



O que são dados sintéticos?
Dados sintéticos são dados não criados por humanos que imitam dados do mundo real. São criados por algoritmos e simulações de computação baseados em tecnologias de inteligência artificial generativa. Um conjunto de dados sintéticos tem as mesmas propriedades matemáticas dos dados reais nos quais ele se baseia, mas não contém as mesmas informações. As organizações usam dados sintéticos para pesquisas, testes, novos desenvolvimentos e pesquisas de machine learning. Inovações recentes em IA tornaram a geração de dados sintéticos eficiente e rápida, mas também aumentaram sua importância em questões regulatórias de dados.
Quais são os benefícios dos dados sintéticos?
Os dados sintéticos oferecem vários benefícios às organizações. Analisaremos alguns deles abaixo.
Geração de dados ilimitada
Você pode produzir dados sintéticos sob demanda e em uma escala quase ilimitada. As ferramentas de geração de dados sintéticos são uma forma econômica de obter mais dados. Eles também podem pré-rotular (categorizar ou marcar) os dados que geram para casos de uso de machine learning. Você tem acesso a dados estruturados e rotulados sem passar pelo processo de transformar dados brutos do zero. Você também pode adicionar dados sintéticos ao volume total de dados que você tem, gerando mais dados de treinamento para análise.
Proteção de privacidade
Áreas como saúde, finanças e setor jurídico têm muitos regulamentos de privacidade, direitos autorais e conformidade para proteger dados confidenciais. No entanto, eles devem usar dados para análise e pesquisa, muitas vezes tendo que terceirizar os dados para máxima utilização. Em vez de dados pessoais, eles podem usar dados sintéticos para servir à mesma finalidade desses conjuntos de dados privados. Eles criam dados semelhantes que mostram as mesmas informações estatisticamente relevantes sem expor dados privados ou confidenciais. Imagine a pesquisa médica criando dados sintéticos a partir de um conjunto de dados ao vivo: os dados sintéticos mantêm a mesma porcentagem de características biológicas e marcadores genéticos do conjunto de dados original, mas todos os nomes, endereços e outras informações pessoais do paciente são falsos.
Redução de viés
Você pode usar dados sintéticos para reduzir o viés nos modelos de treinamento de IA. Como modelos grandes geralmente se baseiam em dados disponíveis publicamente, pode haver enviesamento no texto. Os pesquisadores podem usar dados sintéticos para contrastar com qualquer linguagem ou informação tendenciosa que os modelos de IA coletam. Por exemplo, se determinado conteúdo baseado em opinião estiver favorecendo um grupo específico, você pode criar dados sintéticos para equilibrar o conjunto de dados geral.
Quais são os tipos de dados sintéticos?
Há dois tipos principais de dados sintéticos: parciais e completos.
Dados sintéticos parciais
Os dados parcialmente sintéticos substituem uma pequena parte de um conjunto de dados real por informações sintéticas. Você pode usá-lo para proteger partes confidenciais de um conjunto de dados. Por exemplo, se você precisar analisar dados específicos de clientes, poderá sintetizar atributos como nome, detalhes de contato e outras informações reais que alguém possa rastrear até uma pessoa específica.
Dados sintéticos completos
Dados sintéticos completos ocorrem quando você gera novos dados por completo. Um conjunto de dados completamente sintético não conterá dados reais. No entanto, ele usará os mesmos relacionamentos, distribuições de gráficos e propriedades estatísticas dos dados reais. Embora esses dados não venham de dados reais registrados, eles permitem que você tire as mesmas conclusões.
Você pode usar dados completamente sintéticos ao testar modelos de machine learning. É útil quando você deseja testar ou criar novos modelos, mas não tem dados de treinamento reais suficientes para melhorar a precisão do ML.
Como os dados sintéticos são gerados?
A geração de dados sintéticos envolve o uso de métodos computacionais e simulações para criar dados. O resultado imita as propriedades estatísticas dos dados do mundo real, mas não contém observações concretas do mundo real. Esses dados gerados podem assumir várias formas, incluindo texto, números, tabelas ou tipos mais complexos, como imagens e vídeos. Há três abordagens principais para gerar dados sintéticos, cada uma oferecendo diferentes níveis de precisão e tipos de dados.
Distribuição estatística
Nessa abordagem, os dados reais são primeiro analisados para identificar suas distribuições estatísticas subjacentes, como distribuições normais, exponenciais ou qui-quadradas. Os cientistas de dados então geram amostras sintéticas dessas distribuições identificadas para criar um conjunto de dados que se assemelha estatisticamente ao original.
