AWS Partner Network (APN) Blog
Turning Data into a Key Enterprise Asset with a Governed Data Lake on AWS
By Scott Gidley, VP of Product at Zaloni
 |
Data and analytics success relies on providing analysts and data end users with quick, easy access to accurate, quality data.
Enterprises need a high performing and cost-efficient data architecture that supports demand for data access, while providing the data governance and management capabilities required by IT.
Data management excellence, which is best achieved via a data lake on Amazon Web Services (AWS), captures and makes quality data available to analysts in a fast and cost-effective way.
Zaloni is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Data & Analytics Competency. In this post, I will share Zaloni’s experience and best practices for building a data lake on AWS, including:
- Why we chose AWS
- How we architect data lakes on AWS
- Best practices for a successful data lake:
- Connecting more data sources
- Cataloging for accurate, trusted data
- Governing data for security and traceability
- Providing business users with self-service access
Leveraging the Zaloni Data Platform (ZDP), our data management, governance, and self-service software solution, we worked with TMX Group to build a data lake on AWS.
This served as the foundation for a wide array of new and future use cases, such as data monetization and market insights, and helped the company transform data into a key enterprise asset.
Building a Governed Data Lake on AWS
TMX Group is a Canadian financial services company that operates equities, fixed income, derivatives, and energy markets exchanges. They wanted to make data available to analysts and business users to serve use cases, such as monetizing data for revenue growth and providing 360-degree customer views to improve customer experience and uncover cross-sell and up-sell opportunities.
TMX group had a complex data environment with data sprawled across the organization. Facing challenges connecting and integrating their siloed data sources, TMX Group wanted to centralize, augment, and enrich data sets. TMX also wanted to provide enriched, trusted data to lines of business in a way that was governed and traceable through a self-service data catalog.
This would allow the company to provide broader on-demand accessibility, while ensuring data privacy and security to meet IT and industry regulations.
Enterprise-Wide Data Governance Through a Unified Data Platform
We helped TMX Group build an enterprise-wide data lake on AWS using the Zaloni Data Platform (ZDP), which provides centralized management, governance, and a self-service data catalog to accelerate data and reduce time to insight.
Instead of purchasing and integrating several products, TMX Group selected our platform because it provided the capabilities needed to build and manage their enterprise data lake on AWS through a single unified platform.
ZDP connects to any data source whether it’s on-premises or in the cloud, and ingests a variety of data types into the data lake. The data is cataloged and metadata is captured. Data is then profiled and classified to help automate the process of identifying sensitive or potentially not useful data.
At this point in the process, additional business and technical metadata may be added to enhance the catalog. Data can continue to be enriched or improved via data quality and data transformations as part of the data management phase.
Finally, data is available for consumption in ZDP through the data catalog, making it easy for analysts and end users to quickly find trusted data and provision that data to an analytics tool, business intelligence application, cloud data warehouse, or other destination.
For TMX Group, we used ZDP to accelerate the delivery of trusted, high value data and made it easy to share and use that data across the enterprise.

Figure 1 – Zaloni Data Platform (ZDP).
Why We Chose AWS
We recommended TMX Group use the AWS platform for their cloud-based data lake deployment because ZDP easily leverages native AWS components, including Amazon EMR, Amazon Simple Storage Solution (Amazon S3), and Amazon Elastic Compute Cloud (Amazon EC2) virtual servers.
In the AWS data lake, ZDP orchestrates data movement between the AWS storage, processing, and serving layers. It creates a single platform to handle the day-to-day data management and operations so there is a clear record of what’s in the data lake. As a result, there’s no need to look across multiple tools to find where data came from.
AWS provides seamless integration with the corporate Active Directory for access control, makes it easy to check cluster and instance health, and provides tools for data lifecycle management and tracking operational metrics.
In addition, the transient nature of Amazon EMR is hugely appealing, allowing our customers to use ZDP to automate the spin up and termination of clusters on demand, as data comes in, to control costs.
AWS-Based Data Architecture
For TMX Group, 10 years’ worth of daily trading data history needed to be ingested from cold storage into AWS. The volume of historical data was massive and in a variety of proprietary formats from various sources, all with different schemas.
In addition to historical data, batch data from trade activity on the stock exchange had to be ingested at the end of each day. ZDP was able to ingest, catalog, and standardize all of the metadata so the data could be quality checked and enriched to make it more meaningful in the data lake.
