AWS Architecture Blog
Content Repository for Unstructured Data with Multilingual Semantic Search: Part 1
Unstructured data can make up to 80 percent of data in the day-to-day business of financial organizations. For example, these organizations typically store and read PDFs and images for claim processing, underwriting, and know your customer (KYC). Organizations need to make this ingested data accessible and searchable across different entities while logically separating data access according to role requirements.
In this two-part series, we use AWS services to build an end-to-end content repository for storing and processing unstructured data with the following features:
- Dynamic access control-based logic over unstructured data
- Multilingual semantic search capabilities
In part 1, we build the architectural foundation for the content repository, including the resource access control logic and a web UI to upload and list documents.
Solution overview
The content repository includes four building blocks:
Frontend and interaction: For this function, we use AWS Amplify, which is a set of purpose-built tools and features to help frontend web and mobile developers quickly build full-stack applications on AWS. The React application uses the AWS Amplify authentication feature to quickly set up a complete authentication flow integrated into Amazon Cognito. Amplify also hosts the frontend application.
Authentication and authorization: Implementing dynamic resource access control with a combination of roles and attributes is fundamental to your content repository security. Amazon Cognito provides a managed, scalable user directory, user sign-up and sign-in flows, and federation capabilities through third-party identity providers. We use Amazon Cognito user pools as the source of user identity for the content repository. You can work with user pool groups to represent different types of user collection, and you can manage their permissions using a group-associated AWS Identity and Access Management (IAM) role.
Users authenticate against the Amazon Cognito user pool. The web app will exchange the user pool tokens for AWS credentials through an Amazon Cognito identity pool in the content repository. You can complement the IAM role-based authorization model by mapping your relevant attributes to principal tags that will be evaluated as part of IAM permission policies. This allows a dynamic and flexible authorization strategy. For use cases that need federation with third-party identity providers, you can base your user collection on existing user group attributes, such as Active Directory group membership.
Backend and business logic: Authenticated users are redirected to the Amazon API Gateway. API Gateway provides managed publishing for application programming interfaces (APIs) that act as the repository’s “front door.” API Gateway also interacts with the repository’s backend through RESTful APIs. This makes the business logic of the content repository extensible for future use cases, such as transcription and translation. We use AWS Lambda as a serverless, event-driven compute service to run specific business logic code, such as uploading a document to the content repository.
Content storage: Amazon Simple Storage Service (Amazon S3) provides virtually unlimited scalability and high durability. With Amazon S3, you can cost-effectively store unstructured documents in their native formats and make it accessible in a secure and scalable way. Enriching the uploaded documents with tags simplifies data governance with fine-grained access control.
Technical architecture
The technical architecture of the content repository with these four components can be found in Figure 1.
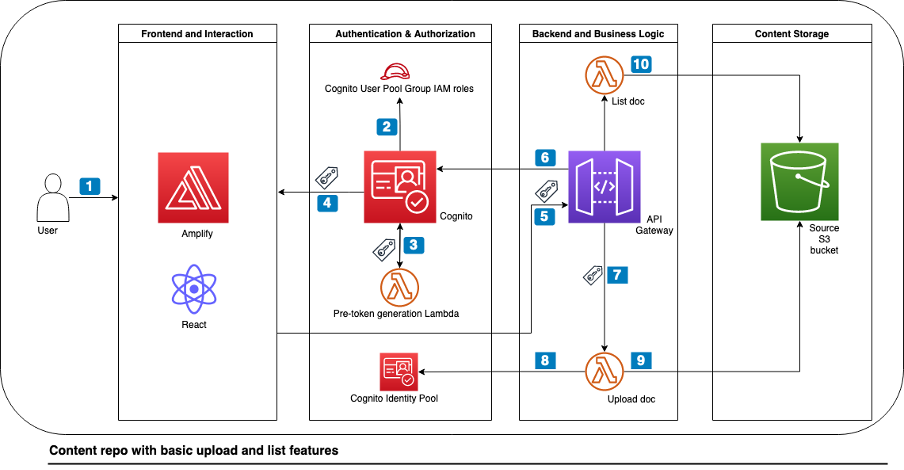
Figure 1. Technical architecture of the content repository
Let’s explore the architecture step by step.
- The frontend uses the Amplify JS library to add the authentication UI component to your React app, allowing authenticated users to sign in.
- Once the user provides their sign-in credentials, they are redirected to Amazon Cognito user pools to be authenticated.
- Once the authentication is successful, Amazon Cognito invokes a pre-token generation Lambda function. This function customizes the identity (ID) token with a new claim called
department. This new claim is the Amazon Cognito group name from thecognito:preferred_roleclaim. - Amazon Cognito returns the identity, access, and refresh token in JSON format to the frontend.
