AWS Big Data Blog
Category: Amazon Managed Streaming for Apache Kafka (Amazon MSK)

Use Amazon MSK Connect and Iceberg Kafka Connect to build a real-time data lake
In this post, we demonstrate how to use Iceberg Kafka Connect with Amazon Managed Streaming for Apache Kafka (Amazon MSK) Connect to accelerate real-time data ingestion into data lakes, simplifying the synchronization process from transactional databases to Apache Iceberg tables.

On-demand and scheduled scaling of Amazon MSK Express based clusters
Amazon MSK Express brokers are a key component to dynamically scaling clusters to meet demand. Express based clusters deliver 3 times higher throughput, 20 times faster scaling capabilities, and 90% faster broker recovery compared to Amazon MSK Provisioned clusters. In addition, Express brokers support intelligent rebalancing for 180 times faster operation performance, so partitions are automatically and consistently well distributed across brokers. Intelligent rebalancing automatically tracks cluster health and triggers partition redistribution when resource imbalances are detected, maintaining performance across brokers. This post demonstrates how to use the intelligent rebalancing feature and build a custom solution that scales Express based clusters horizontally (adding and removing brokers) dynamically based on Amazon CloudWatch metrics and predefined schedules. The solution provides capacity management while maintaining cluster performance and minimizing overhead.
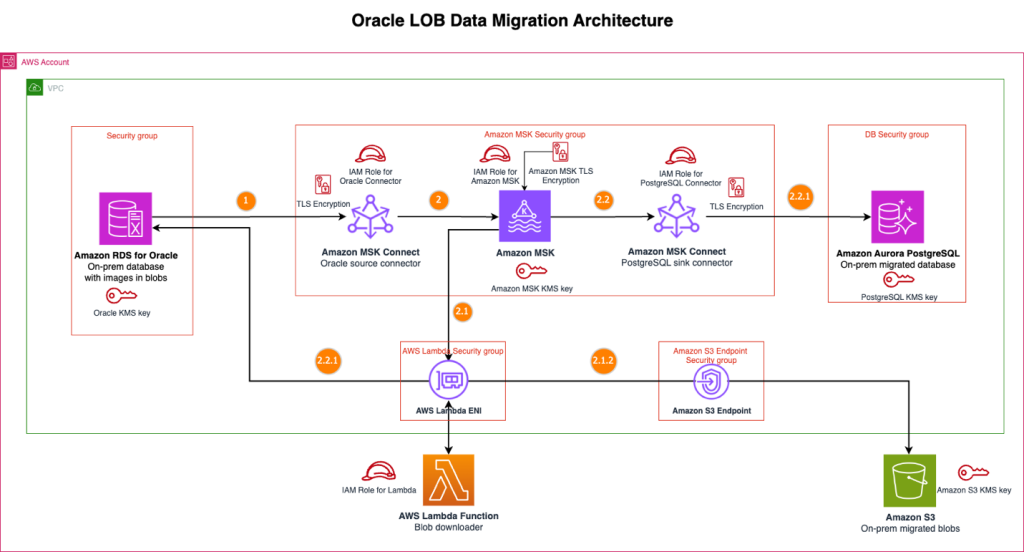
Streamline large binary object migrations: A Kafka-based solution for Oracle to Amazon Aurora PostgreSQL and Amazon S3
In this post, we present a scalable solution that addresses the challenge of migrating your large binary objects (LOBs) from Oracle to AWS by using a streaming architecture that separates LOB storage from structured data. This approach avoids size constraints, reduces Oracle licensing costs, and preserves data integrity throughout extended migration periods.

