AWS Partner Network (APN) Blog
Leveraging MLOps on AWS to Accelerate Data Preparation and Feature Engineering for Production
By Sergio Zavota, MLOps Engineer – Data Reply
By Ajish Palakadan, Modern Data Platform Lead – Data Reply
By Salman Taherian, Partner AI/ML Specialist – AWS
By Mandeep Sehmi, Partner Solution Architect – AWS
 |
| Data Reply |
 |
Data scientists spend more than 50% of their time on data collection, preparation, and feature engineering tasks. Those activities are crucial to getting high-quality and performant models.
Specifically, feature engineering is a critical process in which data, produced by data engineers, are consumed and transformed by data scientists to train models and improve their performance.
This requires teams to collaborate closely and agree on:
- Data access policies: How data scientists access data produced by data engineers. Sensitive data must be restricted to be accessed only by the required people.
- Account strategy: Optimal set of environments and practices to implement a standardized process.
- Tools and technologies: Data engineers use different technologies from data scientists to perform data transformation processes. Data engineers use extract, transform, load (ETL)-oriented tools, while data scientists use machine learning (ML)-oriented tools.
- Ownership of the processes: Data engineers manage and execute different data transformation processes from data scientists. Data engineers develop and execute ETL processes, whereas data scientists develop and execute exploratory data analysis (EDA) and feature engineering processes.
In this post, you will learn how to accelerate data processing tasks and improve collaboration between data science and data engineering teams by applying MLOps best practices and leveraging different tools from Amazon Web Services (AWS). The solution is provided in a reference architecture that will reduce time-to-market.
Data Reply is part of the Reply Group, an AWS Premier Tier Services Partner with 13 AWS Competencies and 16 service specializations. Data Reply is focused on helping clients to deliver business value and differentiation through advanced analytics and AI/ML on AWS.
Data Reply is an AWS Marketplace Seller and one of the launch partners of the AWS MLOps Competency category in 2021. The Data Reply team leverages expertise in implementing MLOps best practices to help organizations standardize and automate feature engineering processes.
Overview
Data scientists often follow an unstructured workflow to perform feature engineering. This workflow can be further improved with:
- Automation: Feature engineering is often executed in a manual way (for example, executed in notebooks). Generating production features using this approach is error-prone and time-consuming.
- Traceability, reproducibility, and reusability: Code versions and metadata may not be tracked. As a consequence, it’s difficult to reuse and reproduce feature experiments executed at different points in time with different datasets.
- EDA-friendly tools: Before feature engineering, it’s essential to perform exploratory data analysis to assess the nature of data and understand how to process and select the best features. Interactive tools that help data scientists easily perform this operation can reduce the time spent on those activities.
In the first part of this post, we will apply MLOps best practices to define the key components a solution should include and the AWS services suited for each one of the components. In the second part, we describe how the solution can be implemented by using the MLOps maturity model.
Finally, we’ll describe a high-level workflow to showcase how data scientists and data engineers collaborate and implement a feature engineering process, and explore the benefits this solution provides.
Key Components
For an introduction to MLOps, please refer to Reply’s whitepaper: How MLOps helps operationalize machine learning models.
EDA and Feature Engineering Tools
The core of the solution is a tool or set of tools that allow experimenting with data and processing new features. Amazon SageMaker Data Wrangler can be used both in experimentation and production environments.
In the former, data scientists can use Amazon SageMaker Studio to access SageMaker Data Wrangler through the user interface (UI) and experiment with data. In the latter, it can be used to automate feature engineering processes through an automated pipeline.
Standardized Environments
There are several benefits to using different AWS accounts. Based on those benefits, we recommend having, at least, the following environments:
- Data management: Stores all of the ingested data from on-premises (or other systems) to the cloud. Data engineers are able to create ETL pipelines combining multiple data sources and prepare the necessary datasets for the ML use cases. In addition, features processed by data scientists can be stored in this account as well.
- Tooling: Stores code, CI/CD pipelines, model versions, metadata, artefacts, and images.
- Data science/development: Enables data scientists to conduct their research. The origin of the data snapshots is the data in the data management account. Here, experimentation is performed both with data and models.
The solution can be extended with more accounts, by defining additional steps in the CI/CD pipeline. As an example, some of the accounts that could be added/separated are:
- Separate data science account in experimentation and development.
- Add a pre-production account.
- Add a central data governance account to implement a data mesh pattern.
