AWS Architecture Blog
Category: Technical How-to

Pilot light with reserved capacity: How to optimize DR cost using On-Demand Capacity Reservations
In this post, we explore an intermediate strategy between the pilot light and the warm standby strategies: pilot light with reserved capacity. You can use this strategy to reserve compute capacity in a secondary Region while also limiting cost.

Building a three-tier architecture on a budget
AWS customers often look for ways to run their systems within or under budget, avoiding unnecessary costs. This post offers practical advice on designing scalable and cost-efficient three-tier architectures by using serverless technologies within the AWS Free Tier. With AWS, you can start small and scale cost-effectively as your business demand increases. You can begin […]

Genomics workflows, Part 7: analyze public RNA sequencing data using AWS HealthOmics
Genomics workflows process petabyte-scale datasets on large pools of compute resources. In this blog post, we discuss how life science organizations can use Amazon Web Services (AWS) to run transcriptomic sequencing data analysis using public datasets. This allows users to quickly test research hypotheses against larger datasets in support of clinical diagnostics. We use AWS […]

Genomics workflows, Part 6: cost prediction
Genomics workflows run on large pools of compute resources and take petabyte-scale datasets as inputs. Workflow runs can cost as much as hundreds of thousands of US dollars. Given this large scale, scientists want to estimate the projected cost of their genomics workflow runs before deciding to launch them. In Part 6 of this series, […]

Content Repository for Unstructured Data with Multilingual Semantic Search: Part 2
Leveraging vast unstructured data poses challenges, particularly for global businesses needing cross-language data search. In Part 1 of this blog series, we built the architectural foundation for the content repository. The key component of Part 1 was the dynamic access control-based logic with a web UI to upload documents. In Part 2, we extend the […]

Disaster Recovery for Oracle Database on Amazon EC2 with Fast-Start Failover
High availability is non-negotiable for organizations today to prevent business-critical application disruptions. Enterprises must prioritize database scalability and availability to avoid downtime in their databases, network, servers, or storage environments. For organizations that want to avoid required application changes, Oracle Real Application Clusters (RAC) is an option for providing high availability and scalability to the […]

Simulating Kubernetes-workload AZ failures with AWS Fault Injection Simulator
In highly distributed systems, it is crucial to ensure that applications function correctly even during infrastructure failures. One common infrastructure failure scenario is when an entire Availability Zone (AZ) becomes unavailable. Applications are often deployed across multiple AZs to ensure high availability and fault tolerance in cloud environments such as Amazon Web Services (AWS). Kubernetes […]

Managing data confidentiality for Scope 3 emissions using AWS Clean Rooms
Scope 3 emissions are indirect greenhouse gas emissions that are a result of a company’s activities, but occur outside the company’s direct control or ownership. Measuring these emissions requires collecting data from a wide range of external sources, like raw material suppliers, transportation providers, and other third parties. One of the main challenges with Scope […]

Optimizing fleet utilization with Amazon Location Service and HERE Technologies
The fleet management market is expected to grow at a Compound Annual Growth Rate (CAGR) of 15.5 percent—from 25.5 billion US dollars in 2022 to USD 52.4 billion in 2027. Optimizing how your organization uses its vehicle fleet is important for logistics and service providers such as last mile, middle mile, and field services. In […]
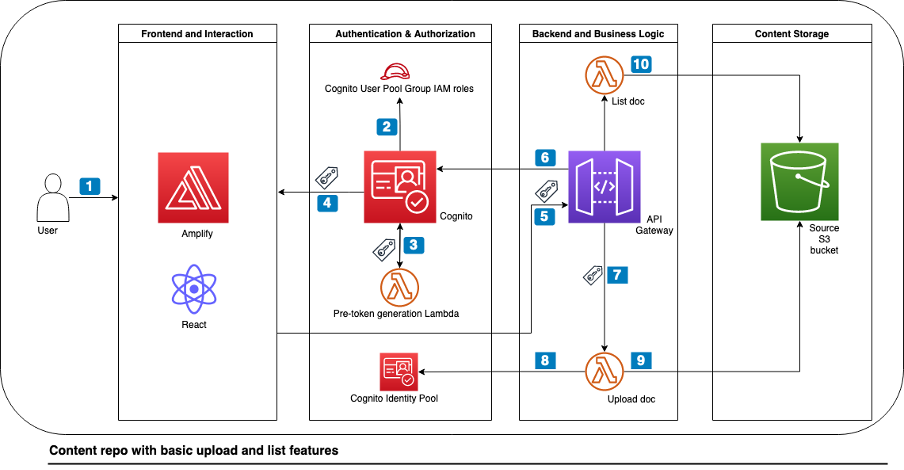
Content Repository for Unstructured Data with Multilingual Semantic Search: Part 1
Unstructured data can make up to 80 percent of data in the day-to-day business of financial organizations. For example, these organizations typically store and read PDFs and images for claim processing, underwriting, and know your customer (KYC). Organizations need to make this ingested data accessible and searchable across different entities while logically separating data access […]