To do this, ZDP built data pipelines and created a zone-based data lake architecture on AWS, where each data lake zone had different security and access privileges, as you can see in Figure 2 below.
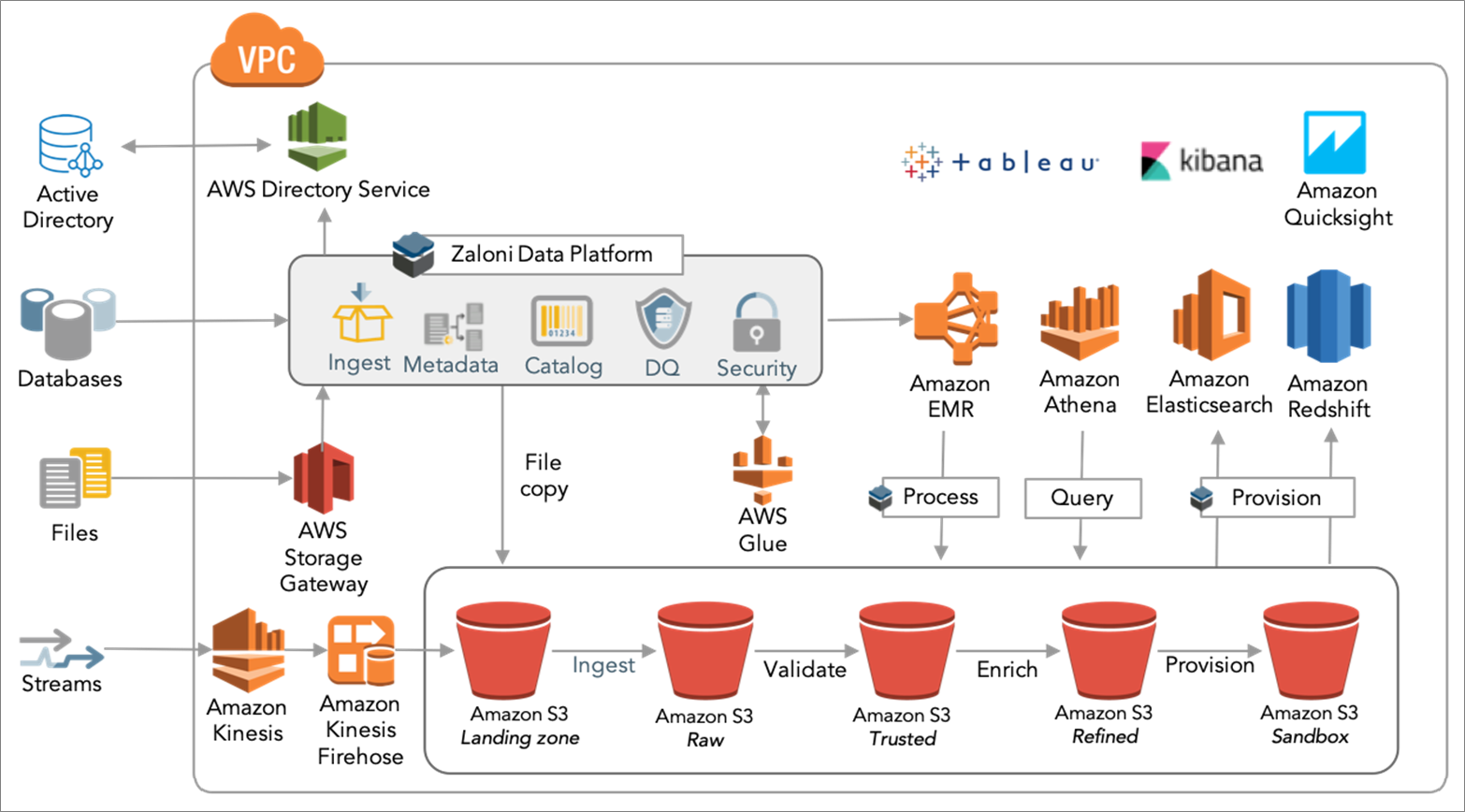
Figure 2 – Solution architecture for an Amazon S3 data lake.
This architecture enabled us to clearly track where data was coming from and where it was going. We could also automate where data resided, for how long, and implement data governance, lifecycle, and data quality policies that allowed controlled access to data, and for data to automatically move between the data lake zones.
