AWS Big Data Blog
Category: AWS Lake Formation

Securely analyze your data with AWS Lake Formation and Amazon QuickSight
Many useful business insights can arise from analyzing customer preferences, behavior, and usage patterns. With this information, businesses can innovate faster and improve the customer experience, leading to better engagement and accelerating product adoption. More and more businesses are looking for ways to securely store and restrict access to customer data, which may include personally […]

How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform
April 2024: This post was reviewed for accuracy. This is a joint blog post co-authored with Anu Jain, Graham Person, and Paul Conroy from JP Morgan Chase. Most modern organizations recognize that their data benefits their entire enterprise. Data has value to the individual business process that produces it, but data’s additional potential can be […]

Manage fine-grained access control using AWS Lake Formation
AWS Lake Formation is a fully managed service that helps you build, secure, and manage data lakes, and provide access control for data in the data lake. Customers across lines of business (LOBs) need a way to manage granular access permissions for different users at the table and column level. Lake Formation helps you manage […]

How FanDuel Group secures personally identifiable information in a data lake using AWS Lake Formation
This post is co-written with Damian Grech from FanDuel FanDuel Group is an innovative sports-tech entertainment company that is changing the way consumers engage with their favorite sports, teams, and leagues. The premier gaming destination in the US, FanDuel Group consists of a portfolio of leading brands across gaming, sports betting, daily fantasy sports, advance-deposit […]

Controlling data lake access across multiple AWS accounts using AWS Lake Formation
When deploying data lakes on AWS, you can use multiple AWS accounts to better separate different projects or lines of business. In this post, we see how the AWS Lake Formation cross-account capabilities simplify securing and managing distributed data lakes across multiple accounts through a centralized approach, providing fine-grained access control to the AWS Glue […]
Managing COVID-19 exposure with crowd tracing
This is a guest blog post by AWS partner Aspire Ventures As we enter winter, with fewer options to be outdoors, our personal choices can impact our risk of contracting the COVID-19 virus even more. The New England Journal of Medicine publication showed real-world examples of the effectiveness of masks and social distancing in mitigating […]

