AWS Architecture Blog
Category: AWS DataSync

Designing a hybrid AI/ML data access strategy with Amazon SageMaker
Over time, many enterprises have built an on-premises cluster of servers, accumulating data, and then procuring more servers and storage. They often begin their ML journey by experimenting locally on their laptops. Investment in artificial intelligence (AI) is at a different stage in every business organization. Some remain completely on-premises, others are hybrid (both on-premises […]

Reduce archive cost with serverless data archiving
For regulatory reasons, decommissioning core business systems in financial services and insurance (FSI) markets requires data to remain accessible years after the application is retired. Traditionally, FSI companies either outsourced data archiving to third-party service providers, which maintained application replicas, or purchased vendor software to query and visualize archival data. In this blog post, we […]
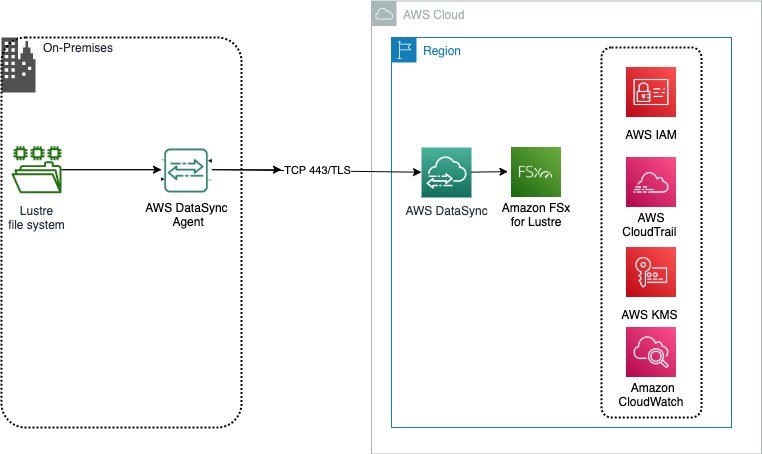
Migrating petabytes of data from on-premises file systems to Amazon FSx for Lustre
For International Women’s Day and Women’s History Month, we’re featuring more than a week’s worth of posts that highlight female builders and leaders. We’re showcasing women in the industry who are building, creating, and, above all, inspiring, empowering, and encouraging everyone—especially women and girls—in tech. Many organizations use the Lustre filesystem for Linux-based applications that […]

Creating a Multi-Region Application with AWS Services – Part 2, Data and Replication
Data is at the center of stateful applications. Data consistency models will vary when choosing in-Region vs. multi-Region. In this post, part 2 of 3, we continue to filter through AWS services to focus on data-centric services with native features to help get your data where it needs to be in support of a multi-Region […]

Migrating Microsoft APS PDW to Amazon Redshift Cloud Data Warehouse
Before cloud data warehouses (CDWs), many organizations used hyper-converged infrastructure (HCI) for data analytics. HCIs pack storage, compute, networking, and management capabilities into a single “box” that you can plug into your data centers. However, because of its legacy architecture, an HCI is limited in how much it can scale storage and compute and continue […]

Speed Up Translation Jobs with a Fully Automated Translation System Assistant
Like other industries, translation and localization companies face the challenge of providing fast delivery at a low cost. To address this challenge, organizations use Machine Translation (MT) to complement their translator teams. MT is the use of automated software that translates text without the need of human involvement. One of the most recent advancements is […]

Manage your Digital Microscopy Data using OMERO on AWS
The Open Microscopy Environment (OME) consortium develops open-source software and format standards for microscopy data. OME Remote Objects (OMERO) is an open source, image data management platform designed to support digital pathology and cellular biology studies. You can access, share, and work with various biological data. This can include histopathology, high content screening, electron microscopy, […]

Scaling RStudio/Shiny using Serverless Architecture and AWS Fargate
Data scientists use RStudio server as an Integrated Development Environment (IDE) to develop, publish, and share interactive web dashboards built on Shiny Server. Although it is possible to use virtual server infrastructure in the cloud to run R workloads, containerization offers significant operational benefits. Migrating R workloads into a serverless model in AWS, customers can […]