The different data lake zones included in the solution architecture:
- Transient landing zone: This landing zone is a temporary store were data first lands and basic quality checks can be performed. It’s commonly used in highly-regulated industries where data, such as personally identifiable information (PII), must be masked or encrypted prior to being stored to prevent data from being compromised.
. - Raw zone: Once initial quality checks are conducted in the transient zone, data can be moved into the raw zone, where it’s stored permanently. Here, data is stored in its raw or original format and is known as the “single source of truth.”
. - Trusted zone: Data is imported from the raw zone into the trusted zone, where it can be transformed to meet all required governance policies. Data cleansing and validation is typically performed in this zone. Data here is considered the “single version of truth.”
. - Refined zone: Data moves from the trusted zone to the refined zone to be integrated into a common format so it can be easily consumed by data end users for creating analytic models. This is the last stage where data is processed before it’s used for analytics and typically requires role-based access.
. - Sandbox: This is where data scientists and analysts can perform ad hoc data exploration, analysis, and testing. The sandbox allows end users to conduct analysis and testing in a built environment, reducing reliance on the IT department. Insights found here can be provisioned back to the raw zone, allowing derived data to be treated as a new data source.
Best Practices for a Successful Data Lake Deployment
At Zaloni, we understand there are four key areas that will make your data lake successful now and in the future.
1. Connect More Data From More Sources
A key feature of a flexible data lake architecture is being able to connect to a variety of new and existing data sources, and easily adding these sources to the catalog as they become available.
ZDP can ingest or connect to data from various sources, including from on-premises relational databases, third parties, and other data in the cloud.
You can see in Figure 3 below how ZDP catalogs all sources for a single-view perspective. It also automates ingestion and captures operational, technical, and business metadata to organize the data lake.

Figure 3 – View of ZDP’s data catalog search results.
To hydrate the data lake built on AWS, if the data is coming in the form of files, you can register your remote ingestion landing zones within ZDP, and its microservices will be monitoring for the arrival of specific files by matching name-patterns within these Amazon EC2 instances.
If the need is to bring in data directly from relational database management systems (RDBM), it can be done by leveraging Sqoop inside Amazon EMR and by pulling this data in a highly distributed manner.
As the data comes in, ZDP will ensure it’s placed in the right Amazon S3 zone for the rest of the post-ingestion processing to take place. A similar action is performed for streaming ingestion as well, where instead of Sqoop an AWS native service like Amazon Kinesis or Amazon MSK is used.
2. Catalog Data for Accurate, Trusted, and Repeatable Use
A data catalog is an inventory of an organization’s data assets that provides context through description and organization so that users, data scientists, and data analysts can understand and discover the datasets they need.
A big advantage of ZDP’s catalog for IT teams is the platform’s focus on automation and operationalization. For example, ZDP facilitates reuse and consolidation of metadata from enterprise definitions and standards from all types of applications, including other catalogs, data governance and metadata applications, as well as traditional data sources.
Ingesting data into the data lake historically has been a complex process requiring multiple tools and technologies. ZDP simplifies ingestion by providing a self-service ingestion wizard and templates that help drive consistency for end users.
These tools automate and make repeatable many of the post-ingestion tasks required to make newly ingested data available to data consumers as a trusted asset.

Figure 4 – ZDP’s ingest wizard makes it easy to quickly add new data sets.
For a data lake on AWS, if AWS Glue is being used, ZDP can include any data collected within AWS Glue and augment its own business, technical, and operational metadata with any additional information it’s able to gather from AWS Glue. This particularly helps if ZDP is being used as an enterprise data catalog.
3. Govern Data for Security and Traceability
Data governance to enable role-based access control is critical for compliance with industry regulations around privacy and security.
This ability is particularly critical in highly-regulated industries like financial, healthcare, and telecom services. ZDP leverages metadata management for governance so that enterprises can track data lineage and quality throughout the data lifecycle.
In a governed data lake, the data can reside in a zone-based Amazon S3 storage, but Amazon EMR serves as the compute layer for all processing needs.
ZDP leverages both Amazon EMR and AWS Glue for performing any extract, load, transform (ELT) processes on this data and its end-to-end lineage gets captured for auditing. The finalized data can be queried using Amazon Athena.
