AWS Big Data Blog
Category: AWS Big Data
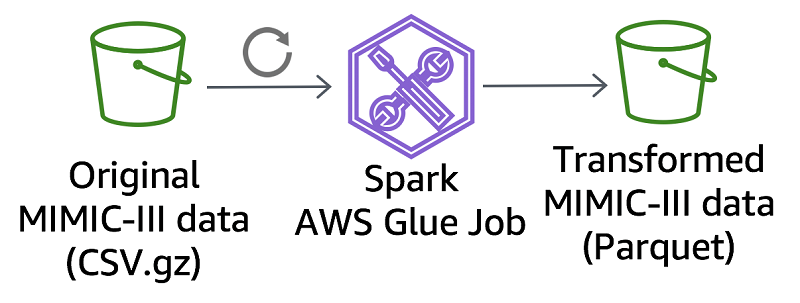
Perform biomedical informatics without a database using MIMIC-III data and Amazon Athena
This post describes how to make the MIMIC-III dataset available in Athena and provide automated access to an analysis environment for MIMIC-III on AWS. We also compare a MIMIC-III reference bioinformatics study using a traditional database to that same study using Athena.

Discover metadata with AWS Lake Formation: Part 2
In this post, you will learn how to use the metadata search capabilities of Lake Formation. By defining specific user permissions, Lake Formation allows you to grant and revoke access to metadata in the Data Catalog as well as the underlying data stored in S3.

Discovering metadata with AWS Lake Formation: Part 1
In this post, you will create and edit your first data lake using the Lake Formation. You will use the service to secure and ingest data into an S3 data lake, catalog the data, and customize the metadata of the data sources. In part 2 of this series, we will show you how to discover your data by using the metadata search capabilities of Lake Formation.

Getting started with AWS Lake Formation
June 2024: This post was reviewed and updated for accuracy. AWS Lake Formation enables you to set up a secure data lake. A data lake is a centralized, curated, and secured repository storing all your structured and unstructured data, at any scale. You can store your data as-is, without having first to structure it. And […]

