AWS Big Data Blog
How MOIA built a fully automated GDPR compliant data lake using AWS Lake Formation, AWS Glue, and AWS CodePipeline
This is a guest blog post co-written by Leonardo Pêpe, a Data Engineer at MOIA.
MOIA is an independent company of the Volkswagen Group with locations in Berlin and Hamburg, and operates its own ride pooling services in Hamburg and Hanover. The company was founded in 2016 and develops mobility services independently or in partnership with cities and existing transport systems. MOIA’s focus is on ride pooling and the holistic development of the software and hardware for it. In October 2017, MOIA started a pilot project in Hanover to test a ride pooling service, which was brought into public operation in July 2018. MOIA covers the entire value chain in the area of ride pooling. MOIA has developed a ridesharing system to avoid individual car traffic and use the road infrastructure more efficiently.
In this post, we discuss how MOIA uses AWS Lake Formation, AWS Glue, and AWS CodePipeline to store and process gigabytes of data on a daily basis to serve 20 different teams with individual user data access and implement fine-grained control of the data lake to comply with General Data Protection Regulation (GDPR) guidelines. This involves controlling access to data at a granular level. The solution enables MOIA’s fast pace of innovation to automatically adapt user permissions to new tables and datasets as they become available.
Background
Each MOIA vehicle can carry six passengers. Customers interact with the MOIA app to book a trip, cancel a trip, and give feedback. The highly distributed system prepares multiple offers to reach their destination with different pickup points and prices. Customers select an option and are picked up from their chosen location. All interactions between the customers and the app, as well as all the interactions between internal components and systems (the backend’s and vehicle’s IoT components), are sent to MOIA’s data lake.
Data from the vehicle, app, and backend must be centralized to have the synchronization between trips planned and implemented, and then to collect passenger feedback. To provide different pricing and routing options, MOIA needed centralized data. MOIA decided to build and secure its Amazon Simple Storage Service (Amazon S3) based Data Lake using AWS Lake Formation.
Different MOIA teams that includes Data Analysts, Data Scientists and Data Engineers need to access centralized data from different sources for the development and operations of the application workloads. It’s a legal requirement to control the access and format of the data to these different teams. The app development team needs to understand customer feedback in an anonymized way, pricing-related data must be accessed only by the business analytics team, vehicle data is meant to be used only by the vehicle maintenance team, and the routing team needs access to customer location and destination.