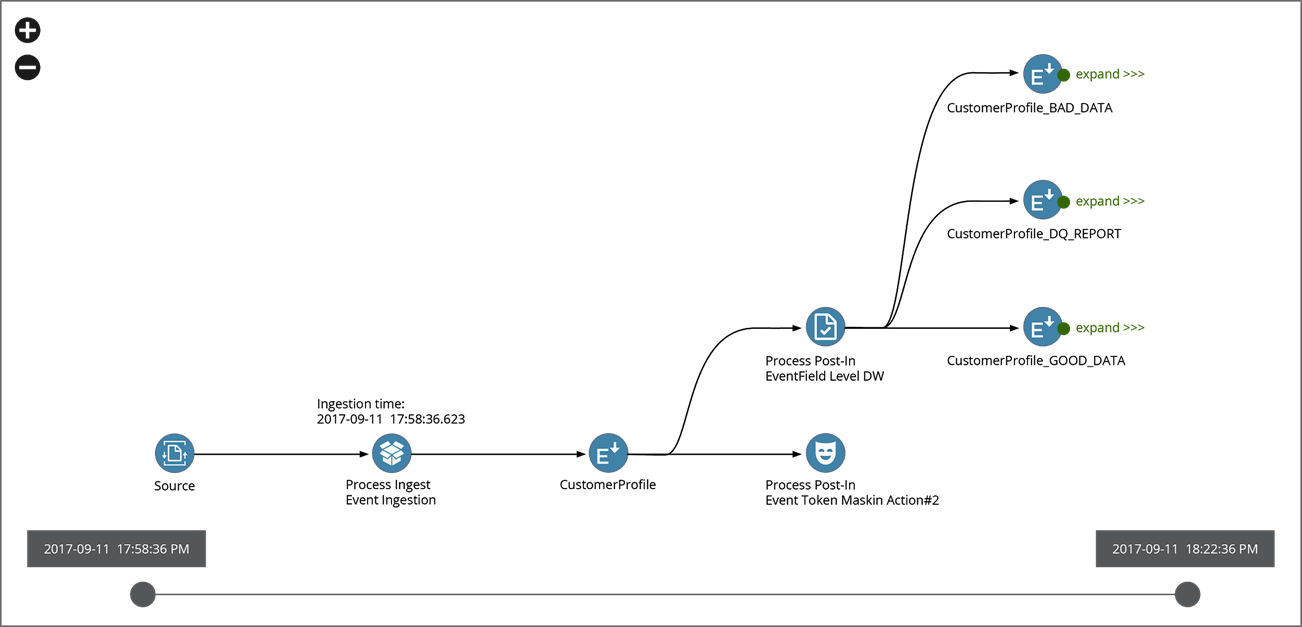
Figure 5 – Data lineage tracks data throughout its lifecycle.
4. Provide Business Users with Self-Service Data Access
Providing self-service access to your business and end data users is critical for data lake success. Unlike many single-purpose data catalogs that just inventory data, ZDP’s data catalog is embedded in the platform’s data management and governance functionality.
Users can use ZDP’s enterprise-wide catalog to explore what data is in the lake, and as a starting point for self-service activities such as data transformation and provisioning to a sandbox, analytics, or reporting environment. Users can search globally across zones, projects, workflows, data quality rules, and transformations, and collaborate with others in shared workspaces.
In a data lake on AWS, ZDP allows users to leverage its catalog to have a shopping-cart like experience to place datasets a user selects from the catalog into a cart and then provision it out to a sandbox RDBMS or location.
Such data provisioning could be either an Amazon S3 location, and Amazon Relational Database Service (Amazon RDS), Amazon EC2 instance, or even Amazon Redshift, where further processing or visualization of the data will take place.