Baseado em modelos
Nessa abordagem, um modelo de machine learning é treinado para entender e replicar as características dos dados reais. Depois que o modelo é treinado, ele pode gerar dados artificiais que seguem a mesma distribuição estatística dos dados reais. Essa abordagem é particularmente útil para criar conjuntos de dados híbridos, que combinam as propriedades estatísticas de dados reais com elementos sintéticos adicionais.
Métodos de aprendizado profundo
Técnicas avançadas como redes adversárias generativas (GANs), autocodificadores variacionais (VAEs) e outras podem ser empregadas para gerar dados sintéticos. Esses métodos geralmente são usados para tipos de dados mais complexos, como imagens ou dados de séries temporais, e podem produzir conjuntos de dados sintéticos de alta qualidade.
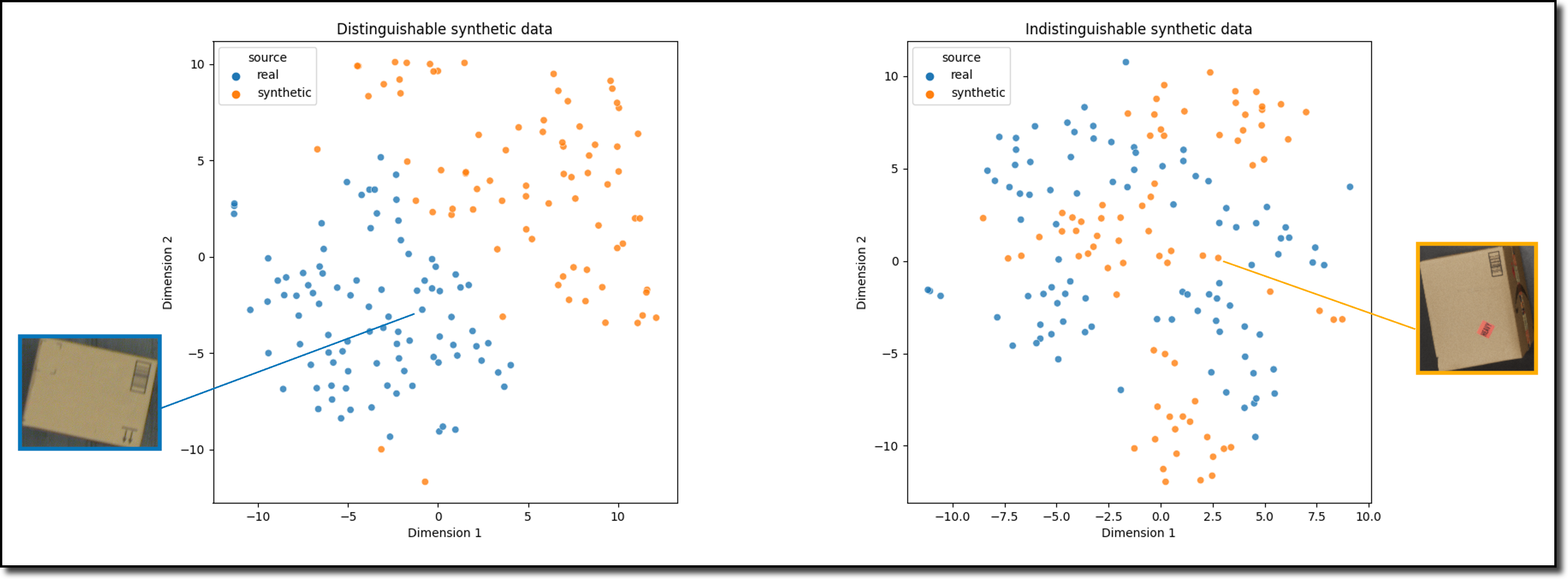
O que são tecnologias de geração de dados sintéticos?
Abaixo, descrevemos algumas tecnologias avançadas que você pode usar para geração de dados sintéticos.
Rede adversária generativa
Os modelos de rede adversária generativa (GAN) usam duas redes neurais que trabalham juntas para gerar e classificar novos dados. Uma usa dados brutos para produzir dados sintéticos, enquanto a segunda avalia, caracteriza e classifica essas informações. Ambas as redes competem entre si até que a rede avaliadora não consiga mais diferenciar os dados sintéticos dos dados originais.
Você pode usar a GAN para criar dados gerados artificialmente que sejam altamente naturalistas e apresentem variações de dados do mundo real, como vídeos e imagens com aparência realista.
Leia sobre redes adversárias generativas (GAN) »
Codificadores automáticos variacionais
Codificadores automáticos variacionais (VAE) são algoritmos que geram novos dados com base em representações de dados originais. O algoritmo não supervisionado aprende a distribuição dos dados brutos e, em seguida, usa a arquitetura codificador-decodificador para gerar novos dados por meio de uma transformação dupla. O codificador comprime os dados de entrada em uma representação de menor dimensão e o decodificador reconstrói novos dados a partir dessa representação latente. O modelo usa cálculos probabilísticos para recriações suaves.
