AWS Big Data Blog
Optimizing Spark applications with workload partitioning in AWS Glue
AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. This posts discusses a new AWS Glue Spark runtime optimization that helps developers of Apache Spark applications and ETL jobs, big data architects, data engineers, and business analysts scale their data processing and batch jobs running on AWS Glue automatically.
Customers use Spark for a wide variety of ETL and analytics workloads on datasets with diverse characteristics. They want to ensure fast and error-free execution of these workloads. Errors in Spark applications commonly arise from inefficient Spark scripts, distributed in-memory execution of large-scale transformations, and dataset abnormalities. Spark’s distributed execution uses a Master/Slave architecture with driver and executor processes perform parallel computation over partitions of input dataset. Inspite of this data-parallel architecture, Spark applications commonly run into out-of-memory (OOM) exceptions on driver and executors due to skew in input data, large number of input files, or large joins and shuffle operations.
In this blog post, we introduce a new Spark runtime optimization on Glue – Workload/Input Partitioning for data lakes built on Amazon S3. Customers on Glue have been able to automatically track the files and partitions processed in a Spark application using Glue job bookmarks. Now, this feature gives them another simple yet powerful construct to bound the execution of their Spark applications. Bounded execution allows customers to partition their workloads by limiting the maximum number of files or dataset size processed incrementally within Glue Spark applications that can be orchestrated sequentially or in parallel.
Specifically, this feature makes it easy for customers to make their complex ETL pipelines significantly more resilient to errors. This is achieved by breaking down the monolithic Spark applications processing a large backlog of tens to hundreds of millions of files into simpler modular Spark applications that can process a bounded number of files or dataset size incrementally.
This Spark runtime optimization also works together with existing Glue features such as push down predicates, AWS Glue S3 lister, grouping, exclusions for S3 paths, and other optimizations .
Setup and Use Cases
One of the common use cases of data warehousing is processing a large number of records from a fact table (employees, sales or items) and joining the same with multiple dimension tables (departments, stores, catalog), and loading the output to the final destination. The following diagram illustrates an ETL architecture used commonly by several customers.
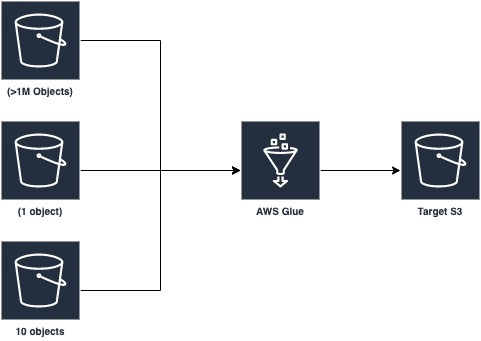
ETL pipelines using Apache Spark applications for this use case or similar backlog ingestion can encounter 3 common errors. First, the Spark driver can run out-of-memory while listing millions of files in S3 for the fact table. Second, the Spark executors can run out-of-memory if there is skew in the dataset resulting in imbalanced shuffles or join operations across the different partitions of the fact table. Third, any data abnormality or malformed records can cause the Spark application to fail during any of the three stages – read from S3, application of join transform, or write to S3. In this blog post, we would show how workload partitioning can help you mitigate these errors by bounding the execution of the Spark application, and also detect abnormalities or skews in your data.
Our setup uses a fact table consisting of employee badge access data stored in S3 with 1.34 million objects and files, and a record count of 1.3 billion. This dataset is joined with two other datasets (dimension tables – employee and badge data), which are smaller in size, one with 107 records and another with a record count of 12,249 in 10 files. We use native Spark 2.4 and Python 3. We will monitor the memory profile of Spark driver and executors over time. We find that both the Spark driver and executors get prone to OOM exceptions. We would use the AWS Glue Workload Partitioning feature to show how we can automatically mitigate those errors automatically with minimal changes to the Spark application.
We enable AWS Glue job bookmarks with the use of AWS Glue Dynamic Frames as it helps to incrementally load unprocessed data from S3. Vanilla Spark applications using Spark Dataframes do not support Glue job bookmarks and therefore can not incrementally load data out-of-the-box. We find that Spark applications using both Glue Dynamic Frames and Spark Dataframes can run into the above 3 error scenarios while loading tables with large number of input files or distributed transformations such as join resulting in large shuffles. Following is the code snippet of the Spark application used for our setup.
Spark application without bounded execution
When we ran the Spark application to join three datasets with their common keys, it ran for about 4 hours to read and iterate over the large dataset. It eventually failed with a Spark driver OOM error:
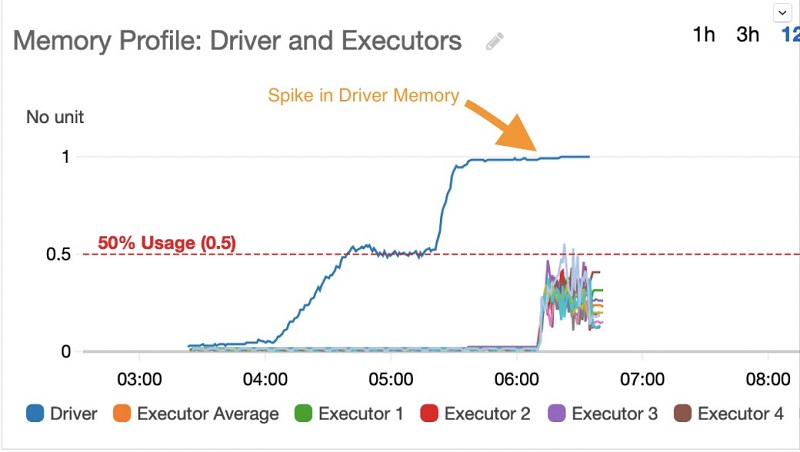
When checking the memory profile of the driver and executors (see the following graph) using Glue job metrics, it’s apparent that the driver memory utilization gradually increases over the 50% threshold as it reads data from a large data source, and finally goes out of memory while trying to join with the two smaller datasets.
Rerunning the Spark application with bounded execution
To overcome this Spark driver OOM, we modified the previous code to use workload partitioning by simply including the boundedFiles parameter as an additional_options (see the following code). In this changed code, we used the job to process 100,000 files from datasource0. Bounded execution works in conjunction with job bookmarks. Job bookmarks tracks processed files and partitions based on timestamp and path hashes. In addition, bounded execution applies filters to track files and partitions with a specified bound on the number of files or the dataset size.
After this change, the driver memory utilization stayed consistently low, with a peak utilization of about 26%, as seen in the following graph (blue line). However, the job encountered heavy memory usage by the executors during the join operations resulting from the shuffle (different colored lines showing high executor memory usage). This caused the job to eventually fail after four retries with an executor OOM.

