Amazon Redshift
データレイクハウスのために SQL を使用して比類のないコストパフォーマンスを大規模に実現
Amazon Redshiftを選ぶ理由
Amazon Redshift は最新のデータ分析を大規模に強化し、他のクラウドデータウェアハウスと比較して最大 3 倍の料金パフォーマンスと 7 倍多いスループットを提供します。Redshift Serverless は、データウェアハウスインフラストラクチャを管理することなく、分析ワークロードを簡単にスケールするのに役立ちます。ゼロ ETL 統合により、ストリーミングサービス、運用データベース、サードパーティーのエンタープライズアプリケーションからのデータを簡単に接続することで、ほぼリアルタイムの分析が可能になります。複雑なデータパイプラインは必要ありません。Amazon Q in Redshift は生産性を高め、自然言語を通じて SQL オーサリングを簡素化します。Amazon Bedrock の構造化ナレッジベースとして Redshift を利用することで、生成 AI アプリケーションからより正確な出力を得ることができます。Redshift は次世代の Amazon SageMaker とシームレスに統合するので、Amazon SageMaker Lakehouse 全体の統合データに対して、その強力な SQL 分析機能を活用できます。
メリット
-
Redshift でデータ分析ワークロードをスケールすると、他のクラウドデータウェアハウスと比較して、最大 3 倍のコストパフォーマンスと 7 倍のスループットを実現できます。組織全体でスケーラブルなマルチデータウェアハウスアーキテクチャを使用してワークロードを分離することで、コストを削減し、ビジネスに不可欠な SLA を満たすことができます。ネットワーク分離などの包括的なセキュリティ機能と、行レベルや列レベルの許可などのきめ細かなアクセスコントロールにより、追加コストなしでデータを保護できます。
Amazon SageMaker におけるシームレスな統合を通じて、統合されたすべてのデータにわたって Redshift の強力な SQL 分析機能を活用できます。Amazon S3 に保存されているオープンフォーマットのデータを高いパフォーマンスでクエリすることで、データレイクとデータウェアハウス間でデータを移動または複製する必要がなくなります。Redshift データを SageMaker Lakehouse の一部として簡単に組み込むことができるため、AWS や Apache Iceberg 互換の幅広い分析エンジンや機械学習ツールからアクセスできるようになります。
-
複雑なパイプラインを構築して管理しなくても、ペタバイト単位のデータを分析に利用可能にすることで、イノベーションを加速しましょう。これにより、分析のユースケースにほぼリアルタイムでアクセスできます。ゼロ ETL 統合を活用して、パフォーマンスに悪影響を及ぼすことなく、Amazon Aurora、RDS、DynamoDB などのデータベースから Redshift にトランザクションデータをシームレスに移動しましょう。ネイティブストリーミングサービスの統合により、Amazon Kinesis と Amazon MSK から大量のリアルタイムデータを取り込むことができます。すべてのデータを 1 か所に集めることで、ほぼリアルタイムの分析が可能になり、予測機械学習モデルを Redshift 内で直接構築して、強力なビジネスインサイトを得ることができます。
-
Amazon Redshift Serverless を使用すれば、数秒でデータの分析を開始できます。Redshift Serverless はワークロードから学習し、進化する分析ニーズに合わせてコンピューティングを自動的にスケールするため、インフラストラクチャを管理することなく、インサイトの発見に注力できます。必要なのは、データソースに接続してデータの分析を開始することだけです。インフラストラクチャの設定やメンテナンスは必要ありません。
-
