AWS Architecture Blog
Creating a Multi-Region Application with AWS Services – Part 2, Data and Replication
Data is at the center of stateful applications. Data consistency models will vary when choosing in-Region vs. multi-Region. In this post, part 2 of 3, we continue to filter through AWS services to focus on data-centric services with native features to help get your data where it needs to be in support of a multi-Region strategy for your application.
In Part 1 of this blog series, we looked at how you can use AWS compute, networking, and security services to build a foundation for a multi-Region application. In Part 3, we’ll look at AWS application management and monitoring services that help you build, monitor, and maintain a multi-Region application.
Considerations with replicating data
Data replication across the AWS network happens quickly, but keep in mind that a networking packet’s travel time will increase as the physical distance the packet needs to travel increases. For this reason, data consistency must be considered against performance when building multi-Region applications.
When building a distributed system, the consistency, availability, and partition tolerance (CAP) theorem must be considered. This theorem states that an application can only pick 2 out of the 3, and tradeoffs should be considered when making this decision.
- Consistency – all clients always have the same view of the data
- Availability – all clients can always read and write the data
- Partition Tolerance – the system will continue to work despite physical partitions
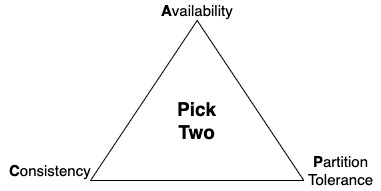
Achieving consistency and availability (CA) is common for single-Region architectures. For example, when an application connects to a single in-Region relational database. However, this becomes more difficult with multi-Region applications due to the latency added by transferring data over long distances. For this reason, highly distributed systems typically compromise on strict consistency, favoring availability and partition tolerance (AP). This is commonly referred to as an eventual consistency data model.
Replicating objects and files
The scale, durability, and availability of Amazon Simple Storage Service (Amazon S3) make it an excellent destination to store various assets for your application. To enable quick access of this data to your application regardless of the Region it’s deployed in, you can set up Amazon S3 to replicate data across AWS Regions with one-way or two-way continuous replication. If your application doesn’t require all of the objects in a bucket for optimal functionality, a subset of objects can be replicated with Amazon S3 replication rules. Amazon S3 within a Region offers strong read-after-write consistency; however, replicated objects will be eventually consistent in destination Regions. If maintaining low replication lag is critical, S3 Replication Time Control will replicate 99.99% of objects within 15 minutes, and most within seconds. Observability is critical at all layers of an application, and you can watch over the replication status of objects with Amazon S3 events and metrics.
Each S3 bucket is provisioned with its own Region-based virtual hosted endpoint, this means that the endpoint includes the Region of the bucket in the URL, for example:
https://<MY-BUCKET>.s3.<AWS-REGION>.amazonaws.com/
To simplify connecting to and managing multiple bucket endpoints, Amazon S3 Multi-Region Access Points create a single global endpoint that spans multiple S3 buckets in different Regions. When applications connect to this endpoint, requests will route over the AWS network using AWS Global Accelerator to the bucket with the lowest latency. Failover routing is also handled automatically if the availability of a bucket changes. You will notice that these endpoints are Region agnostic in the URL:
https://<RANDOM-STRING>.mrap.s3-global.amazonaws.com/
If parts of your application don’t yet support reading and writing to a web-based object store like Amazon S3, you can get the same durability and availability on a shared file system with Amazon Elastic File System (Amazon EFS) Regional storage classes. To ensure multi-Region application deployments can access this data locally, you can setup Amazon EFS block-based replication to a read-only EFS volume in another Region.
For files stored outside of Amazon S3 and Amazon EFS, AWS DataSync simplifies, automates, and accelerates moving data across Regions and accounts. It supports homogeneous and heterogeneous file migrations across Amazon FSx, AWS Snowcone, Amazon EFS, and Amazon S3. It can even be used to sync on-premises files stored on NFS, SMB, HDFS, and self-managed object storage to AWS for hybrid architectures.
File and object replication should be expected to be eventually consistent. The rate at which a given dataset can transfer is a function of the amount of data, I/O bandwidth, network bandwidth, network conditions, and physical distance.
