AWS Big Data Blog
Category: AWS Big Data

Creating a source to Lakehouse data replication pipe using Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
February 2021 update – Please refer to the post Writing to Apache Hudi tables using AWS Glue Custom Connector to learn about an easier mechanism to write to Hudi tables using AWS Glue Custom Connector. In this post, we include the modified Apache Hudi JARs as an external dependency. The AWS Glue Custom Connector feature […]
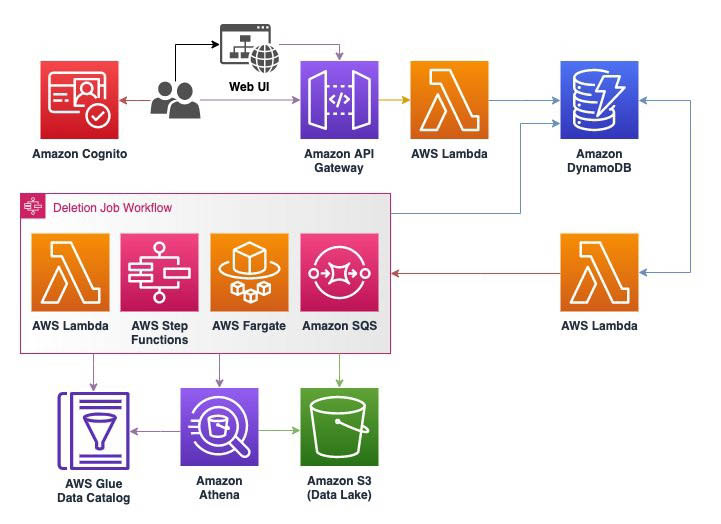
Handling data erasure requests in your data lake with Amazon S3 Find and Forget
February 2024: This post was reviewed and updated for accuracy. Data lakes are a popular choice for organizations to store data around their business activities. Best practice design of data lakes impose that data is immutable once stored, but new regulations such as the European General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), […]
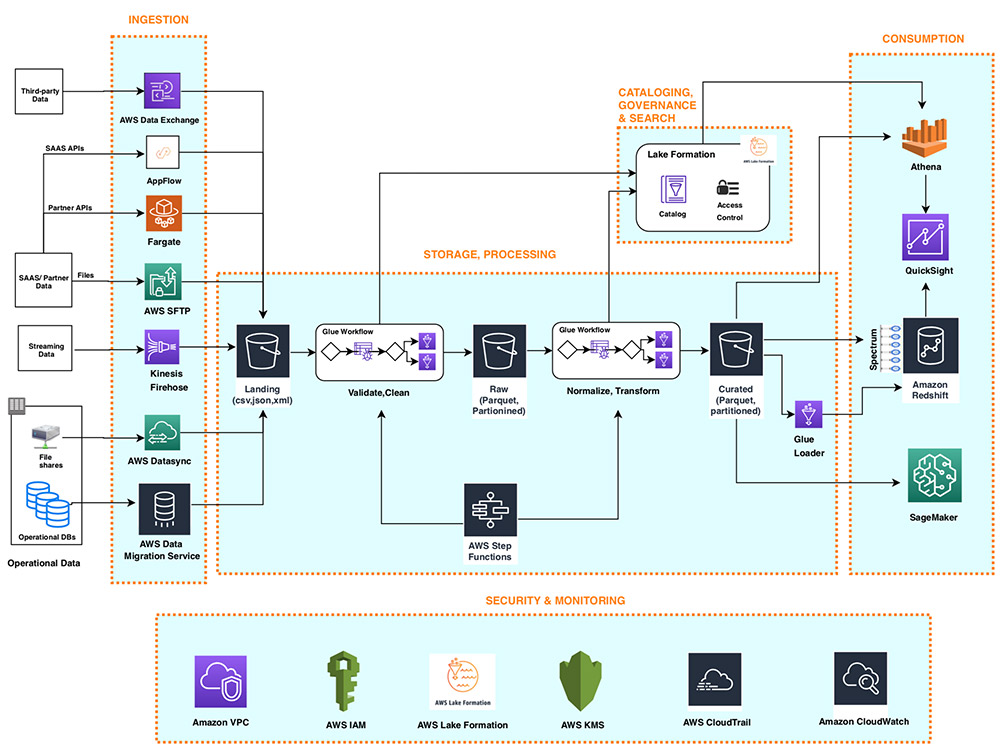
AWS serverless data analytics pipeline reference architecture
May 2025: This post was reviewed and updated for accuracy. Onboarding new data or building new analytics pipelines in traditional analytics architectures typically requires extensive coordination across business, data engineering, and data science and analytics teams to first negotiate requirements, schema, infrastructure capacity needs, and workload management. For a large number of use cases today […]
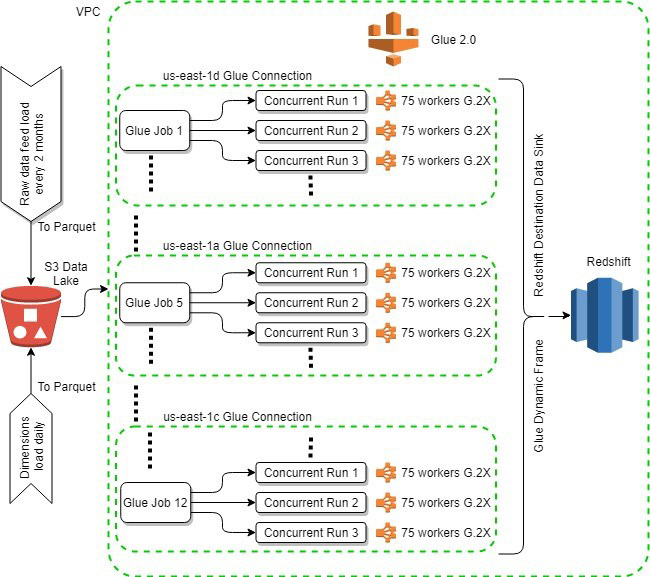
Big data processing in a data warehouse environment using AWS Glue 2.0 and PySpark
The AWS Marketing Data Science and Engineering team enables AWS Marketing to measure the effectiveness and impact of various marketing initiatives and campaigns. This is done through a data platform and infrastructure strategy that consists of maintaining data warehouse, data lake, and data transformation (ETL) pipelines, and designing software tools and services to run related […]

