AWS Big Data Blog
Optimize memory management in AWS Glue
April 2025: This post was reviewed for accuracy. Regarding performance tuning best practices for AWS Glue in general, we recommend to visit Best practices for performance tuning AWS Glue for Apache Spark jobs as well.
July 2022: This post was reviewed for accuracy.
AWS Glue provides a serverless environment to prepare and process datasets for analytics using the power of Apache Spark. In the third post of the series, we discussed how AWS Glue can automatically generate code to perform common data transformations. We also looked at how you can use AWS Glue Workflows to build data pipelines that enable you to easily ingest, transform and load data for analytics.
Apache Spark provides several knobs to control how memory is managed for different workloads. However, this is not an exact science and applications may still run into a variety of out of memory (OOM) exceptions because of inefficient transformation logic, unoptimized data partitioning or other quirks in the underlying Spark engine. In this post of the series, we will go deeper into the inner working of a Glue Spark ETL job, and discuss how we can combine AWS Glue capabilities with Spark best practices to scale our jobs to efficiently handle the variety and volume of our data.
Scaling the Apache Spark driver
Apache Spark driver is responsible for analyzing the job, coordinating, and distributing work to tasks to complete the job in the most efficient way possible. In majority of ETL jobs, the driver is typically involved in listing table partitions and the data files in Amazon S3 before it compute file splits and work for individual tasks. The driver then coordinates tasks running the transformations that will process each file split. In addition, the driver needs to keep track of the progress of each task is making and collect the results at the end. The Spark driver may become a bottleneck when a job needs to process large number of files and partitions. AWS Glue offers five different mechanisms to efficiently manage memory on the Spark driver when dealing with a large number of files.
- Push down predicates: Glue jobs allow the use of push down predicates to prune the unnecessary partitions from the table before the underlying data is read. This is useful when you have a large number of partitions in a table and you only want to process a subset of them in your Glue ETL job. Pruning catalog partitions reduces both the memory footprint of the driver and the time required to list the files in the pruned partitions. Push down predicates are applied first to ignore unnecessary partitions before the job bookmark and other exclusions can further filter the list of files to be read from each partition. Below is an example to how to use push down predicates to only process data for events logged only on weekends.
You can also use
catalogPartitionPredicateoption to limit the number of partitions referenced in Glue. Learn more in Server-side filtering using catalog partition predicates. - Glue S3 Lister: AWS Glue provides an optimized mechanism to list files on S3 while reading data into a DynamicFrame. The Glue S3 Lister can be enabled by setting the DynamicFrame’s
additional_optionsparameteruseS3ListImplementationtoTrue. The Glue S3 Lister offers advantage over the default S3 list implementation by strictly iterating over the final list of filtered files to be read. - Grouping: AWS Glue allows you to consolidate multiple files per Spark task using the file grouping feature. Grouping files together reduces the memory footprint on the Spark driver as well as simplifying file split orchestration. Without grouping, a Spark application must process each file using a different Spark task. Each task must then send mapStatus object containing the location information to the Spark driver. In our testing using AWS Glue standard worker type, we found that Spark applications processing more than roughly 650,000 files often cause the Spark driver to crash with an out of memory exception as shown by the following error message:
groupFilesallows you to group files within a Hive-style S3 partition (inPartition) and across S3 partitions (acrossPartition).groupSizeis an optional field that allows you to configure the amount of data to be read from each file and processed by individual Spark tasks.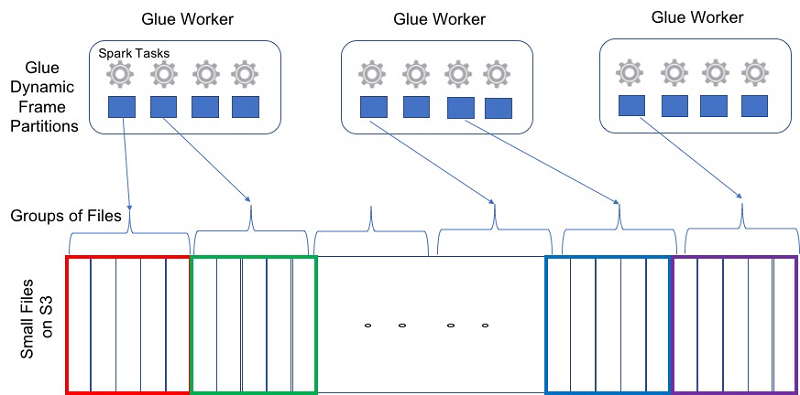
- Exclusions for S3 Paths: To further aid in filtering out files that are not required by the job, AWS Glue introduced a mechanism for users to provide a glob expression for S3 paths to be excluded. This speeds job processing while reducing the memory footprint on the Spark driver. The following code snippet shows how to exclude all objects ending with _metadata in the selected S3 path.