- The Amplify client library stores the tokens and handles refreshes using the refresh token while the React frontend application calls the API Gateway with the ID token. Note: Usually, you would use the access token to grant access to authorized resources. For this architecture, we use the ID token because we have enriched it with the custom claim during step 3.
- API Gateway uses its native integration with Amazon Cognito and validates the ID token’s signature and expiration using Amazon Cognito user pool authorizer. For more complex authorization scenarios, you can use API Gateway Lambda authorizer with the AWS JSON Web Token (JWT) Verify library for verifying JWTs signed by Amazon Cognito.
- After successful validation, API Gateway passes the ID token to the backend Lambda function, which can verify and authorize upon it for access control.
- Upon document upload action, the backend Lambda function calls the Amazon Cognito identity pool to exchange the ID token for the temporary AWS credentials associated with the
cognito:preferred_roleclaim. - The document upload Lambda function returns a pre-signed URL with the custom
departmentclaim in the Amazon S3 path prefix as well as the object tag. The Amazon S3 pre-signed URL is used for the document upload from the frontend application directly to Amazon S3. - Upon document list action, similar to step 8, the backend Lambda function exchanges the ID token for the temporary AWS credentials. The Lambda function returns only the documents based on the user’s preferred group and associated custom
departmentclaim.
Prerequisites
You must have the following prerequisites for this solution:
- An AWS account or sign up to create and activate one.
- The following software installed on your development machine, or use an AWS Cloud9 environment:
- Install the AWS Command Line Interface (AWS CLI) and configure it to point to your AWS account.
- Install TypeScript and use a package manager such as npm.
- Install the AWS Cloud Development Kit (AWS CDK).
- Appropriate AWS credentials for interacting with resources in your AWS account.
Walkthrough
Setup
The following steps will deploy two AWS CDK stacks into your AWS account:
- content-repo-stack (
blog-content-repo-stack.ts) creates the environment detailed in Figure 1. - demo-data-stack (
userpool-demo-data-stack.ts) deploys sample users, groups, and role mappings.
To continue setup, use the following commands:
- Clone the project git repository:
git clone https://github.com/aws-samples/content-repository-with-dynamic-access-control content-repository - Install the necessary dependencies:
cd content-repository/backend-cdk npm install - Configure environment variables:
export CDK_DEFAULT_ACCOUNT=$(aws sts get-caller-identity --query 'Account' --output text) export CDK_DEFAULT_REGION=$(aws configure get region) - Bootstrap your account for AWS CDK usage:
cdk bootstrap aws://$CDK_DEFAULT_ACCOUNT/$CDK_DEFAULT_REGION - Deploy the code to your AWS account:
cdk deploy --all
Using the repository
Once you deploy the CDK stacks in your AWS account, follow these steps:
1. Access the frontend application:
a. Copy the amplifyHostedAppUrl value shown in the AWS CDK output from the content-repo-stack.
b. Use the URL with your web browser to access the frontend application.
c. A temporary page displays until the automated build and deployment of the React application completes after 4-5 minutes.
2. Application sign-in and role-based access control (RBAC):
a. The React webpage prompts you to sign in and then change the temporary password.
b. The content repository provides two demo users with credentials as part of the demo-data-stack in the AWS CDK output. In this walkthrough, we use the sales-user user, which belongs to the sales department group to validate RBAC.
3. Upload a document to the content repository:
a. Authenticate as sales-user.
b. Select upload to upload your first document to the content repository.
c. The repository provides sample documents in the assets sub-folder.
4. List your uploaded document:
a. Select list to show the uploaded sales content.
b. To verify the dynamic access control, repeat steps 2 and 3 for the marketing-user user, which belongs to the marketing department group.
c. Sign-in to the AWS Management Console and navigate to the Amazon S3 bucket with the prefix content-repo-stack-s3sourcebucket to confirm that all the uploaded content exists.
Implementation notes
Frontend deployment and cross-origin access
The content-repo-stack contains an AwsCustomResource construct. This construct uses the Amplify API to start the release job of the Amplify hosted frontend application. The preBuild step of the Amplify application build specification dynamically configures its backend for the Amazon Cognito-based authentication. The required Amazon Cognito configuration parameters are retrieved from the AWS Systems Manager Parameter Store during build time. Similarly, the Amplify application postBuild step updates the Amazon S3 cross-origin resource sharing (CORS) rule for the Amazon S3 bucket to only allow cross-origin access from the Amplify-hosted URL of the frontend application.
Application sign-in and access control
The Amazon Cognito identity pool configuration is set to Choose role from token for authenticated users, as in Figure 2. This setup permits authenticated users to pass the roles in the ID token that the Amazon Cognito user pool assigned. Backend Lambda functions use the roles that appear in the cognito:roles and cognito:preferred_role claims in the ID token for RBAC.