Detecting OOM issues: Data skews and straggler tasks
In many cases, customer’s Spark jobs can run for hours before finally failing with errors. Instead of waiting for the jobs to fail after running for long hours and then analyze the root cause, we can check the job progress using Glue’s job metrics available through Amazon CloudWatch, or the Spark UI to identify straggler tasks that could potentially cause failures.
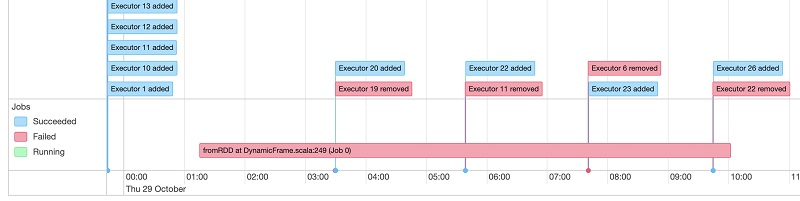
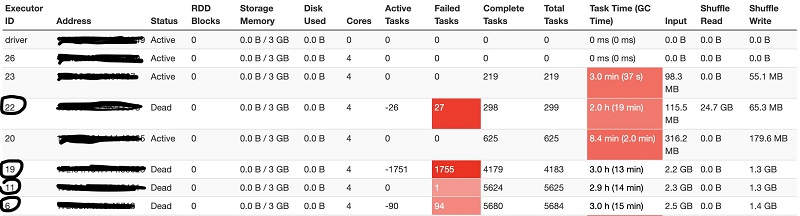
With Spark UI, we examined the Spark execution timeline and found that some of the executors are straggling with long-running tasks, resulting in eventual failures of those executors (Executor IDs 19, 11, 6, and 22 in the following event timeline graph)
Looking into the executor summary details, it was evident that these four executors contributed to many failed tasks during the job.

Diving deep into the executors revealed that the tasks are straggling during the shuffle phase, taking the longest runtime, and contributing to most of the job runtime. The following event timeline shows a consistent pattern of failures for all four executors performing straggler tasks that started with Executor 19.

In this scenario, the job ran for more than 10 hours before finally failing due to an executor OOM. Looking into the trend of the job from Spark UI or memory profiles from CloudWatch shows that executors in this job were involved in straggler tasks and this job was potentially on a path to failure. Instead of waiting for the job to run for hours and waste valuable resources, the job can be cancelled after looking at these trends after Executor 19 failed or automatically after a job-level timeout.
The first failed stage from the Spark UI shows Executor 19 was involved in many failed tasks and finally timed out and was replaced by another executor by the Spark driver.


Finally, investigating the details of the final stage of the job that failed showed that Executor 22, like the other three executors (19,11, and 6), was involved in straggler tasks during the shuffle phase and eventually failed with an OOM error.


Rerunning the job with a tighter bound
Now, we chang the boundedFiles parameter value to process 50,000 files:
The job ran successfully without any driver or executor memory issues.