Exclusions for S3 Storage Classes: AWS Glue offers the ability to exclude objects based on their underlying S3 storage class. As the lifecycle of data evolve, hot data becomes cold and automatically moves to lower cost storage based on the configured S3 bucket policy, it’s important to make sure ETL jobs process the correct data. This is particularly useful when working with large datasets that span across multiple S3 storage classes using Apache Parquet file format where Spark will try to read the schema from the file footers in these storage classes. Amazon S3 offers 5 different storage classes which are STANDARD, INTELLIGENT_TIERING, STANDARD_IA, ONEZONE_IA, GLACIER, DEEP_ARCHIVE and REDUCED_REDUNDANCY. When reading data using DynamicFrames, you can specify a list of S3 storage classes you want to exclude. This feature leverages the optimized AWS Glue S3 Lister. The following example shows how to exclude files stored in GLACIER and DEEP_ARCHIVE storage classes.
GLACIER and DEEP_ARCHIVE storage classes only allow listing files and require an asynchronous S3 restore process to read the actual data. The following is the exception you will see when trying to access Glacier and Deep Archive storage classes from your Glue ETL job:
- Optimize Spark queries: Inefficient queries or transformations can have a significant impact on Apache Spark driver memory utilization.Common examples include:
collectis a Spark action that collects the results from workers and return them back to the driver. In some cases the results may be very large overwhelming the driver. It is recommended to be careful while usingcollectas it can frequently cause Spark driver OOM exceptions as shown below:- Shared Variables: Apache Spark offers two different ways to share variables between Spark driver and executors: broadcast variables and accumulators. Broadcast variables are useful to provide a read-only copy of data or fact tables shared across Spark workers to improve map-side joins. Accumulators are useful to provide a writeable copy to implement distributed counters across Spark executors. Both should be used carefully and destroyed when no longer needed as they can frequently result in Spark driver OOM exceptions.
Scaling Apache Spark executors
Apache Spark executors process data in parallel. However, un-optimized reads from JDBC sources, unbalanced shuffles, buffering of rows with PySpark UDFs, exceeding off-heap memory on each Spark worker, skew in size of partitions, can all result in Spark executor OOM exceptions. We list below some of the best practices with AWS Glue and Apache Spark for avoiding these conditions that result in OOM exceptions.
- JDBC Optimizations: Apache Spark uses JDBC drivers to fetch data from JDBC sources such as MySQL, PostgresSQL, Oracle.
- Fetchsize: By default, the Spark JDBC drivers configure the fetch size to zero. This means that the JDBC driver on the Spark executor tries to fetch all the rows from the database in one network round trip and cache them in memory, even though Spark transformation only streams through the rows one at a time. This may result in the Spark executor running out of memory exception.
In Spark, you can avoid this scenario by explicitly setting the fetch size parameter to a non-zero default value. With AWS Glue, Dynamic Frames automatically use a fetch size of 1,000 rows that bounds the size of cached rows in JDBC driver and also amortizes the overhead of network round-trip latencies between the Spark executor and database instance. The example below shows how to read from a JDBC source using Glue dynamic frames.
