AWS Big Data Blog
Category: AWS Lake Formation
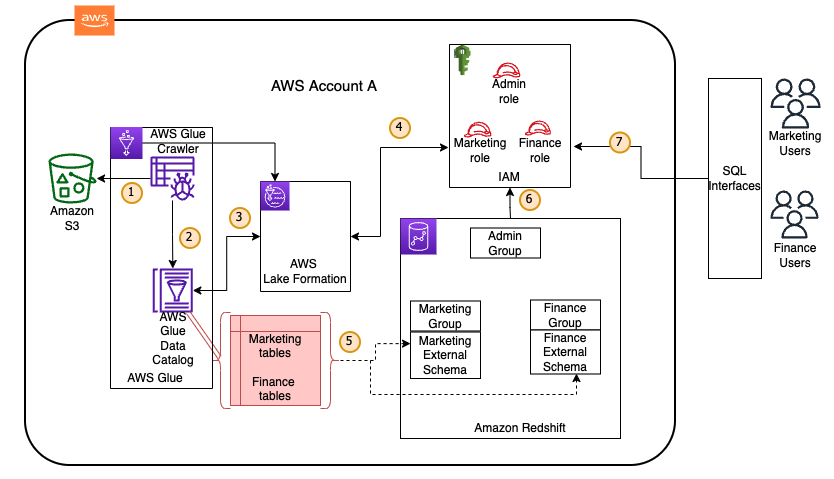
Centralize governance for your data lake using AWS Lake Formation while enabling a modern data architecture with Amazon Redshift Spectrum
Many customers are modernizing their data architecture using Amazon Redshift to enable access to all their data from a central data location. They are looking for a simpler, scalable, and centralized way to define and enforce access policies on their data lakes on Amazon Simple Storage Service (Amazon S3). They want access policies to allow […]

Securely share your data across AWS accounts using AWS Lake Formation
Data lakes have become very popular with organizations that want a centralized repository that allows you to store all your structured data and unstructured data at any scale. Because data is stored as is, there is no need to convert it to a predefined schema in advance. When you have new business use cases, you […]
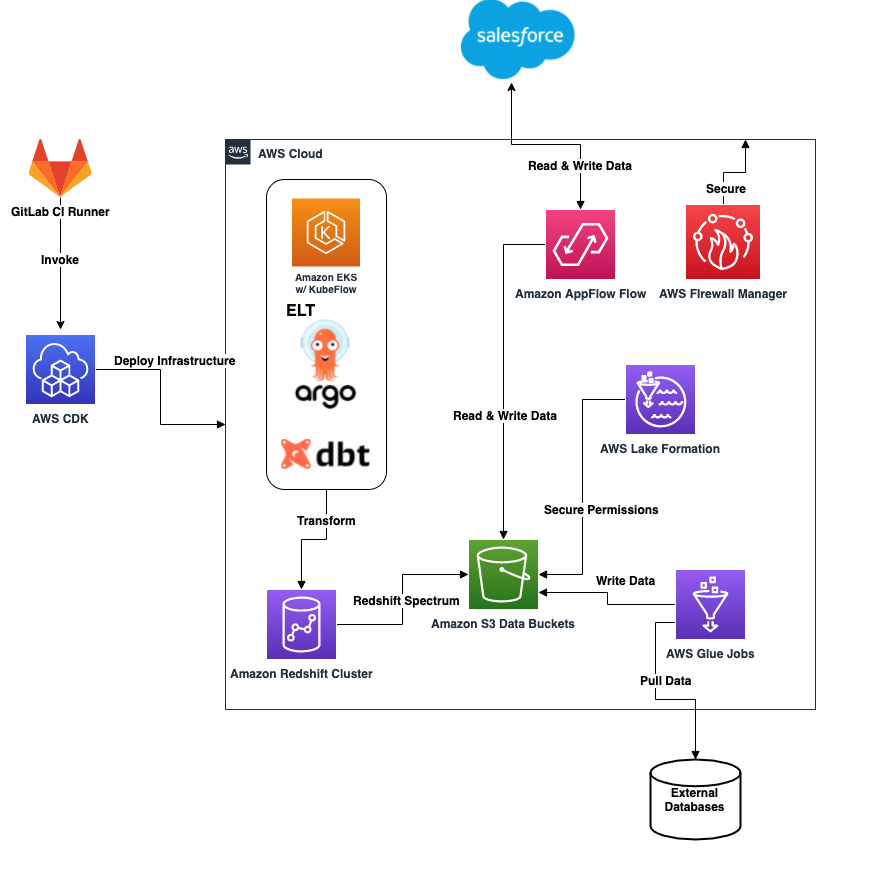
Build a modern data architecture on AWS with Amazon AppFlow, AWS Lake Formation, and Amazon Redshift
This is a guest post written by Dr. Yannick Misteli, lead cloud platform and ML engineering in global product strategy (GPS) at Roche. Recently the Roche Data Insights (RDI) initiative was launched to achieve our vision using new ways of working and collaboration in order to build shared, interoperable data & insights with federated governance. […]

Effective data lakes using AWS Lake Formation, Part 2: Creating a governed table for streaming data sources
February 2023: The content of this blog post can be now be found on AWS Lake Formation public documentation. Please refer to it instead. We announced the general availability of AWS Lake Formation transactions, row-level security, and acceleration at AWS re:Invent 2021. In Part 1 of this series, we explained how to set up a […]

Use Amazon Athena and Amazon QuickSight in a cross-account environment
This blog post was last reviewed and updated in June 2025. Many AWS customers use a multi-account strategy to host applications for different departments within the same company. However, you might deploy services like Amazon QuickSight using a single-account approach, which raises challenges when you need to use QuickSight in combination with Amazon Athena to […]

Integral Ad Science secures self-service data lake using AWS Lake Formation
This post is co-written with Mat Sharpe, Technical Lead, AWS & Systems Engineering from Integral Ad Science. Integral Ad Science (IAS) is a global leader in digital media quality. The company’s mission is to be the global benchmark for trust and transparency in digital media quality for the world’s leading brands, publishers, and platforms. IAS […]

Implement anti-money laundering solutions on AWS
The detection and prevention of financial crime continues to be an important priority for banks. Over the past 10 years, the level of activity in financial crimes compliance in financial services has expanded significantly, with regulators around the globe taking scores of enforcement actions and levying $36 billion in fines. Apart from the fines, the […]

How MOIA built a fully automated GDPR compliant data lake using AWS Lake Formation, AWS Glue, and AWS CodePipeline
This is a guest blog post co-written by Leonardo Pêpe, a Data Engineer at MOIA. MOIA is an independent company of the Volkswagen Group with locations in Berlin and Hamburg, and operates its own ride pooling services in Hamburg and Hanover. The company was founded in 2016 and develops mobility services independently or in partnership […]

Easily manage your data lake at scale using AWS Lake Formation Tag-based access control
Thousands of customers are building petabyte-scale data lakes on AWS. Many of these customers use AWS Lake Formation to easily build and share their data lakes across the organization. As the number of tables and users increase, data stewards and administrators are looking for ways to manage permissions on data lakes easily at scale. Customers […]

Effective data lakes using AWS Lake Formation, Part 2: Securing data lakes with row-level access control
Apr 2023: This post was updated with the latest dataset and the updated CloudFormation template. July 2023: This post was reviewed for accuracy. Increasingly, customers are looking at data lakes as a core part of their strategy to democratize data access across the organization. Data lakes enable you to handle petabytes and exabytes of data […]