Considering that each input file is about 1 MB size in our use case, we concluded that we can process about 50 GB of data from the fact dataset and join the same with two other datasets that have 10 additional files.
You can further convert AWS Glue DynamicFrames to Spark DataFrames and also use additional Spark transformations.
Running jobs in parallel on different partitions with tighter bounds
In production scenarios, data engineering pipelines generally have strict SLAs to complete data processing with ETL. For example, if we need to complete our job in 1.5 hours and process 50,000 files from the input dataset, the previous job would miss the SLA easily because the job takes more than 2 hours to complete. Another scenario could be if we have to process 100,000 input files, which might take more than 4 hours to finish if we run the same job sequentially, with each run processing 50,000 files with bounded execution.
To address these issues, we can optimize the pipeline by creating multiple copies of the job. We can use Glue’s push down predicates to process a subset of the data from different S3 partitions with bounded execution. In the following code, we create two copies of the same job that we ran earlier, but with the same boundedFiles parameter for both jobs to process 50,000 files. In one of the jobs, we pass a push down predicate with an even number as the partition value. In the other job, we process odd numbered partition values.
The following code shows the job with an even partition value:
The following code shows the job with an odd partition value:
On the AWS Glue console, we can create an AWS Glue Workflow to run both jobs in parallel. Because our input files have unique keys, even when running the jobs in parallel, the output doesn’t have any duplicates. If the input data can have duplicate keys, but the downstream application expects only unique records, we need to create a successor data deduplication job in the workflow to meet the business requirement. The following screenshot shows our workflow running both jobs in parallel.
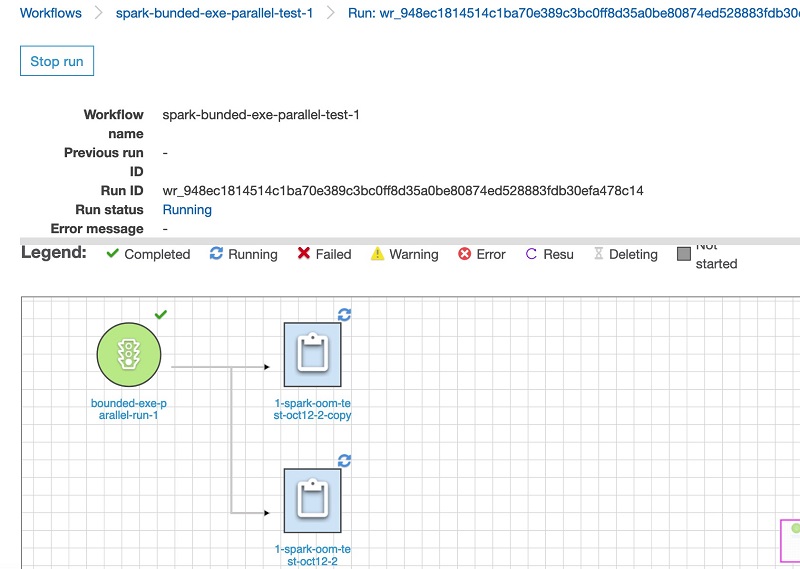
After running the workflow, we can go to the AWS Glue console and CloudWatch page to check the progress of the jobs triggered by the workflow.
We find that both jobs started and ended at the same time (within 2 hours), and were triggered by the same workflow trigger, bounded-exec-parallel-run-1. Both of them had safe Spark driver and executor memory usage throughout the job execution.
Conclusion
AWS Glue effectively manages Spark memory while running Spark applications. The workload partitioning feature provides the ability to bound execution of Spark applications and effectively improve the reliability of ETL pipelines susceptible to encounter errors arising due to large input sources, large-scale transformations, and data skews or abnormalities. Combining this feature with other optimization mechanisms, including push down predicates, can help avoid these issues and meet data pipeline SLAs for your ETL jobs.
About the Authors
 Avijit Goswami is a Principal Solutions Architect at AWS, helping startup customers become tomorrow’s enterprises using AWS services. He is part of the Analytics Specialist community at AWS. When not at work, Avijit likes to cook, travel, hike, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS, helping startup customers become tomorrow’s enterprises using AWS services. He is part of the Analytics Specialist community at AWS. When not at work, Avijit likes to cook, travel, hike, watch sports, and listen to music.

Xiaorun Yu is a Software Development Engineer at AWS Glue who works on Glue Spark runtime. When not at work, Xiaorun enjoys hiking around the Bay Area and trying local restaurants.
 Mohit Saxena is a Technical Lead Manager at AWS Glue. His team works on Glue’s Spark runtime to enable new customer use cases for efficiently managing data lakes on AWS and optimize Apache Spark for performance and reliability.
Mohit Saxena is a Technical Lead Manager at AWS Glue. His team works on Glue’s Spark runtime to enable new customer use cases for efficiently managing data lakes on AWS and optimize Apache Spark for performance and reliability.