Amazon Redshift
Bestes Preis-Leistungs-Verhältnis für Cloud-Data-WarehousingWarum Amazon Redshift?
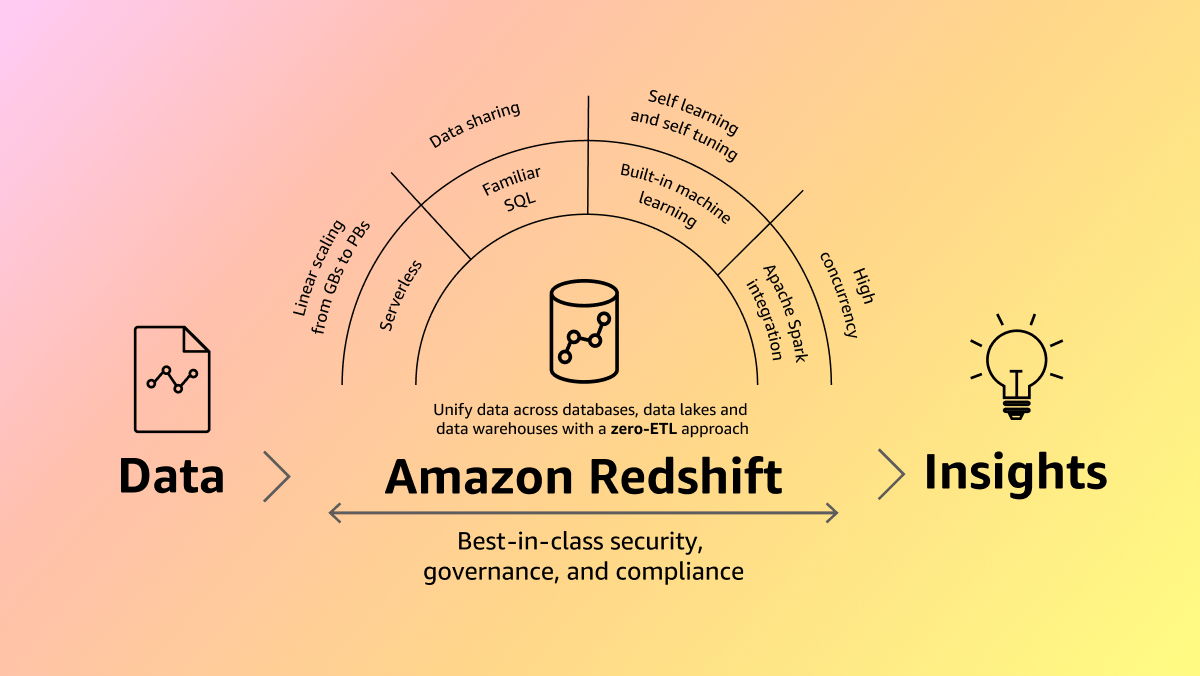
Zehntausende von Kunden nutzen Amazon Redshift täglich, um ihre Workloads für die Datenanalyse zu modernisieren und Einblicke in ihr Unternehmen zu gewinnen. Mit einer vollständig verwalteten, KI-gestützten, massiv-parallelen Verarbeitungsarchitektur (MPP) unterstützt Amazon Redshift die schnelle und kosteneffiziente Entscheidungsfindung in Unternehmen. Der Zero-ETL-Ansatz von AWS vereinheitlicht all Ihre Daten für leistungsstarke Analysen, echtzeitnahe Anwendungsfälle und KI/ML-Anwendungen. Teilen Sie Daten einfach und sicher innerhalb und zwischen Organisationen, AWS-Regionen und sogar externen Datenanbietern und arbeiten Sie mit ihnen zusammen, unterstützt durch führende Sicherheitsfunktionen und eine detaillierte Steuerung.
Vorteile
Funktionsweise
Anwendungsfälle
Amazon Redshift Serverless
In Sekundenschnelle Analysen durchführen und skalieren, ohne ein Data Warehouse bereitstellen und verwalten zu müssen