AWS Big Data Blog
Integral Ad Science secures self-service data lake using AWS Lake Formation
This post is co-written with Mat Sharpe, Technical Lead, AWS & Systems Engineering from Integral Ad Science.
Integral Ad Science (IAS) is a global leader in digital media quality. The company’s mission is to be the global benchmark for trust and transparency in digital media quality for the world’s leading brands, publishers, and platforms. IAS does this through data-driven technologies with actionable real-time signals and insight.
In this post, we discuss how IAS uses AWS Lake Formation and Amazon Athena to efficiently manage governance and security of data.
The challenge
IAS processes over 100 billion web transactions per day. With strong growth and changing seasonality, IAS needed a solution to reduce cost, eliminate idle capacity during low utilization periods, and maximize data processing speeds during peaks to ensure timely insights for customers.
In 2020, IAS deployed a data lake in AWS, storing data in Amazon Simple Storage Service (Amazon S3), cataloging its metadata in the AWS Glue Data Catalog, ingesting and processing using Amazon EMR, and using Athena to query and analyze the data. IAS wanted to create a unified data platform to meet its business requirements. Additionally, IAS wanted to enable self-service analytics for customers and users across multiple business units, while maintaining critical controls over data privacy and compliance with regulations such as GDPR and CCPA. To accomplish this, IAS needed to securely ingest and organize real-time and batch datasets, as well as secure and govern sensitive customer data.
To meet the dynamic nature of IAS’s data and use cases, the team needed a solution that could define access controls by attribute, such as classification of data and job function. IAS processes significant volumes of data and this continues to grow. To support the volume of data, IAS needed the governance solution to scale in order to create and secure many new daily datasets. This meant IAS could enable self-service access to data from different tools, such as development notebooks, the AWS Management Console, and business intelligence and query tools.
To address these needs, IAS evaluated several approaches, including a manual ticket-based onboarding process to define permissions on new datasets, many different AWS Identity and Access Management (IAM) policies, and an AWS Lambda based approach to automate defining Lake Formation table and column permissions triggered by changes in security requirements and the arrival of new datasets.
Although these approaches worked, they were complex and didn’t support the self-service experience that IAS data analysts required.
Solution overview
IAS selected Lake Formation, Athena, and Okta to solve this challenge. The following architectural diagram shows how the company chose to secure its data lake.

The solution needed to support data producers and consumers in multiple AWS accounts. For brevity, this diagram shows a central data lake producer that includes a set of S3 buckets for raw and processed data. Amazon EMR is used to ingest and process the data, and all metadata is cataloged in the data catalog. The data lake consumer account uses Lake Formation to define fine-grained permissions on datasets shared by the producer account; users logging in through Okta can run queries using Athena and be authorized by Lake Formation.
Lake Formation enables column-level control, and all Amazon S3 access is provisioned via a Lake Formation data access role in the query account, ensuring only that service can access the data. Each business unit with access to the data lake is provisioned with an IAM role that only allows limited access to:
- That business unit’s Athena workgroup
- That workgroup’s query output bucket
- The
lakeformation:GetDataAccessAPI
Because Lake Formation manages all the data access and permissions, the configuration of the user’s role policy in IAM becomes very straightforward. By defining an Athena workgroup per business unit, IAS also takes advantage of assigning per-department billing tags and query limits to help with cost management.
Define a tag strategy
IAS commonly deals with two types of data: data generated by the company and data from third parties. The latter usually includes contractual stipulations on privacy and use.
Some data sets require even tighter controls, and defining a tag strategy is one key way that IAS ensures compliance with data privacy standards. With the tag-based access controls in Lake Formation IAS can define a set of tags within an ontology that is assigned to tables and columns. This ensures users understand available data and whether or not they have access. It also helps IAS manage privacy permissions across numerous tables with new ones added every day.
At a simplistic level, we can define policy tags for class with private and non-private, and for owner with internal and partner.
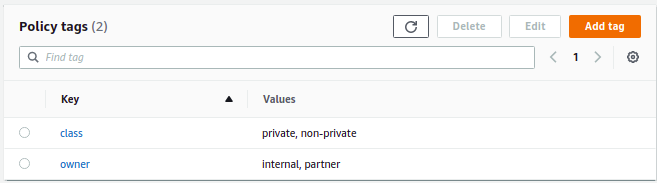
As we progressed, our tagging ontology evolved to include individual data owners and data sources within our product portfolio.
Apply tags to data assets
After IAS defined the tag ontology, the team applied tags at the database, table, and column level to manage permissions. Tags are inherited, so they only need to be applied at the highest level. For example, IAS applied the owner and class tags at the database level and relied on inheritance to propagate the tags to all the underlying tables and columns. The following diagram shows how IAS activated a tagging strategy to distinguish between internal and partner datasets , while classifying sensitive information within these datasets.
