AWS Big Data Blog
Category: Amazon Redshift

Set up federated access to Amazon Athena for Microsoft AD FS users using AWS Lake Formation and a JDBC client
Tens of thousands of AWS customers choose Amazon Simple Storage Service (Amazon S3) as their data lake to run big data analytics, interactive queries, high-performance computing, and artificial intelligence (AI) and machine learning (ML) applications to gain business insights from their data. On top of these data lakes, you can use AWS Lake Formation to […]

Amazon Redshift data sharing best practices and considerations
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift data sharing allows for a secure and easy way to share live data for reading across Amazon Redshift clusters. It allows an […]
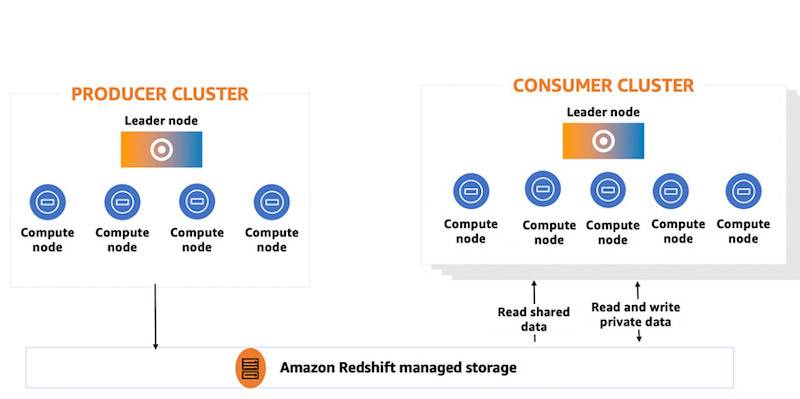
From centralized architecture to decentralized architecture: How data sharing fine-tunes Amazon Redshift workloads
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. With the significant growth of data for big […]

Build a resilient Amazon Redshift architecture with automatic recovery enabled
Amazon Redshift provides resiliency in the event of a single point of failure in a cluster, including automatically detecting and recovering from drive and node failures. The Amazon Redshift relocation feature adds an additional level of availability, and this post is focused on explaining this automatic recovery feature. When the cluster relocation feature is enabled […]
Manage data transformations with dbt in Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. Amazon Redshift enables you to use your data to acquire new insights for your business and customers while keeping costs low. Together with price-performance, […]
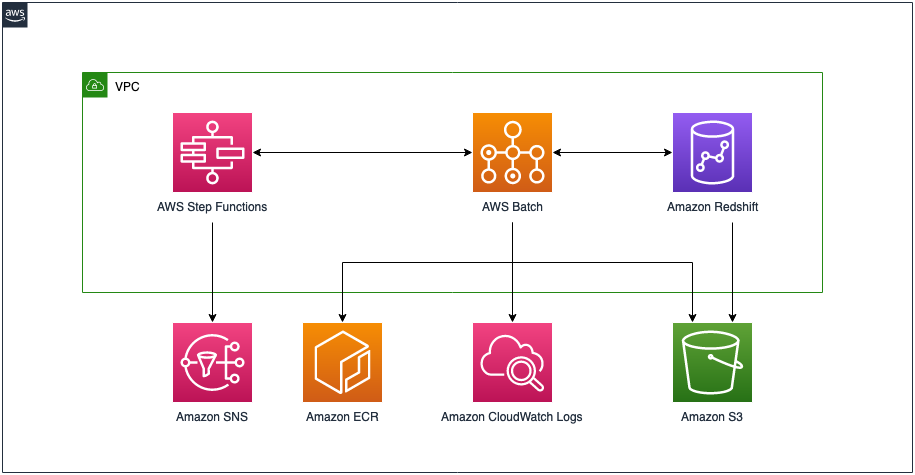
Develop an Amazon Redshift ETL serverless framework using RSQL, AWS Batch, and AWS Step Functions
Amazon Redshift RSQL is a command-line client for interacting with Amazon Redshift clusters and databases. You can connect to an Amazon Redshift cluster, describe database objects, query data, and view query results in various output formats. You can use enhanced control flow commands to replace existing extract, transform, load (ETL) and automation scripts. This post […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Use SQL queries to define Amazon Redshift datasets in AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. In the post Data preparation using Amazon Redshift with AWS Glue DataBrew, we saw how to create an AWS Glue DataBrew job using a JDBC connection for Amazon Redshift. In this post, we show you how to create a DataBrew profile job and a recipe job using […]
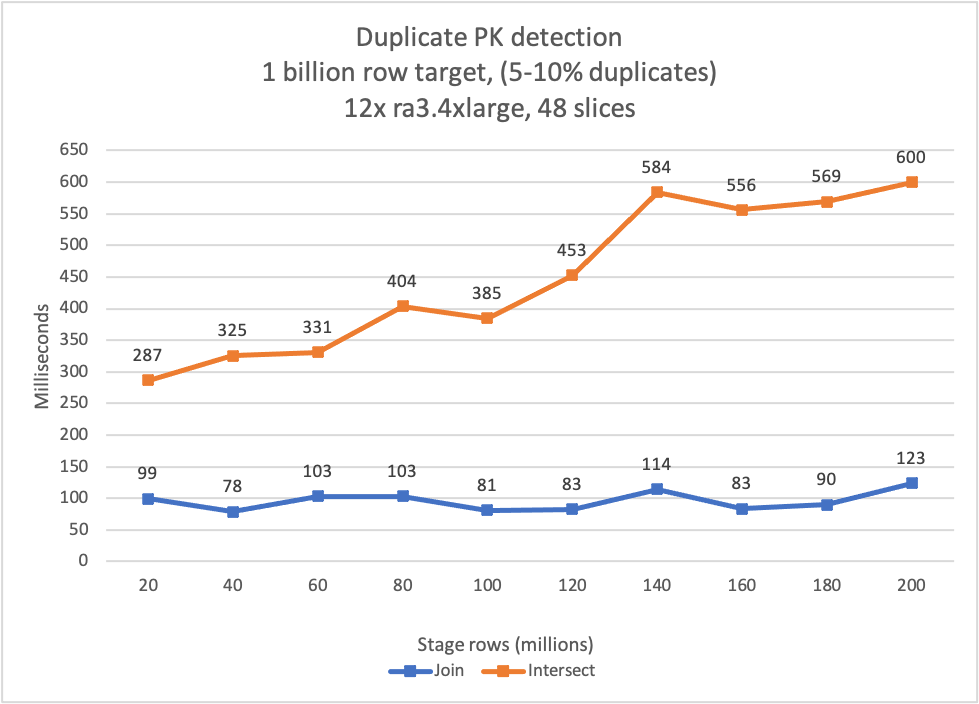
Accelerate your data warehouse migration to Amazon Redshift – Part 6
This is the sixth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift. Check out all the previous posts in this series: […]

Create a most-recent view of your data lake using Amazon Redshift Serverless
Building a robust data lake is very beneficial because it enables organizations have a holistic view of their business and empowers data-driven decisions. The curated layer of a data lake is able to hydrate multiple homogeneous data products, unlocking limitless capabilities to address current and future requirements. However, some concepts of how data lakes work […]