How Bazaarvoice modernized their Apache Kafka infrastructure with Amazon MSK
Bazaarvoice is an Austin-based company powering a world-leading reviews and ratings platform. Our system processes billions of consumer interactions through ratings, reviews, images, and videos, helping brands and retailers build shopper confidence and drive sales by using authentic user-generated content (UGC) across the customer journey. In this post, we show you the steps we took to migrate our workloads from self-hosted Kafka to Amazon Managed Streaming for Apache Kafka (Amazon MSK). We walk you through our migration process and highlight the improvements we achieved after this transition.
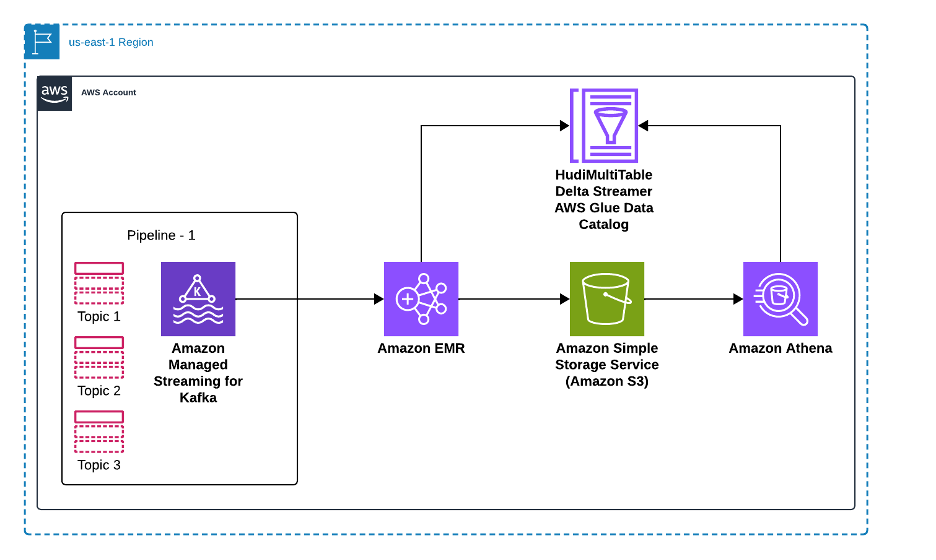
Using Amazon EMR DeltaStreamer to stream data to multiple Apache Hudi tables
In this post, we show you how to implement real-time data ingestion from multiple Kafka topics to Apache Hudi tables using Amazon EMR. This solution streamlines data ingestion by processing multiple Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics in parallel while providing data quality and scalability through change data capture (CDC) and Apache Hudi.

Simplified management of Amazon MSK with natural language using Kiro CLI and Amazon MSK MCP Server
In this post, we demonstrate how Kiro CLI and the MSK MCP server can streamline your Kafka management. Through practical examples and demonstrations, we show you how to use these tools to perform common administrative tasks efficiently while maintaining robust security and reliability.

Medidata’s journey to a modern lakehouse architecture on AWS
In this post, we show you how Medidata created a unified, scalable, real-time data platform that serves thousands of clinical trials worldwide with AWS services, Apache Iceberg, and a modern lakehouse architecture.

How Yelp modernized its data infrastructure with a streaming lakehouse on AWS
This is a guest post by Umesh Dangat, Senior Principal Engineer for Distributed Services and Systems at Yelp, and Toby Cole, Principle Engineer for Data Processing at Yelp, in partnership with AWS. Yelp processes massive amounts of user data daily—over 300 million business reviews, 100,000 photo uploads, and countless check-ins. Maintaining sub-minute data freshness with […]

Amazon MSK Express brokers now support Intelligent Rebalancing for 180 times faster operation performance
Effective today, all new Amazon Managed Streaming for Apache Kafka (Amazon MSK) Provisioned clusters with Express brokers will support Intelligent Rebalancing at no additional cost. In this post we’ll introduce the Intelligent Rebalancing feature and show an example of how it works to improve operation performance.

Unlock real-time data insights with schema evolution using Amazon MSK Serverless, Iceberg, and AWS Glue streaming
This post showcases a solution that businesses can use to access real-time data insights without the traditional delays between data creation and analysis. By combining Amazon MSK Serverless, Debezium MySQL connector, AWS Glue streaming, and Apache Iceberg tables, the architecture captures database changes instantly and makes them immediately available for analytics through Amazon Athena. A standout feature is the system’s ability to automatically adapt when database structures change—such as adding new columns—without disrupting operations or requiring manual intervention.