Redshift と Amazon Bedrock のシームレスな統合を通じて、ペタバイト規模の組織データを使用してパーソナライズされたアプリケーションを構築できます。Redshift クエリエディタで Amazon Q 生成 SQL を使用して、データユーザーが自然言語で SQL クエリをより迅速かつ簡単に記述できるようにすることで、生産性を高めます。Amazon Bedrock と SageMaker の大規模言語モデルを呼び出して、テキスト要約、エンティティ抽出、感情分析などの高度な自然言語処理タスクを実行し、SQL を使用してデータに関するより深いインサイトを得ることができます。
2025 Gartner Critical Capabilities for Cloud Database Management Systems
AWS は、分析のすべてのユースケースで最高スコアを獲得したベンダー 2 社のうちの 1 社としてランクされています。
イベント分析で第 1 位
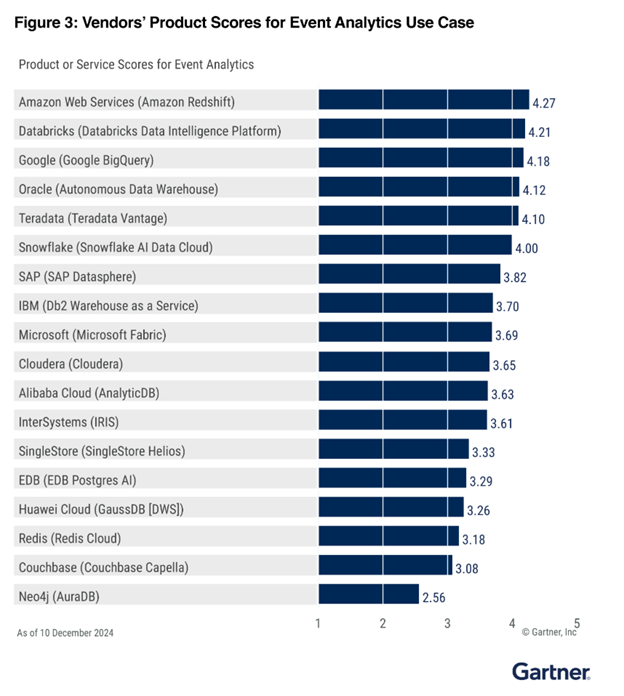
エンタープライズデータウェアハウスで第 2 位
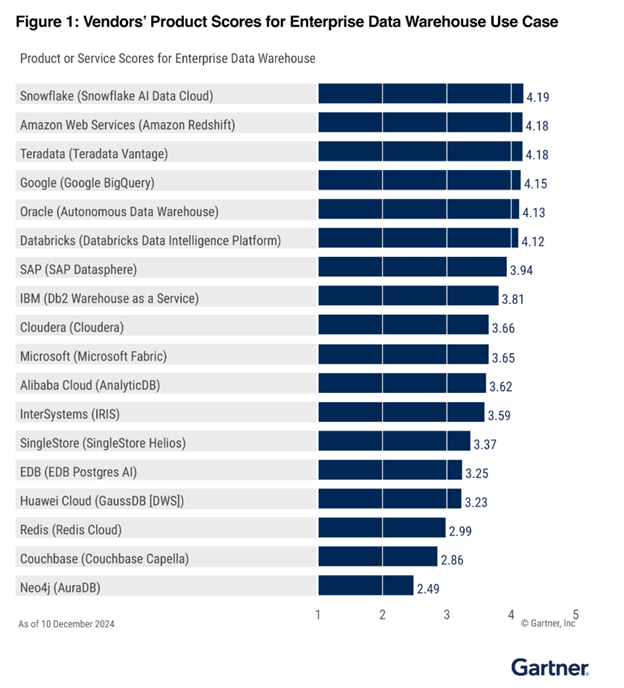
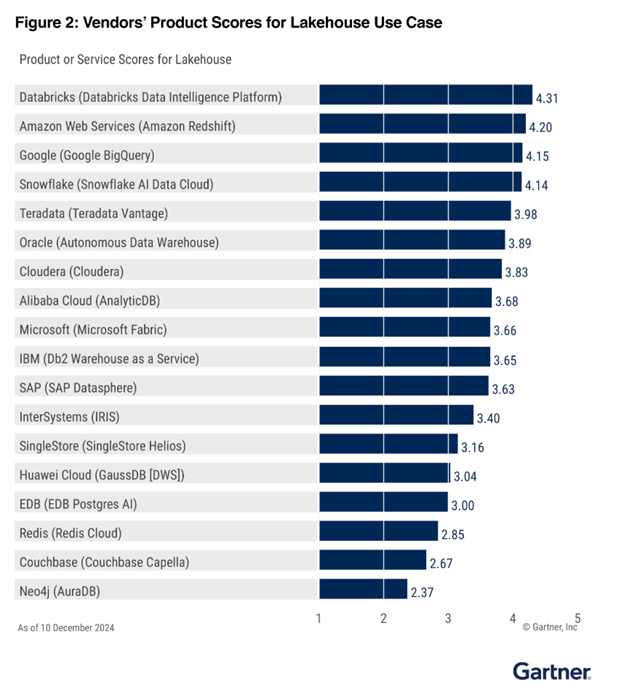
レイクハウスで第 2 位
免責事項
GARTNER は、Gartner, Inc. および/またはその関連会社の米国および国際的な登録商標およびサービスマークであり、ここでは許可を得て使用しています。All rights reserved.
Gartner は、リサーチの発行物に掲載されたベンダー、製品、またはサービスを推奨するものではありません。また、最高の評価または他の認定を得たベンダーのみを選定するよう、テクノロジーの利用者に助言するものでもありません。Gartner のリサーチの発行物は、同社のリサーチ組織の見解を表したものであり、事実の表明と解釈されるべきではありません。Gartner は、本リサーチに関して、商品性や特定目的適合性の保証を含め、明示または黙示を問わず、あらゆる保証を否認します。本図表は、Gartner, Inc. の発行物の一部であり、発行物全体の文脈で評価される必要があります。Gartner のドキュメントを入手するには、AWS にお問い合わせください。
ユースケース
1 秒あたり数百メガバイトのデータを取り込めるため、ほぼリアルタイムでデータをクエリし、不正検知、ライブリーダーボード、IoT のための低レイテンシー分析アプリケーションを構築できます。
Amazon Redshift や Amazon QuickSight、Tableau、Microsoft PowerBI などの B I を使用して、インサイト駆動型のレポートとダッシュボードを構築します。
SQL を使用して、予測分析、分類、リグレッションなど、さまざまなユースケース向けの機械学習モデルを構築、トレーニング、デプロイし、膨大なデータに対する高度な分析をサポートします。
データベース、データウェアハウス、データレイク間のすべてのデータに基づいてアプリケーションを構築します。シームレスかつ安全にデータの共有と共同作業を行い、顧客への価値を高め、データをサービスとして収益化し、新たな収益源を開拓できます。
市場データ、ソーシャルメディア分析、気象データなど、どのようなものであっても、AWS Data Exchange のサードパーティーデータと Amazon Redshift のデータをサブスクライブし、組み合わせることができます。ライセンスやオンボーディングプロセスに手間をかけたり、データをウェアハウスに移動したりする必要はありません。
Amazon Redshift Serverless
データウェアハウスをプロビジョニングおよび管理することなく、分析を数秒で簡単に実行およびスケーリングできます
今日お探しの情報は見つかりましたか?
ぜひご意見をお寄せください。ページのコンテンツ品質の向上のために役立てさせていただきます