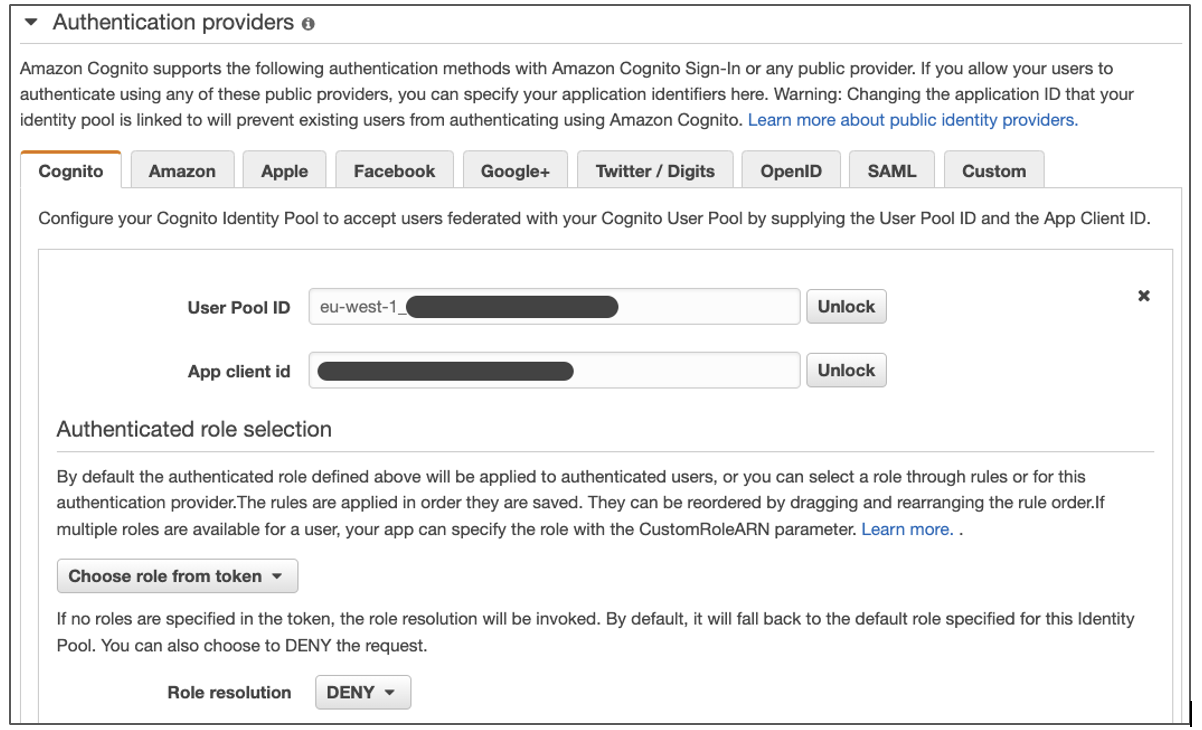
Figure 2. Amazon Cognito identity pool configuration – using tokens to assign roles to authenticated users
In the attributes for access control section, we configured a custom mapping from the augmented department token claim to a tag key, as in Figure 3. The backend logic uses the tag key to match the PrincipalTag condition in IAM policies to control access to AWS resources.

Figure 3. Amazon Cognito identity pool configuration – custom mapping from claim names to tag keys
Document upload
The presigned_url.py Lambda function generates a pre-signed Amazon S3 URL using the department token claim as the key. This function automatically organizes the uploaded document into a logical structure in the Amazon S3 source bucket. Accordingly, the cognito:preferred_role used for the Amazon S3 client credentials in the Lambda function has a permission policy using the PrincipalTag department to dynamically limit access to the Amazon S3 key, as in Figure 4.

Figure 4. Permission policy using PrincipalTag to upload documents to Amazon S3
Document listing
The list functionality only shows the uploaded content belonging to the preferred group of authenticated Amazon Cognito user pool user. To only list the files that a specific user (for example, sales-user) has access to, use the PrincipalTag s3:prefix condition, as in Figure 5.

Figure 5. Permission policy using s3:prefix condition with session tags to list documents
Cleanup
In the backend-cdk subdirectory, delete the deployed resources:
cdk destroy --allConclusion
In this blog, we demonstrated how to build a content repository with an easy-to-use web application for unstructured data that ingests documents while maintaining dynamic access control for users within departments. These steps provide a foundation to build your own content repository to store and process documents. As next steps, based on your organization’s security requirements, you can implement more complex access control use cases by balancing IAM role and principal tags. For example, you can use Amazon Cognito user pool custom attributes for additional dimensions such as document “clearance” with optional modification in the pre-token generation Lambda.
In the next part of this blog series, we will enrich the content repository with multi-lingual semantic search features while maintaining the access control fundamentals we’ve already implemented. For additional information on how you can build a solution to search for information across multiple scanned documents, PDFs, and images with compliance capabilities, please refer our Document Understanding Solution from AWS Solutions Library.