Copying backups
In addition to replication, you should also back up your data. In case of data corruption or accidental deletion, a backup will enable you to recover to the last known good state. Also, not all data needs to be replicated in real time. For example, if you’re architecting for disaster recovery and your application has a longer RTO (Recovery Time Objective) and RPO (Recovery Point Objective), then replicating backups on a schedule could meet your requirements while being more cost efficient. For these use cases, AWS Backup can automate the backup of your data to meet business requirements, and these backups can be configured to automatically copy backups to one or more AWS Regions or accounts. Copy times depend on the size of your backup and the distance it needs to be transferred. You should first run tests to determine if this cross-Region copy time will affect your defined RTO and RPO. A growing number of services are supported, and this can be especially useful for services that don’t offer real-time replication to another Region such as Amazon Elastic Compute Cloud (Amazon EC2) or Amazon Neptune.
Figure 1 shows how the data services mentioned can be combined for each resource into an architecture. We use Amazon S3 bi-directional replication to keep our bucket objects in sync while allowing writes from either Region. Our Amazon EC2-based application servers have an Amazon EFS mount that includes our latest application binaries and supporting files, and we rely on Amazon EFS replication to keep this data in sync across Region deployments. Finally, we use AWS Backup to snapshot our EC2 instances and store them as AMI images in our secondary Region.

Figure 1. Storage replication services
Spanning non-relational databases across Regions
Amazon DynamoDB global tables provide multi-Region and multi-writer capabilities to help you build global applications at scale. A DynamoDB global table is the only AWS managed database offering that allows for multiple active writers with conflict detection in a multi-Region topology (active-active and multi-Region). This allows for applications to read and write in the Region closest to them, with changes automatically replicated to other Regions.
Global reads and fast recovery for Amazon DocumentDB (with MongoDB compatibility) can be achieved with global clusters. These clusters have a primary Region that handles write operations. Dedicated storage-based replication infrastructure enables low-latency global reads with a lag of typically less than one second.
Keeping in-memory caches warm with the same data across Regions can be critical to maintain application performance. Amazon ElastiCache (Redis OSS) offers global datastore to create a fully managed, fast, reliable, and secure cross-Region replica for Redis OSS caches and databases. With global datastore, writes occurring in one Region can be read from up to two other cross-Region replica clusters – eliminating the need to write to multiple caches to keep them warm.
Spanning relational databases across Regions
For applications that require a relational data model, Amazon Aurora global database provides for scaling of database reads across Regions in Aurora PostgreSQL-compatible and MySQL-compatible editions. Dedicated replication infrastructure utilizes physical storage-based replication to achieve consistently low replication lag that outperforms the built-in logical replication database engines offer, as shown in Figure 2.

Figure 2. SysBench OLTP (write-only) stepped every 600 seconds on R4.16xlarge
With Aurora global database, a cluster in one Region is designated as the writer, and secondary Regions are dedicated to reads. While only one instance can process writes, Aurora MySQL supports write forwarding, a feature that will forward write queries from a secondary Region endpoint to the primary Region to simplify logic in application code.
You can test Regional failover by utilizing Aurora global database managed planned failover. This action will change the active write cluster to a secondary Region while keeping the replication topology intact. It should be noted that this action has a dependency on Aurora in the primary Region being available, so make sure you take this into account for disaster recovery plans. If Aurora in the primary Region isn’t available, you can still promote any of your Aurora secondary clusters in the Aurora global database. This promotion process is executed from the secondary Region. Over the course of about one minute, this removes the cluster from Aurora global database, activates the regional writer endpoint, and promotes one of the cluster instances to be the active writer. Once this process completes, you will need to update your application’s database connection string to connect to the new writer endpoint.
All databases discussed in this post practice eventual consistency when used across Regions, but Aurora PostgreSQL–based global databases have an additional option to specify the maximum replica lag allowed with managed recovery point objective (managed RPO).
For backup-and-restore capabilities, Aurora has a minimum 1-day and maximum 35-day retention for automated backups in all clusters, including secondary global clusters. This gives you the ability to restore secondary clusters to a specified point-in-time in the destination Region if needed.
Logical replication, which utilizes a database engine’s built-in replication technology, can be set up for Amazon Relational Database Service (Amazon RDS) for MariaDB, MySQL, Oracle, PostgreSQL, and Aurora databases. A cross-Region read replica will receive and process changes from the writer in the primary Region. Cross-Region replicas allow for quicker local reads and can reduce data loss and recovery times in the case of a disaster by being promoted to a standalone instance. Logical replication technology can also be used to replicate data to a resource outside of Amazon RDS, such as an EC2 instance, an on-premises server, or even a data lake.
For situations where a longer RPO and RTO are acceptable, backups can be copied across Regions. This is true for all of the relational and non-relational databases mentioned in this post, except for ElastiCache. While Amazon Redshift doesn’t have cross-Region replication features, you can set up Amazon Redshift to automatically replicate snapshots of your data warehouse to another Region. Backup copy times will vary depending on size and data change rates.
