AWS Big Data Blog
Author: Jan Michael Go Tan
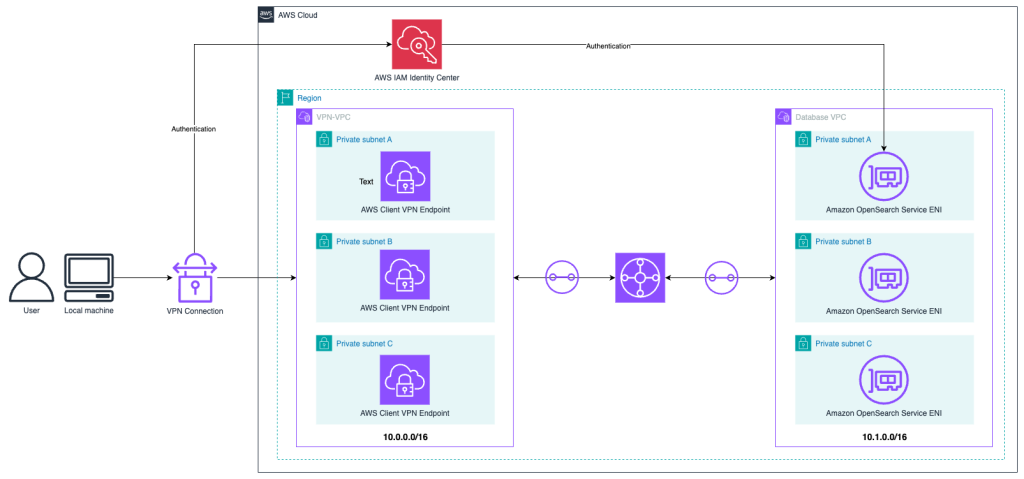
Access a VPC-hosted Amazon OpenSearch Service domain with SAML authentication using AWS Client VPN
In this post, we explore different OpenSearch Service authentication methods and network topology considerations. Then we show how to build an architecture to access an OpenSearch Service domain hosted in a VPC using AWS Client VPN, AWS Transit Gateway, and AWS IAM Identity Center.

Use the AWS CDK with the Data Solutions Framework to provision and manage Amazon Redshift Serverless
In this post, we demonstrate how to use the AWS CDK and DSF to create a multi-data warehouse platform based on Amazon Redshift Serverless. DSF simplifies the provisioning of Redshift Serverless, initialization and cataloging of data, and data sharing between different data warehouse deployments.

Use an event-driven architecture to build a data mesh on AWS
In this post, we take the data mesh design discussed in Design a data mesh architecture using AWS Lake Formation and AWS Glue, and demonstrate how to initialize data domain accounts to enable managed sharing; we also go through how we can use an event-driven approach to automate processes between the central governance account and […]

Build a data sharing workflow with AWS Lake Formation for your data mesh
A key benefit of a data mesh architecture is allowing different lines of business (LOBs) and organizational units to operate independently and offer their data as a product. This model not only allows organizations to scale, but also gives the end-to-end ownership of maintaining the product to data producers that are the domain experts of […]

Apply CI/CD DevOps principles to Amazon Redshift development
CI/CD in the context of application development is a well-understood topic, and developers can choose from numerous patterns and tools to build their pipelines to handle the build, test, and deploy cycle when a new commit gets into version control. For stored procedures or even schema changes that are directly related to the application, this […]