Architecture overview
The following diagram illustrates MOIA solution architecture.
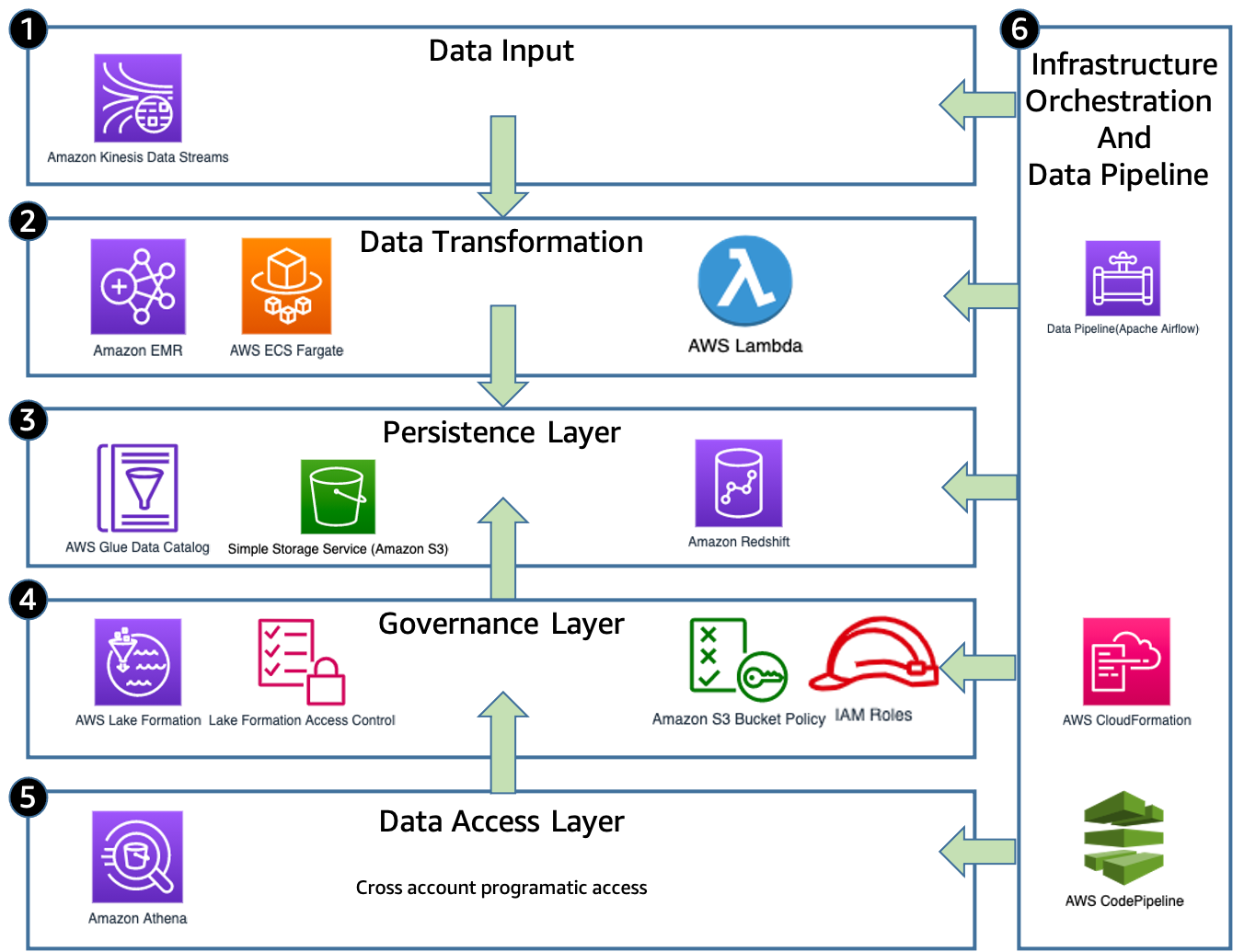
The solution has the following components:
- Data input – The apps, backend, and IoT devices are continuously streaming event messages via Amazon Kinesis Data Streams in a nested information in a JSON format.
- Data transformation – When the raw data is received, the data pipeline orchestrator (Apache Airflow) starts the data transformation jobs to meet requirements for respective data formats. Amazon EMR, AWS Lambda, or AWS Fargate cleans, transforms, and loads the events in the S3 data lake.
- Persistence layer – After the data is transformed and normalized, AWS Glue crawlers classify the data to determine the format, schema, and associated properties. They group data into tables or partitions and write metadata to the AWS Glue Data Catalog based on the structured partitions created in Amazon S3. The data is written on Amazon S3 partitioned by its event type and timestamp so it can be easily accessed via Amazon Athena and the correct permissions can be applied using Lake Formation. The crawlers are run at a fixed interval in accordance with the batch jobs, so no manual runs are required.
- Governance layer – Access on the data lake is managed using the Lake Formation governance layer. MOIA uses Lake Formation to centrally define security, governance, and auditing policies in one place. These policies are consistently implemented, which eliminates the need to manually configure them across security services like AWS Identity and Access Management (IAM), AWS Key Management Service (AWS KMS), storage services like Amazon S3, or analytics and machine learning (ML) services like Amazon Redshift, Athena, Amazon EMR for Apache Spark. Lake Formation reduces the effort in configuring policies across services and provides consistent assistance for GDPR requirements and compliance. When a user makes a request to access Data Catalog resources or underlying data from the data lake, for the request to succeed, it must pass permission checks by both IAM and Lake Formation. Lake Formation permissions control access to Data Catalog resources, Amazon S3 locations, and the underlying data at those locations. User permissions to the data on the table, row, or column level are defined in Lake Formation, so that users only access the data if they’re authorized.
- Data access layer – After the flattened and structured data is available to be accessed by the data analysts, scientists, and engineers they can use Amazon Redshift or Athena to perform SQL analysis, or AWS Data Wrangler and Apache Spark to perform programmatic analysis and build ML use cases.
- Infrastructure orchestration and data pipeline – After the data is ingested and transformed, the infrastructure orchestration layer (CodePipeline and Lake Formation) creates or updates the governance layer with the proper and predefined permissions periodically every hour (see more about the automation in the governance layer later in this post).
Governance challenge
MOIA wants to evolve their ML models for routing, demand prediction, and business models continuously. This requires MOIA to constantly review models and update them, therefore power users such as data administrators and engineers frequently redesign the table schemas in the AWS Glue Data Catalog as part of the data engineering workflow. This highly dynamic metadata transformation requires an equally dynamic governance layer pipeline that can assign the right user permissions to all tables and adapt to these changes transparently without disruptions to end-users. Due to GDPR requirements, there is no room for error, and manual work is required to assign the right permissions according to GDPR compliance on the tables in the data lake with many terabytes of data. Without automation, many developers are needed for administration; this adds human error into the workflows, which is not acceptable. Manual administration and access management isn’t a scalable solution. MOIA needed to innovate faster with GDPR compliance with a small team of developers.
Data schema and data structure often changes at MOIA, resulting in new tables being created in the data lake. To guarantee that new tables inherit the permissions granted to the same group of users who already have access to the entire database, MOIA uses an automated process that grants Lake Formation permission to newly created tables, columns, and databases, as described in the next section.
Solution overview
The following diagram illustrates the continuous deployment loop using AWS CloudFormation.
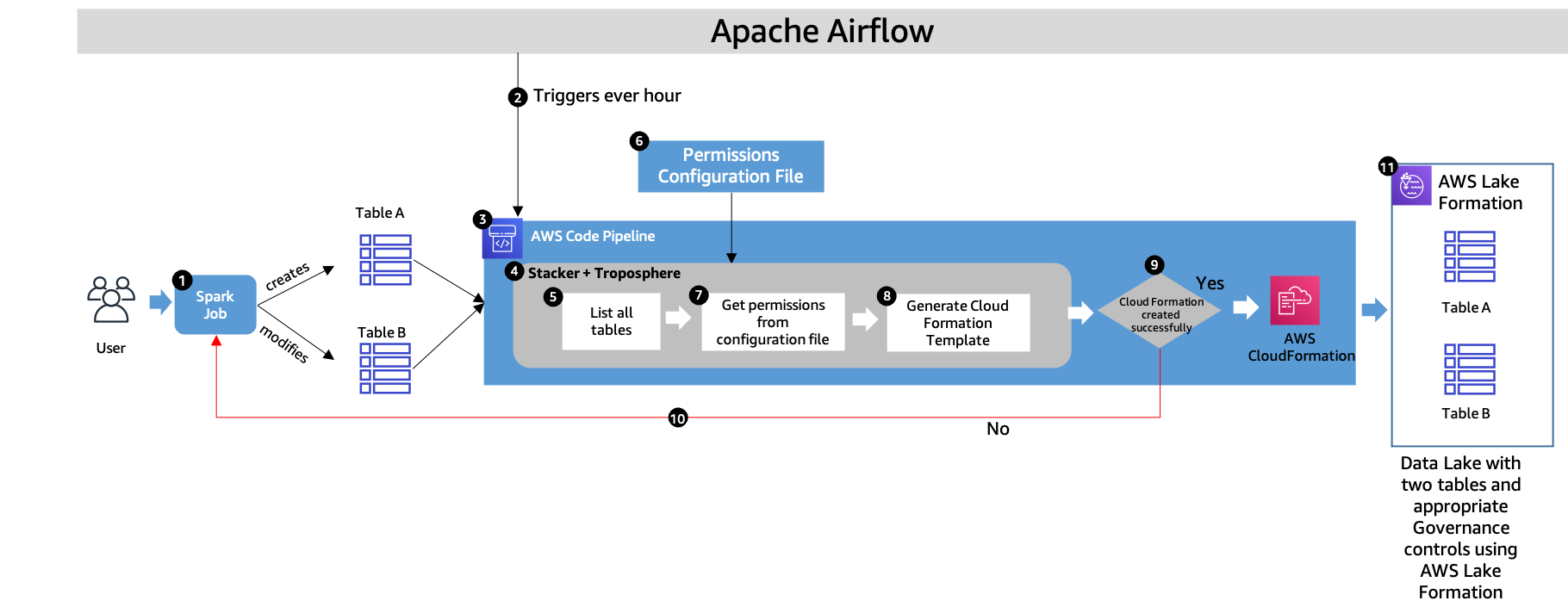
The workflow contains the following steps:
- MOIA data scientists and engineers create or modify new tables to evolve the business and ML models. This results in new tables or changes in the existing schema of the table.
- The data pipeline is orchestrated via Apache Airflow, which controls the whole cycle of ingestion, cleansing, and data transformation using Spark jobs (as shown in Step 1). When the data is in its desired format and state, Apache Airflow triggers the AWS Glue crawler job to discover the data schema in the S3 bucket and add the new partitions to the Data Catalog. Apache Airflow also triggers CodePipeline to assign the right permissions on all the tables.
- Apache Airflow triggers CodePipeline every hour, which uses MOIA’s libraries to discover the new tables, columns, and databases, and grants Lake Formation permissions in the AWS CloudFormation template for all tables, including new and modified. This orchestration layer ensures Lake Formation permissions are granted. Without this step, nobody can access new tables, and new data isn’t visible to data scientists, business analysts, and others who need it.
- MOIA uses Stacker and Troposphere to identify all the tables, assign the tables the right permissions, and deploy the CloudFormation stack. Troposphere is the infrastructure as code (IaC) framework that renders the CloudFormation templates, and stacker helps with the parameterization and deployment of the templates on AWS. Stacker also helps produce reusable templates in the form of blueprints as pure Python code, which can be easily parameterized using YAML files. The Python code uses Boto3 clients to lookup the Data Catalog and search for databases and tables.
- The stacker blueprint libraries developed by MOIA (which internally use Boto3 and troposphere) are used to discover newly created databases or tables in the Data Catalog.
- A Permissions configuration file allows MOIA to predefine data lake tables (Can be a wildcard indicating all tables available in one database) and specific personas who have access to these tables. These roles are split into different categories called lake personas, and have specific access levels. Example lake personas include data domain engineers, data domain technical users, data administrators, and data analysts. Users and their permissions are defined in the file. In case access to personally identifiable information (PII) data is granted, the GDPR officer ensures that a record of processing activities is in place and the usage of personal data is documented according to the law.
- MOIA uses stacker to read the predefined permissions file, and uses the customized stacker blueprints library containing the logic to assign permissions to lake personas for each of the tables discovered in Step 5.
- The discovered and modified tables are matched with predefined permissions in Step 6 and Step 7. Stacker uses YAML format as the input for the CloudFormation template parameters to define users and data access permissions. These parameters are related to the user’s roles and define access to the tables. Based on this, MOIA creates a customized stacker that creates AWS CloudFormation resources dynamically. The following are the example stacks in AWS CloudFormation:
- data-lake-domain-database – Holds all resources that are relevant during the creation of the database, which includes lake permissions at the database level that allow the domain database admin personas to perform operations in the database.
- data-lake-domain-crawler – Scans Amazon S3 constantly to discover and create new tables and updates.
- data-lake-lake-table-permissions – Uses Boto3 combined with troposphere to list the available tables and grant lake permissions to the domain roles that access it.
This way, new CloudFormation templates are created, containing permissions for new or modified tables. This process guarantees a fully automated governance layer for the data lake. The generated CloudFormation template contains Lake Formation permission resources for each table, database, or column. The process of managing Lake Formation permissions on Data Catalog databases, tables, and columns is simplified by granting Data Catalog permissions using the Lake Formation tag-based access control method. The advantage of generating a CloudFormation template is audibility. When the new version of the CloudFormation stack is prepared with an access control set on new or modified tables, administrators can compare that stack with the older version to discover newly prepared and modified tables. MOIA can view the differences via the AWS CloudFormation console before new stack deployment.
- Either the CloudFormation stack is deployed in the account with the right permissions for all users, or a stack deployment failure notice is sent to the developers via a Slack channel (Step 10). This ensures the visibility in the deployment process and failed pipelines in permission assignment.
- Whenever the pipeline fails, MOIA receives the notification via Slack so the engineers can promptly fix the errors. This loop is very important to guarantee that whenever the schema changes, those changes are reflected in the data lake without manual intervention.
- Following this automated pipeline, all the tables are assigned right permissions.
Benefits
This solution delivers the following benefits:
- Automated enforcement of data access permissions allows people to access the data without manual interventions in a scalable way. With automation, 1,000 hours of manual work are saved every year.
- The GDPR team does the assessment internally every month. The GDPR team constantly provides guidance and approves each change in permissions. This audit trail for records of processing activities is automated with the help of Lake Formation (otherwise it needs a dedicated human resource).
- The automated workflow of permission assignment is integrated into existing CI/CD processes, resulting in faster onboarding of new teams, features, and dataset releases. An average of 48 releases are done each month (including major and minor version releases and new event types). Onboarding new teams and forming internal new teams is very easy now.
- This solution enables you to create a data lake using IaC processes that are easy and GDPR-compliant.
Conclusion
MOIA has created scalable, automated, and versioned permissions with a GDPR-supported, governed data lake using Lake Formation. This solution helps them bring new features and models to market faster, and reduces administrative and repetitive tasks. MOIA can focus on 48 average releases every month, contributing to a great customer experience and new data insights.
About the Authors
 Leonardo Pêpe is a Data Engineer at MOIA. With a strong background in infrastructure and application support and operations, he is immersed in the DevOps philosophy. He’s helping MOIA build automated solutions for its data platform and enabling the teams to be more data-driven and agile. Outside of MOIA, Leonardo enjoys nature, Jiu-Jitsu and martial arts, and explores the good of life with his family.
Leonardo Pêpe is a Data Engineer at MOIA. With a strong background in infrastructure and application support and operations, he is immersed in the DevOps philosophy. He’s helping MOIA build automated solutions for its data platform and enabling the teams to be more data-driven and agile. Outside of MOIA, Leonardo enjoys nature, Jiu-Jitsu and martial arts, and explores the good of life with his family.
 Sushant Dhamnekar is a Solutions Architect at AWS. As a trusted advisor, Sushant helps automotive customers to build highly scalable, flexible, and resilient cloud architectures, and helps them follow the best practices around advanced cloud-based solutions. Outside of work, Sushant enjoys hiking, food, travel, and CrossFit workouts.
Sushant Dhamnekar is a Solutions Architect at AWS. As a trusted advisor, Sushant helps automotive customers to build highly scalable, flexible, and resilient cloud architectures, and helps them follow the best practices around advanced cloud-based solutions. Outside of work, Sushant enjoys hiking, food, travel, and CrossFit workouts.
 Shiv Narayanan is Global Business Development Manager for Data Lakes and Analytics solutions at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern data platforms. Shiv loves music, travel, food and trying out new tech.
Shiv Narayanan is Global Business Development Manager for Data Lakes and Analytics solutions at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern data platforms. Shiv loves music, travel, food and trying out new tech.