Bringing it together
At the end of each part of this blog series, we build on a sample application based on the services covered. This shows you how to bring these services together to build a multi-Region application with AWS services. We don’t use every service mentioned, just those that fit the use case.
We built this example to expand to a global audience. It requires high availability across Regions, and favors performance over strict consistency. We have chosen the following services covered in this post to accomplish our goals, building on our foundation from part 1:
- DynamoDB global tables so our application deployed in each Region can both read and write to a database in-Region.
- ElastiCache Global Datastore as a caching layer. Writes to global datastore can only happen in Region 1, but this is okay for our use case since the application relies on similar cached items regardless of the Region.
- An S3 bucket to store application data, configuration files, static content, and user-uploaded data. Amazon S3 bi-directional cross-Region replication keeps the buckets in each Region in sync. Finally, our application uses an Amazon S3 multi-Region access point to make sure requests to Amazon S3 are routed to the lowest latency and automatic failover is handled
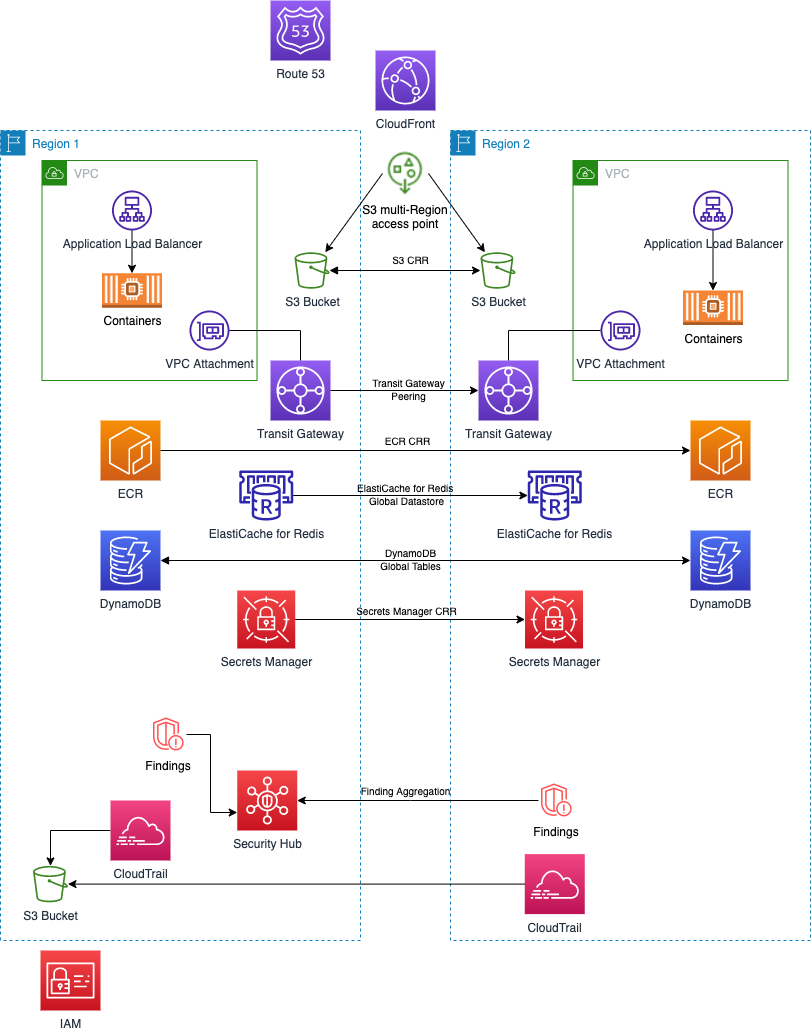
Figure 3. Building an application with AWS multi-Region services using services covered in Part 1
While our primary objective is expanding to a global audience, we note that some of the replication that has been set up is one-way, such as for ElastiCache Global Datastore. Each Regional deployment is set up for static stability, but if there were an outage in Region 1 for an extended period of time, our DR playbook would outline how to make each service writable in Region 2.
Summary
Data is at the center of almost every application. In this post, we reviewed AWS services that offer cross-Region data replication to get your data where it needs to be quickly. Whether your application requires faster local reads, an active-active database, or you simply need your data durably stored in a second Region, we have a solution for you. In the 3rd and final post of this series, we’ll cover application management and monitoring features.
Ready to get started? We’ve chosen some AWS Solutions, AWS Blogs, and Well-Architected labs to help you!