- Fetchsize: By default, the Spark JDBC drivers configure the fetch size to zero. This means that the JDBC driver on the Spark executor tries to fetch all the rows from the database in one network round trip and cache them in memory, even though Spark transformation only streams through the rows one at a time. This may result in the Spark executor running out of memory exception.
- Spark’s Read Partitioning: Apache Spark by default uses only one executor to open up a JDBC connection with the database and read the entire table into a Spark dataframe. This can result in an unbalanced distribution of data processed across different executors. As a result, it is usually recommended to use a
partitionColumn,lowerBound,upperBound, andnumPartitionsto enable reading in parallel from different executors. This allows for more balanced partitioning if there exists a column that has a uniform value distribution. However, Apache Spark restricts thepartitionColumnto be one of numeric, date, or timestamp data types. For example: - Glue’s Read Partitioning: AWS Glue enables partitioning JDBC tables based on columns with generic types, such as string. This enables you to read from JDBC sources using non-overlapping parallel SQL queries executed against logical partitions of your table from different Spark executors. You can control partitioning by setting a
hashfieldorhashexpression. You can also control the number of parallel reads that are used to access your data by specifyinghashpartitions. For best results, this column should have an even distribution of values to spread the data between partitions. For example, if your data is evenly distributed by month, you can use themonthcolumn to read each month of data in parallel. Based on the database instance type, you may like to tune the number of parallel connections by adjusting thehashpartitions. For example: - Bulk Inserts: AWS Glue offers parallel inserts for speeding up bulk loads into JDBC targets. The following example uses a bulk size of two, which allows two inserts to happen in parallel. This is helpful for improving the performance of writes into databases such as Aur.
- Join Optimizations: One common reason for Apache Spark applications running out of memory is the use of un-optimized joins across two or more tables. This is typically a result of data skew due to the distribution of join columns or an inefficient choice of join transforms. Additionally, ordering of transforms and filters in the user script may limit the Spark query planner’s ability to optimize. There are 3 popular approaches to optimize join’s on AWS Glue.
- Enable and tune Adaptive Query Execution: You should consider enabling and tuning Adaptive Query Execution to optimize join operations. Adaptive Query Execution converts a sort-merge join to a broadcast hash join when the runtime statistics of either join side is smaller than the adaptive broadcast hash join threshold. In AWS Glue 3.0, you can enable Adaptive Query Execution by setting
spark.sql.adaptive.enabled=true. Adaptive Query Execution is enabled by default in AWS Glue 4.0 and later. Visit Optimize shuffles for more details. - Filter tables before Join: You should pre-filter your tables as much as possible before joining. This helps to minimize the data shuffled between the executors over the network. You can use AWS Glue push down predicates for filtering based on partition columns, AWS Glue exclusions for filtering based on file names, AWS Glue storage class exclusions for filtering based on S3 storage classes, and use columnar storage formats such as Parquet and ORC that support discarding row groups based on column statistics such as min/max of column values.