O VAE é mais útil ao gerar dados sintéticos muito semelhantes com variações. Por exemplo, você pode usar o VAE ao gerar novas imagens.
Modelos baseados em transformadores
Transformadores generativos pré-treinados ou modelos baseados em GPT usam grandes conjuntos de dados originais para entender a estrutura e a distribuição típica dos dados. Você os usa principalmente na geração de processamento de linguagem natural (PLN). Por exemplo, se um modelo de texto baseado em transformador for treinado em um grande conjunto de dados de texto em inglês, ele aprenderá a estrutura, a gramática e até as nuances do idioma. Ao gerar dados sintéticos, o modelo começa com um texto inicial (ou prompt) e prevê a próxima palavra com base nas probabilidades aprendidas, gerando uma sequência completa.
Quais são os desafios na geração de dados sintéticos?
Há vários desafios ao criar dados sintéticos. Abaixo estão algumas limitações e desafios gerais que você provavelmente enfrentará com dados sintéticos.
Controle de qualidade
A qualidade dos dados é vital em estatísticas e análises. Antes de incorporar dados sintéticos em modelos de aprendizagem, você deve verificar se eles são precisos e têm um nível mínimo de qualidade de dados. No entanto, garantir que ninguém consiga rastrear pontos de dados sintéticos até informações reais pode exigir uma redução na precisão. Uma compensação na privacidade e na precisão pode afetar a qualidade.
Você pode realizar verificações manuais dos dados sintéticos antes de usá-los, o que pode ajudar a superar esse problema. No entanto, a verificação manual pode se tornar demorada se você precisar gerar muitos dados sintéticos.
Desafios técnicos
Criar dados sintéticos é difícil: você precisa entender as técnicas, as regras e os métodos atuais para garantir sua precisão e utilidade. Você precisa de um alto conhecimento nesse campo antes de gerar dados sintéticos úteis.
Não importa quanta experiência você tenha, gerar dados sintéticos como uma imitação perfeita de seus equivalentes do mundo real é um desafio. Por exemplo, dados do mundo real geralmente incluem discrepâncias e anomalias que os algoritmos de geração de dados sintéticos raramente conseguem recriar.
Confusão entre as partes interessadas
Embora os dados sintéticos sejam uma ferramenta complementar útil, nem todas as partes interessadas podem entender sua importância. Como uma tecnologia mais recente, alguns usuários corporativos podem não aceitar que a análise de dados sintéticos tenha relevância no mundo real. Por outro lado, outros podem enfatizar demais os resultados devido ao aspecto controlado da geração. Comunique os limites dessa tecnologia e seus resultados às partes interessadas, garantindo que elas entendam os benefícios e as deficiências.
Como a AWS pode oferecer suporte aos seus esforços de geração de dados sintéticos?
O Amazon SageMaker é um serviço totalmente gerenciado usado para preparar dados e criar, treinar e implantar modelos de machine learning (ML). Esses modelos são adequados para qualquer caso de uso com infraestrutura, ferramentas e fluxos de trabalho totalmente gerenciados. O SageMaker oferece duas opções que permitem rotular dados brutos, como imagens, arquivos de texto e vídeos, e gerar dados sintéticos rotulados para criar conjuntos de dados de alta qualidade para treinar modelos de ML.
- O Amazon SageMaker Ground Truth é uma oferta de autoatendimento que facilita a rotulagem de dados. Ele oferece a opção de usar anotadores humanos por meio do Amazon Mechanical Turk, fornecedores terceirizados ou seus próprios prestadores de serviços privados.
- O Amazon SageMaker Ground Truth Plus é um serviço totalmente gerenciado que permite criar conjuntos de dados de treinamento de alta qualidade. Você não precisa criar aplicações de rotulagem ou gerenciar a força de trabalho de rotulagem sozinho.
Primeiro, você especifica seus requisitos de imagem sintética ou fornece recursos 3D e imagens de referência, como imagens de desenho assistido por computador (CAD). Em seguida, os artistas digitais da AWS criam imagens do zero ou usam ativos fornecidos pelo cliente. As imagens geradas imitam a pose e o posicionamento de objetos, incluem variações de objetos ou cenas e, opcionalmente, adicionam inclusões específicas, como arranhões, amassados e outras alterações. Isso elimina o processo demorado de coleta de dados ou a necessidade de danificar peças para adquirir imagens. Você pode gerar centenas de milhares de imagens sintéticas que são rotuladas automaticamente com alta precisão.
Comece a usar a geração de dados sintéticos na AWS criando uma conta gratuita hoje mesmo.
Próximas etapas na AWS
Obtenha acesso instantâneo ao nível gratuito da AWS.