Storage
The data management account is the single point of truth. Here, data engineers process and maintain curated data and data scientists use them to process new features. It’s important to use the right technology for each use case.
Data engineers develop and execute ETL processes. A common pattern used in AWS is implementing a lake house architecture, using Amazon Simple Storage Service (Amazon S3) and Amazon Redshift as a storage layer.
Data scientists develop and execute feature engineering processes. While availability, reliability, and security must be always satisfied, there are additional requirements:
- Features need to be discoverable and reusable among different data science teams to avoid executing the same processes multiple times.
- For real-time specific use cases, features need to be retrieved with sub-second latency and served to ML models during the inference.
In those cases, a feature store is a good choice. Amazon SageMaker Feature Store can be used to fulfil this requirement.
Data Governance
Based on each ML use case, a specific dataset needs to be accessed by the team to create new features. The same logic applies to the features consumed by several other teams. A data governance strategy is crucial to managing access and permissions to different data for different users.
AWS Lake Formation provides self-service capabilities to govern data stored in the Amazon S3, Amazon Redshift, Amazon SageMaker Feature Store, and more.
IaC, CI/CD Pipelines, and Source Code Management
Lastly, infrastructure as code (IaC), CI/CD, and software configuration management (SCM) tools are recommended components to be included in the solution. They are established and mature best practices, widely known in the industry.
MLOps Maturity Model
Next, we’ll show several components of the architecture and how it can be implemented following the MLOps maturity model. This defines all of the necessary capabilities required to build an MLOps solution in four key phases: Initial, Repeatable, Reliable, and Scalable.
We scope the model down to the feature engineering process up to the Repeatable phase, which is the first target that needs to be achieved in order to achieve the benefits highlighted in this post.
Setting Up the Necessary Environments
In the initial phase, the goal is to create a secure experimentation environment where the data scientist receives snapshots of data in the data management account.
The entry point is SageMaker Studio, with tailored access to services via virtual private cloud (VPC) endpoints. Here, the data scientist can use SageMaker Data Wrangler, Feature Store, and notebooks in the data science account.
Every code artefact created or updated is stored and versioned in the Git repository, inside the tooling account.
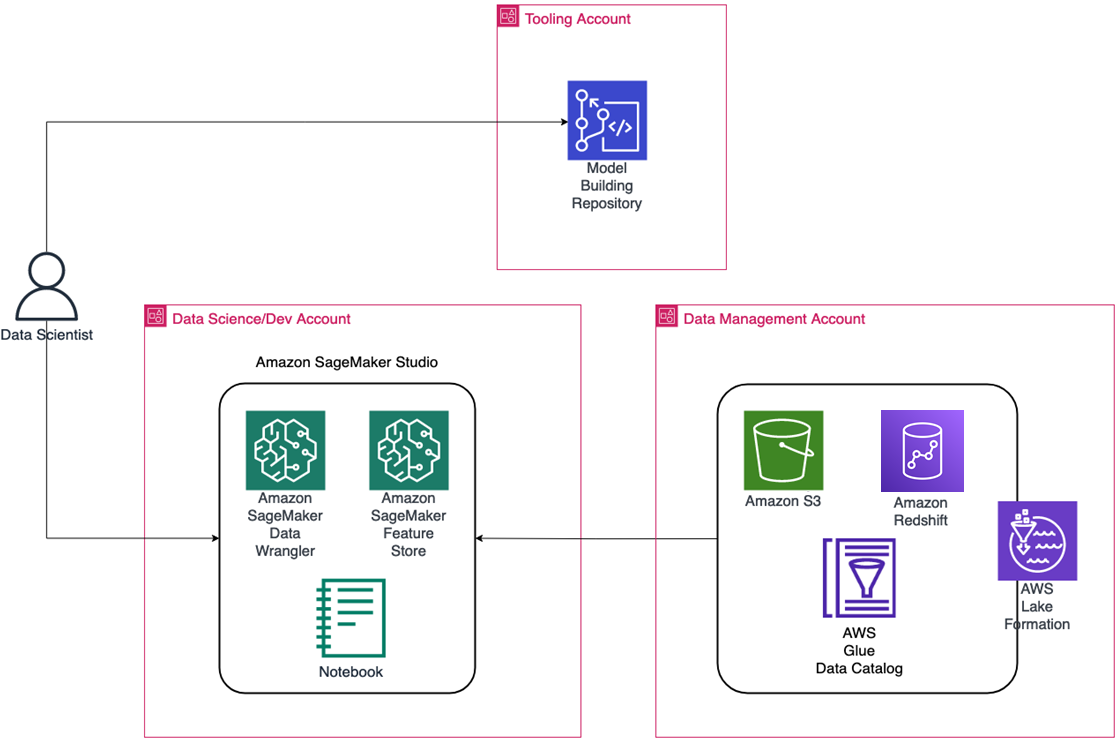
Figure 1 – Experimentation phase.