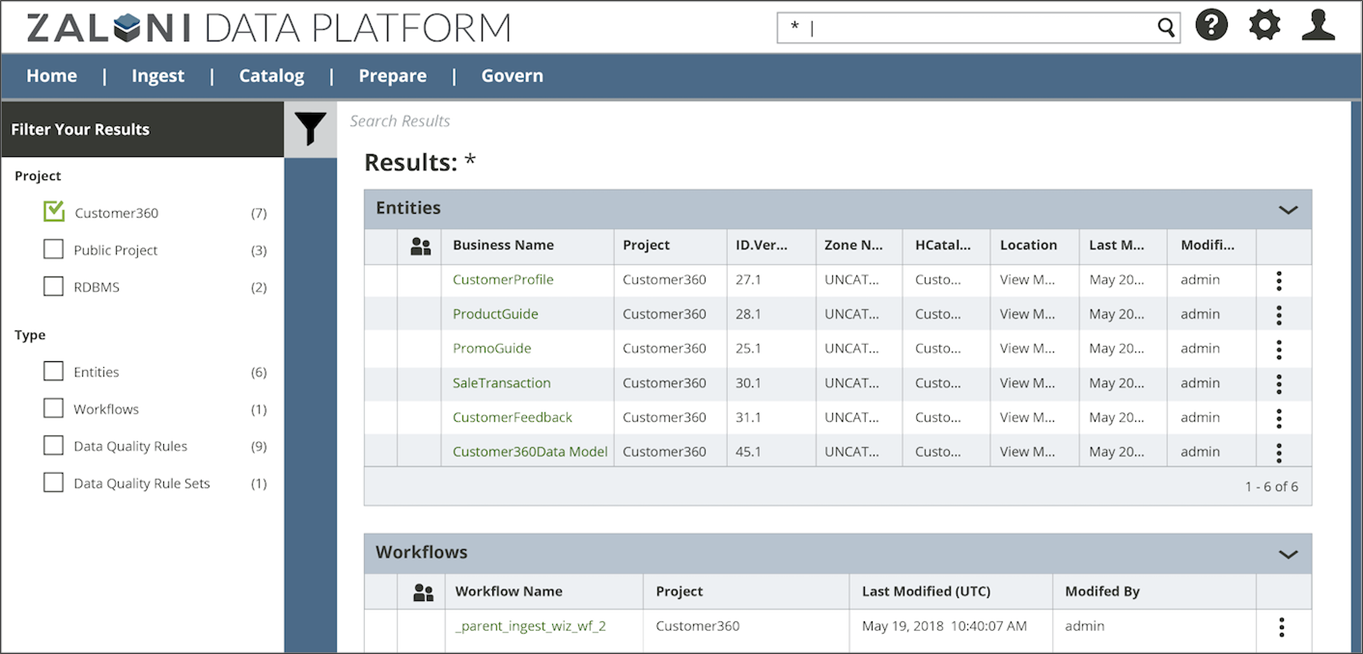
Figure 6 – ZDP’s global search helps users quickly find relevant data.
Derive More Value with AWS and ZDP
As more enterprises move their data lakes to the cloud to benefit from cost-savings, compute speed, scalability, security, and more, it’s critical to create a flexible and responsive data architecture.
In the case of TMX Group, a flexible and responsive architecture helped them successfully make data a key enterprise asset. Their enterprise data lake on AWS serves as the foundation for use cases such as data monetization, advanced analytics and customer 360.
Additionally, by using ZDP on AWS, TMX Group ensured regulatory compliance and reduced risk by applying governance throughout the data supply chain from data source to data consumer.
This level of governance has accelerated the use of data within the organization by making it easy for data consumers to access the data they need in a quick self-service manner while maintaining the level of control required by IT.
Summary
As companies continue to migrate their data environments to AWS, we see them run into challenges integrating siloed data sources into a centralized environment and providing easy access to data while maintaining the governance and control required by IT.
Zaloni helped TMX Group solve this problem by building a governed data lake on AWS using the Zaloni Data Platform (ZDP). Zaloni’s data platform provided centralized management, governance, and a self-service data catalog through a single unified platform.
Using ZDP and AWS, TMX Group was able to create an enterprise data lake that served as the foundation for use cases such as data monetization, advanced analytics, and customer 360.
When building a data lake on AWS, we recommend a zone-based architectural approach. This helps control how data is moved and processed throughout the data lake, and also improves governance and security through role-based access controls and traceability that shows where data is coming from, where it’s going, and what’s happened to it over time.
In addition to a zone-based architecture, there are four key areas that are important for data lake success. First, it’s important you can easily connect new and existing data sources. Second, you want to catalog your data for accurate, trusted ,and repeatable use. Third, you want to govern your data for security and reliability. Lastly, you want to be able to provide data consumers with self-service access to reduce time to insight.
If you’re interested in learning more about Zaloni Data Platform (ZDP), we are available on AWS Marketplace and you can contact us directly to see a demo and discuss your use case.
You can also check out these additional resources:
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Zaloni – APN Partner Spotlight
Zaloni is an AWS Data & Analytics Competency Partner. Its self-service data management platform helps enterprises securely grow analytics value through end-to-end data acceleration.
Contact Zaloni | Solution Overview | AWS Marketplace
*Already worked with Zaloni? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.