Creating a source to Lakehouse data replication pipe using Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
February 2021 update – Please refer to the post Writing to Apache Hudi tables using AWS Glue Custom Connector to learn about an easier mechanism to write to Hudi tables using AWS Glue Custom Connector. In this post, we include the modified Apache Hudi JARs as an external dependency. The AWS Glue Custom Connector feature […]
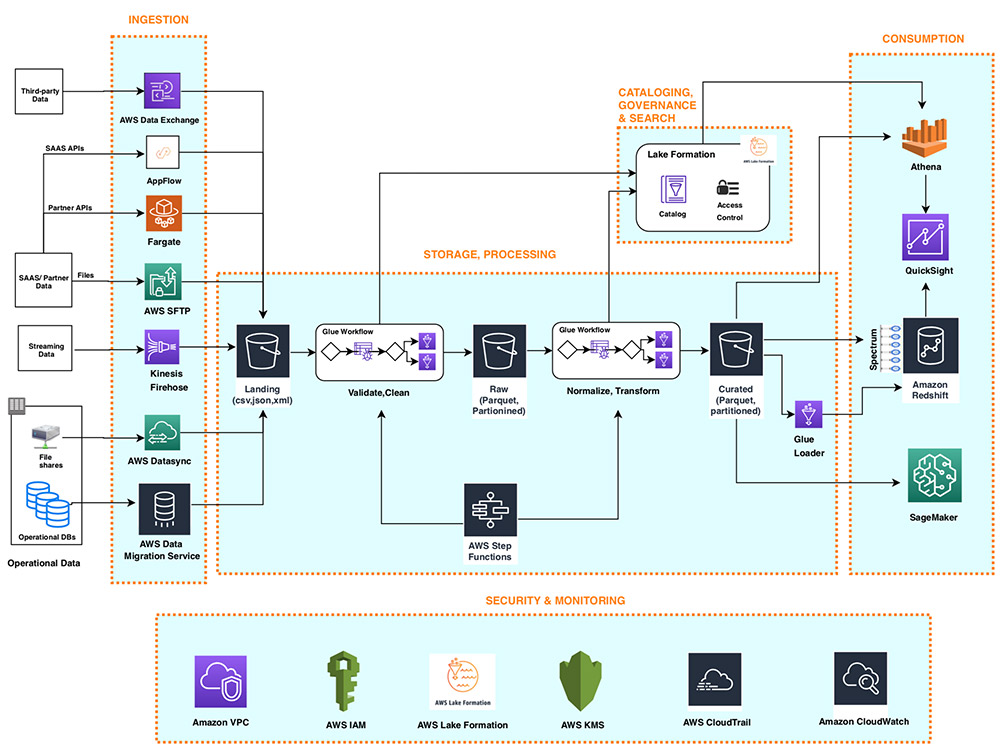
AWS serverless data analytics pipeline reference architecture
May 2025: This post was reviewed and updated for accuracy. Onboarding new data or building new analytics pipelines in traditional analytics architectures typically requires extensive coordination across business, data engineering, and data science and analytics teams to first negotiate requirements, schema, infrastructure capacity needs, and workload management. For a large number of use cases today […]
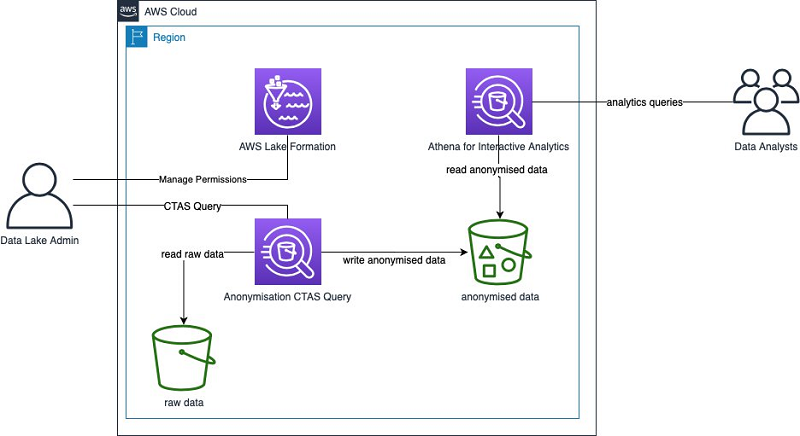
Anonymize and manage data in your data lake with Amazon Athena and AWS Lake Formation
Most organizations have to comply with regulations when dealing with their customer data. For that reason, datasets that contain personally identifiable information (PII) is often anonymized. A common example of PII can be tables and columns that contain personal information about an individual (such as first name and last name) or tables with columns that, if joined with another table, can trace back to an individual. You can use AWS Analytics services to anonymize your datasets. In this post, I describe how to use Amazon Athena to anonymize a dataset. You can then use AWS Lake Formation to provide the right access to the right personas.
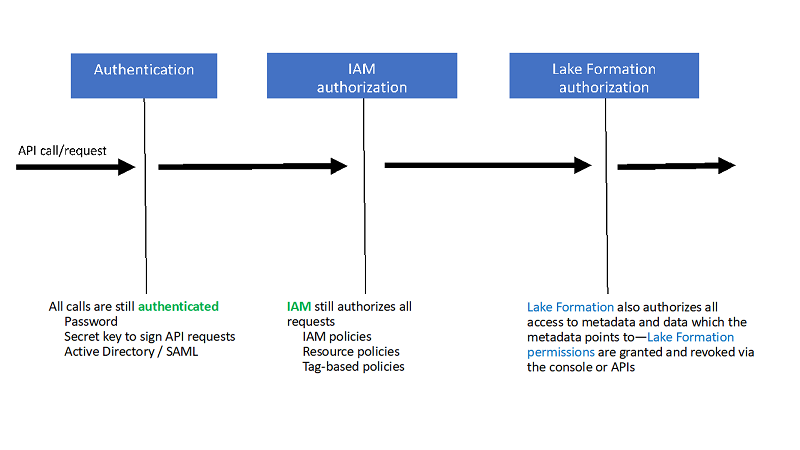
Enable fine-grained data access in Zeppelin Notebook with AWS Lake Formation
This post explores how you can use AWS Lake Formation integration with Amazon EMR (still in beta) to implement fine-grained column-level access controls while using Spark in a Zeppelin Notebook. My previous post Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena showed you a simple use case for extracting any Salesforce object data using AWS Glue and Apache Spark, saving it to Amazon Simple Storage Service (Amazon S3), cataloging the data using the Data Catalog in Glue, and querying it using Amazon Athena.