Enabling Automated Execution via AWS CodePipeline
The next step is to start productionizing the feature engineering process. After the experimentation is done through UI and notebooks, data scientists move to scripts that can be automated using orchestration tools.
It’s possible to export the Data Wrangler flow in a Python script or in a .flow file. Both can be automatically executed by a step through AWS CodePipeline, which is automatically triggered whenever changes are pushed to the feature branch of the Git repo.
This AWS blog post describes how to set up a multi-branching CodePipeline. In addition, we suggest setting up a SageMaker Studio in the data management account and granting feature store read-only access to data scientists to visualize the production processes.

Figure 2 – Repeatable phase.
Automated Triggering and Feature Engineering Processing
After the feature engineering process has been transformed into an automatable format and successfully tested, it has to be deployed into the data management account.
This operation is achieved by extending CodePipeline to deploy the code in production after a merge request—from the feature branch to the main branch—has been approved. The reviewers can be the lead data scientist and the lead data engineer.
This strategy promotes separation of concerns and gives independence to each team. Data scientists do not deploy directly in production, but the process is automated and reviewed by third parties.

Figure 3 – Repeatable phase with deployment in production.
High-Level Workflow
This section illustrates how a data scientist can use this solution to perform feature engineering. The architecture below includes a model training process to showcase how the created features can be used to train new models.

Figure 4 – End-to-end workflow.
- The data scientist extracts a feature branch from the main branch.
- Data scientist experiments with a snapshot of the data from the data management account that’s transferred to the data science/dev account for experimentation using SageMaker Studio.
- After experimentation, the data scientist creates scripts and pushes the changes into the repository.
- AWS CodePipeline is triggered and executes the Data Wrangler job in the data science account.
- New features are created in the Feature Store.
- Based on metrics decided by the data science team, if the outcome is successful the data scientist creates a pull request to merge the feature branch in the main branch.
- The lead data scientist and lead data engineer review the code.
- If everything is OK, the merge request is approved and the CodePipeline deploys the Data Wrangler job in the data management account.
- New features are created in the Feature Store.
- Data scientist writes a SageMaker pipeline and pushes the code into the repo.
- CodePipeline triggers the model training that uses the newly created features.
Data Mesh Extension
The proposed architecture can be easily extended to implement a data mesh pattern by creating a central data governance account. Refer to this AWS blog post for more details.
MLOps Customer Success Story
St. James’s Place (SJP), one of the UK’s largest, face-to-face advice-led wealth management companies, is developing an artificial intelligence (AI) and machine learning-based product to support its adviser community.
The company needed to have the confidence the ML core of the product was compliant with AWS best practices and ready to scale to thousands of users. Data Reply assessed the solution using its MLOps capabilities and provided support and guidance for the operationalization of 11 ML models.
As a result, SJP managed to scale the product to all the target users. The designed solution is expected to bring a 30% saving in AWS infrastructure costs for machine learning.
Conclusion
In this post, we combined MLOps best practices with the right AWS services to establish a standardized feature engineering process.
The following benefits are achieved:
- Improved data security and governance: Fine-grained access policies are applied to production data so only specific teams can access specific data.
- Flexibility and independence: Data scientists and data engineers are able to manage different processes and use different tools, without impacting each other.
- Collaboration: Data scientists and data engineers can efficiently collaborate through the adoption of a standardized process.
- Faster time-to-market: Feature engineering processes are executed smoothly and in less time, decreasing, in turn, model development and deployment time.
To get more value from your ML solution, contact Data Reply at info.data.uk@reply.com. You can also learn more about Data Reply in AWS Marketplace.
.

.
Data Reply – AWS Partner Spotlight
Data Reply is part of the Reply Group, an AWS Premier Tier Services Partner with 13 AWS Competencies and 16 service specializations. Data Reply is focused on helping clients to deliver business value and differentiation through advanced analytics and AI/ML on AWS.
Contact Data Reply | Partner Overview | AWS Marketplace | Case Studies