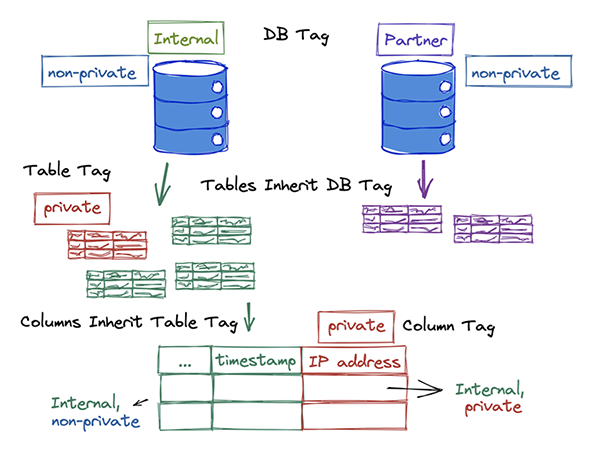
Only a small number of columns contain sensitive information; IAS relied on inheritance to apply a non-private tag to the majority of the database objects and then overrode it with a private tag on a per-column basis.
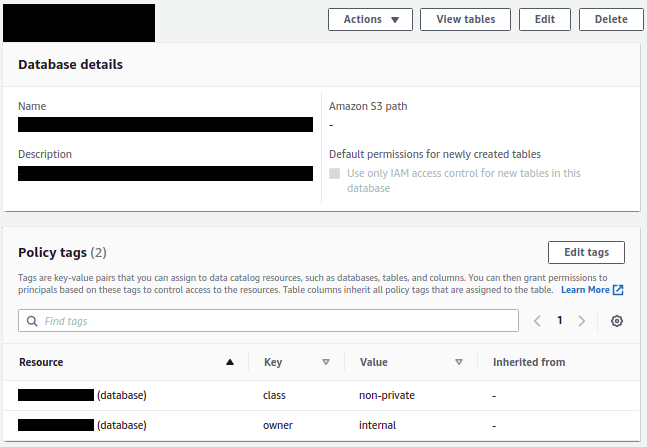
The following screenshot shows the tags applied to a database on the Lake Formation console.
With its global scale, IAS needed a way to automate how tags are applied to datasets. The team experimented with various options including string matching on column names, but the results were unpredictable in situations where unexpected column names are used (ipaddress vs. ip_address, for example). Ultimately, IAS incorporated metadata tagging into its existing infrastructure as code (IaC) process, which gets applied as part of infrastructure updates.
Define fine-grained permissions
The final piece of the puzzle was to define permission rules to associate with tagged resources. The initial data lake deployment involved creating permission rules for every database and table, with column exclusions as necessary. Although these were generated programmatically, it added significant complexity when the team needed to troubleshoot access issues. With Lake Formation tag-based access controls, IAS reduced hundreds of permission rules down to precisely two rules, as shown in the following screenshot.

When using multiple tags, the expressions are logically ANDed together. The preceding statements permit access only to data tagged non-private and owned by internal.
Tags allowed IAS to simplify permission rules, making it easy to understand, troubleshoot, and audit access. The ability to easily audit which datasets include sensitive information and who within the organization has access to them made it easy to comply with data privacy regulations.
Benefits
This solution provides self-service analytics to IAS data engineers, analysts, and data scientists. Internal users can query the data lake with their choice of tools, such as Athena, while maintaining strong governance and auditing. The new approach using Lake Formation tag-based access controls reduces the integration code and manual controls required. The solution provides the following additional benefits:
- Meets security requirements by providing column-level controls for data
- Significantly reduces permission complexity
- Reduces time to audit data security and troubleshoot permissions
- Deploys data classification using existing IaC processes
- Reduces the time it takes to onboard data users including engineers, analysts, and scientists
Conclusion
When IAS started this journey, the company was looking for a fully managed solution that would enable self-service analytics while meeting stringent data access policies. Lake Formation provided IAS with the capabilities needed to deliver on this promise for its employees. With tag-based access controls, IAS optimized the solution by reducing the number of permission rules from hundreds down to a few, making it even easier to manage and audit. IAS continues to analyze data using more tools governed by Lake Formation.
About the Authors
 Mat Sharpe is the Technical Lead, AWS & Systems Engineering at IAS where he is responsible for the company’s AWS infrastructure and guiding the technical teams in their cloud journey. He is based in New York.
Mat Sharpe is the Technical Lead, AWS & Systems Engineering at IAS where he is responsible for the company’s AWS infrastructure and guiding the technical teams in their cloud journey. He is based in New York.
 Brian Maguire is a Solution Architect at Amazon Web Services, where he is focused on helping customers build their ideas in the cloud. He is a technologist, writer, teacher, and student who loves learning. Brian is the co-author of the book Scalable Data Streaming with Amazon Kinesis.
Brian Maguire is a Solution Architect at Amazon Web Services, where he is focused on helping customers build their ideas in the cloud. He is a technologist, writer, teacher, and student who loves learning. Brian is the co-author of the book Scalable Data Streaming with Amazon Kinesis.
 Danny Gagne is a Solutions Architect at Amazon Web Services. He has extensive experience in the design and implementation of large-scale high-performance analysis systems, and is the co-author of the book Scalable Data Streaming with Amazon Kinesis. He lives in New York City.
Danny Gagne is a Solutions Architect at Amazon Web Services. He has extensive experience in the design and implementation of large-scale high-performance analysis systems, and is the co-author of the book Scalable Data Streaming with Amazon Kinesis. He lives in New York City.