWS com mais de 15 anos de experiência em aplicativos, integração e arquitetura de tecnologia. Na AWS, ele ajuda os clientes a criar novas soluções nativas em nuvem e a modernizar seus aplicativos legados aproveitando os serviços da AWS. Fora do trabalho, o Islam gosta de caminhar, assistir filmes e ouvir música. |
 |
Raglin Anthony é arquiteto de soluções baseado na AWS em Londres. Ele trabalha com clientes globais no setor de mídia e entretenimento e é apaixonado por criar experiências personalizadas para os clientes e impulsionar transformações digitais. A experiência de Raglin está em frameworks e microsserviços Java. |
 |
Owen Hawkins – Com mais de 20 anos de experiência em segurança da informação, Owen Hawkins traz profundo conhecimento para sua função como arquiteto de soluções sênior na AWS. Ele trabalha em estreita colaboração com clientes ISV, aproveitando sua vasta experiência em segurança bancária digital. Owen é especialista em SaaS e arquitetura multilocatário. Ele é apaixonado por permitir que as empresas adotem a nuvem com segurança. Resolver desafios complexos entusiasma Owen, que busca encontrar maneiras inovadoras de proteger e executar aplicações na AWS. |
 |
Sascha Möllering trabalha há mais de oito anos como arquiteto de soluções e gerente de arquiteto de soluções na Amazon Web Services EMEA, na filial alemã. Ele compartilha sua experiência com foco em Automação, Infraestrutura como Código, Computação Distribuída, Contêineres e JVM em contribuições regulares para diversas revistas e publicações de TI. Ele pode ser contatado em smoell@amazon.de. |
Biografia do tradutor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |