AWS Big Data Blog
Category: AWS Big Data

Controlling data lake access across multiple AWS accounts using AWS Lake Formation
When deploying data lakes on AWS, you can use multiple AWS accounts to better separate different projects or lines of business. In this post, we see how the AWS Lake Formation cross-account capabilities simplify securing and managing distributed data lakes across multiple accounts through a centralized approach, providing fine-grained access control to the AWS Glue […]

New in Amazon QuickSight – session capacity pricing for large scale deployments, embedding in public websites, and developer portal for embedded analytics
Amazon QuickSight Enterprise edition now offers a new, session capacity-based pricing model starting at $250/month, with annual commitment options that provide scalable pricing for embedded analytics and BI rollouts to 100s of 1000s of users. QuickSight now also supports embedding dashboards in apps, websites, and wikis without the need to provision and manage users (readers) […]

Keeping your data lake clean and compliant with Amazon Athena
June 2025: This post has been reviewed for accuracy and the following updates have been made: added new function to retrieve SQL query in the Lambda code; upgraded Python’s run time and version of sqlparse in the Lambda deployment package; added and removed actions in the Lambda policy; updated the CloudFormation template to reflect policy […]

Auditing, inspecting, and visualizing Amazon Athena usage and cost
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. It’s a serverless platform with no need to set up or manage infrastructure. Athena scales automatically—running queries in parallel—so results are fast, even with large datasets and complex queries. You […]

Best practices for consuming Amazon Kinesis Data Streams using AWS Lambda
November 2024: This post was reviewed and updated for accuracy. Many organizations are processing and analyzing clickstream data in real time from customer-facing applications to look for new business opportunities and identify security incidents in real time. A common practice is to consolidate and enrich logs from applications and servers in real time to proactively […]
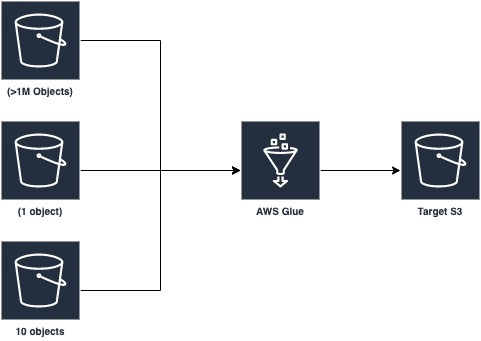
Optimizing Spark applications with workload partitioning in AWS Glue
AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. This posts discusses a new AWS Glue Spark runtime optimization that helps developers of Apache Spark applications and ETL jobs, big data architects, […]

Data preprocessing for machine learning on Amazon EMR made easy with AWS Glue DataBrew
The machine learning (ML) lifecycle consists of several key phases: data collection, data preparation, feature engineering, model training, model evaluation, and model deployment. The data preparation and feature engineering phases ensure an ML model is given high-quality data that is relevant to the model’s purpose. Because most raw datasets require multiple cleaning steps (such as […]

Orchestrating analytics jobs by running Amazon EMR Notebooks programmatically
Amazon EMR is a big data service offered by AWS to run Apache Spark and other open-source applications on AWS in a cost-effective manner. Amazon EMR Notebooks is a managed environment based on Jupyter Notebook that allows data scientists, analysts, and developers to prepare and visualize data, collaborate with peers, build applications, and perform interactive […]

Managing COVID-19 exposure with crowd tracing
This is a guest blog post by AWS partner Aspire Ventures As we enter winter, with fewer options to be outdoors, our personal choices can impact our risk of contracting the COVID-19 virus even more. The New England Journal of Medicine publication showed real-world examples of the effectiveness of masks and social distancing in mitigating […]

Building Python modules from a wheel for Spark ETL workloads using AWS Glue 2.0
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue 2.0 features an upgraded infrastructure for running Apache Spark ETL jobs in AWS Glue with reduced startup times. With reduced startup delay time and lower minimum billing duration, overall […]