- Broadcast Small Tables: Joining tables can result in large amounts of data being shuffled or moved over the network between executors running on different workers. Because of this, Spark may run out of memory and spill the data to physical disk on the worker. This behavior can be observed in the following log message:
In cases where one of the tables in the join is small, few tens of MBs, we can indicate Spark to handle it differently reducing the overhead of shuffling data. This is performed by hinting Apache Spark that the smaller table should be broadcasted instead of partitioned and shuffled across the network. The Spark parameter
spark.sql.autoBroadcastJoinThresholdconfigures the maximum size, in bytes, for a table that will be broadcast to all worker nodes when performing a join. Apache Spark will automatically broadcast a table when it is smaller than 10 MB. You can also explicitly tell Spark which table you want to broadcast as shown in the following example:
- Enable and tune Adaptive Query Execution: You should consider enabling and tuning Adaptive Query Execution to optimize join operations. Adaptive Query Execution converts a sort-merge join to a broadcast hash join when the runtime statistics of either join side is smaller than the adaptive broadcast hash join threshold. In AWS Glue 3.0, you can enable Adaptive Query Execution by setting
- PySpark User Defined Functions (UDFs): Using PySpark UDFs can turn out to be costly for executor memory. This is because data must be serialized/deserialized when it is exchanged between the Spark executor JVM and the Python interpreter. The Python interpreter needs to process the serialized data in Spark executor’s off-heap memory. For datasets with large or nested records or when using complex UDFs, this processing can consume large amounts of off-heap memory and can lead to OOM exceptions. Similarly, data serialization can be slow and often leads to longer job execution times. To avoid such OOM exceptions, there are two common known practices. One of the traditional practice to write the UDFs in Scala or Java instead of Python. They can be imported by providing the S3 Path of Dependent Jars in the Glue job configuration. Another optimization to avoid buffering of large records in off-heap memory with PySpark UDFs is to move select and filters upstream to earlier execution stages for an AWS Glue script. The other recommended practice is to use Pandas UDF (as known as vectorized UDF).
- Incremental processing: Processing large datasets in S3 can result in costly network shuffles, spilling data from memory to disk, and OOM exceptions. To avoid these scenarios, it is a best practice to incrementally process large datasets using AWS Glue Job Bookmarks, Push-down Predicates, and Exclusions. Concurrent job runs can process separate S3 partitions and also minimize the possibility of OOMs caused due to large Spark partitions or unbalanced shuffles resulting from data skew. Vertical scaling with higher memory instances can also mitigate the chances of OOM exceptions because of insufficient off-heap memory or Apache Spark applications that can not be readily optimized.
Scaling the Apache Spark driver and Apache Spark executors
- Auto scaling: Glue suports auto scaling. With Glue auto scaling, you can just set the maximum number of workers and run your jobs. AWS Glue monitors the Spark application execution, and allocates more worker nodes to the cluster in near-real time after Spark requests more executors based on your workload requirements. Learn more in Introducing AWS Glue Auto Scaling: Automatically resize serverless computing resources for lower cost with optimized Apache Spark.
- Vertical scaling: Glue provides different worker types; G.1X, G.2X, G.4X, G.8X, and G.025X (only for streaming). You can also use larger worker types that provide more memory and disk space to vertically scale your Glue jobs that need high memory or disk space to store intermediate shuffle output. Vertical scaling for Glue jobs is discussed in our first blog post of this series.
- Workload partitioning by bounded execution: AWS Glue allows you to solve OOM issues and make your ETL processing easier with workload partitioning. With workload partitioning enabled, each ETL job run only picks unprocessed data, with an upper bound on the dataset size or the number of files to be processed with this job run. Future job runs will process the remaining data. See details in this document.
Conclusion
In this post, we discussed a number of techniques to enable efficient memory management for Apache Spark applications when reading data from Amazon S3 and compatible databases using a JDBC connector. We described how Glue ETL jobs can utilize the partitioning information available from AWS Glue Data Catalog to prune large datasets, manage large number of small files, and use JDBC optimizations for partitioned reads and batch record fetch from databases. You can use some or all of these techniques to help ensure your ETL jobs perform well.
In the next post, we will describe how you can develop Apache Spark applications and ETL scripts locally from your laptop itself with the Glue Spark Runtime containing these optimizations. You can build against the Glue Spark Runtime available from Maven or using a Docker container for cross-platform support. You can develop using Jupyter/Zeppelin notebooks, or your favorite IDE such as PyCharm. Next, you can deploy those Spark applications on AWS Glue’s serverless Spark platform.
About the Author
 Mohit Saxena is a technical lead manager at AWS Glue. His passion is building scalable distributed systems for efficiently managing data on cloud. He also enjoys watching movies, and reading about the latest technology.
Mohit Saxena is a technical lead manager at AWS Glue. His passion is building scalable distributed systems for efficiently managing data on cloud. He also enjoys watching movies, and reading about the latest technology.