Crafting serverless streaming ETL jobs with AWS Glue
Organizations across verticals have been building streaming-based extract, transform, and load (ETL) applications to more efficiently extract meaningful insights from their datasets. Although streaming ingest and stream processing frameworks have evolved over the past few years, there is now a surge in demand for building streaming pipelines that are completely serverless. Since 2017, AWS Glue […]

Event-driven refresh of SPICE datasets in Amazon QuickSight
Businesses are increasingly harnessing data to improve their business outcomes. To enable this transformation to a data-driven business, customers are bringing together data from structured and unstructured sources into a data lake. Then they use business intelligence (BI) tools, such as Amazon QuickSight, to unlock insights from this data. To provide fast access to datasets, […]

Normalize data with Amazon Elasticsearch Service ingest pipelines
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Amazon OpenSearch Service is a fully managed service that makes it easy for you to deploy, secure, and run Elasticsearch cost-effectively at scale. Search and log analytics are the two most popular use cases for Amazon OpenSearch Service. In log analytics […]

Making ETL easier with AWS Glue Studio
AWS Glue Studio is an easy-to-use graphical interface that speeds up the process of authoring, running, and monitoring extract, transform, and load (ETL) jobs in AWS Glue. The visual interface allows those who don’t know Apache Spark to design jobs without coding experience and accelerates the process for those who do. AWS Glue Studio was […]

Best practices using AWS SCT and AWS Snowball to migrate from Teradata to Amazon Redshift
This is a guest post from ZS. In their own words, “ZS is a professional services firm that works closely with companies to help develop and deliver products and solutions that drive customer value and company results. ZS engagements involve a blend of technology, consulting, analytics, and operations, and are targeted toward improving the commercial […]

Building an AWS Glue ETL pipeline locally without an AWS account
This blog was last reviewed May, 2022. If you’re new to AWS Glue and looking to understand its transformation capabilities without incurring an added expense, or if you’re simply wondering if AWS Glue ETL is the right tool for your use case and want a holistic view of AWS Glue ETL functions, then please continue […]