Integrate and deduplicate datasets using AWS Lake Formation FindMatches
AWS Lake Formation FindMatches is a new machine learning (ML) transform that enables you to match records across different datasets as well as identify and remove duplicate records, with little to no human intervention. FindMatches is part of Lake Formation, a new AWS service that helps you build a secure data lake in a few simple steps.
To use FindMatches, you don’t have to write code or know how ML works. Your data doesn’t have to include a unique identifier, nor must fields match exactly.
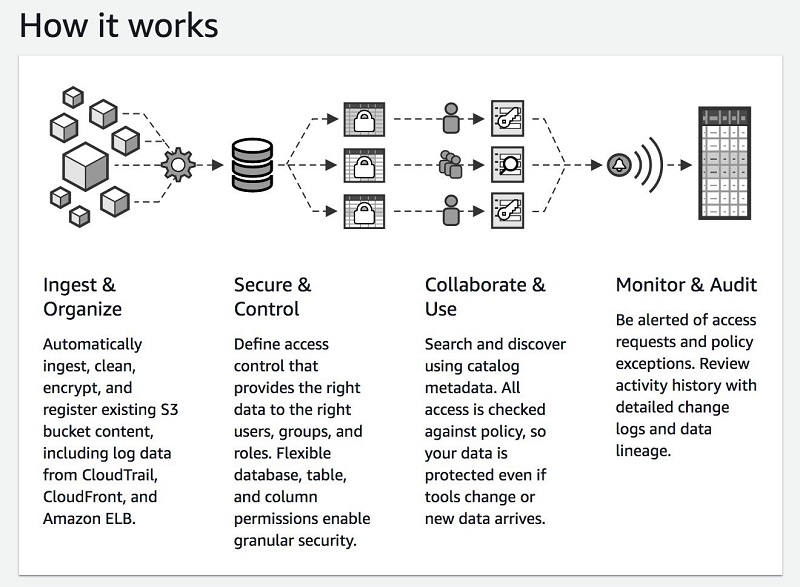
Build, secure, and manage data lakes with AWS Lake Formation
A data lake is a centralized store of a variety of data types for analysis by multiple analytics approaches and groups. Many organizations are moving their data into a data lake. In this post, we explore how you can use AWS Lake Formation to build, secure, and manage data lakes.
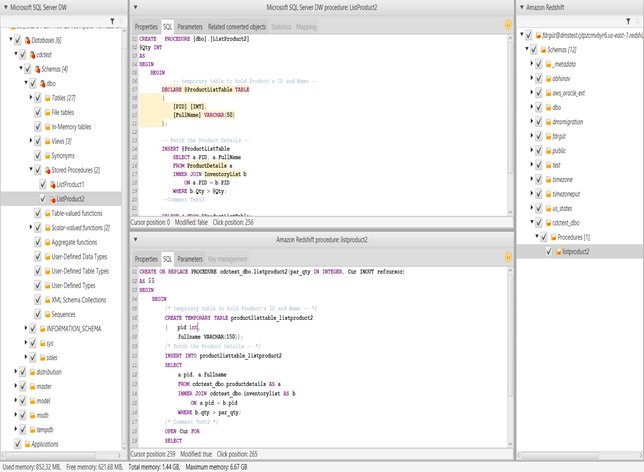
Bringing your stored procedures to Amazon Redshift
Amazon always works backwards from the customer’s needs. Customers have made strong requests that they want stored procedures in Amazon Redshift, to make it easier to migrate their existing workloads from legacy, on-premises data warehouses.
With that primary goal in mind, AWS chose to implement PL/pqSQL stored procedure to maximize compatibility with existing procedures and simplify migrations. In this post, we discuss how and where to use stored procedures to improve operational efficiency and security. We also explain how to use stored procedures with AWS Schema Conversion Tool.
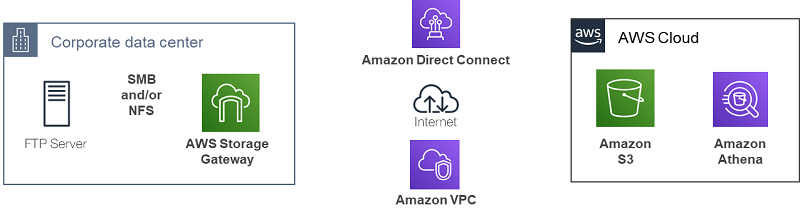
Query your data created on-premises using Amazon Athena and AWS Storage Gateway
In this blog post, I use this architecture to demonstrate the combined capabilities of Storage Gateway and Athena. AWS Storage Gateway is a hybrid storage service that enables your on-premises applications to seamlessly use AWS cloud storage. The File Gateway configuration of the AWS Storage Gateway offers you a seamless way to connect to the cloud in order to store application data files and backup images as durable objects on Amazon S3 cloud storage.
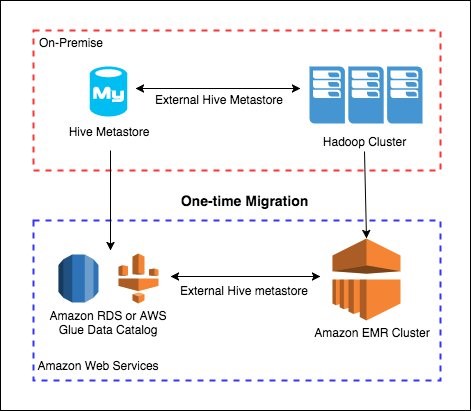
Migrate and deploy your Apache Hive metastore on Amazon EMR
Combining the speed and flexibility of Amazon EMR with the utility and ubiquity of Apache Hive provides you with the best of both worlds. However, getting started with big data projects can feel intimidating. Whether you want to deploy new data on EMR or migrate an existing project, this post provides you with the basics to get started.
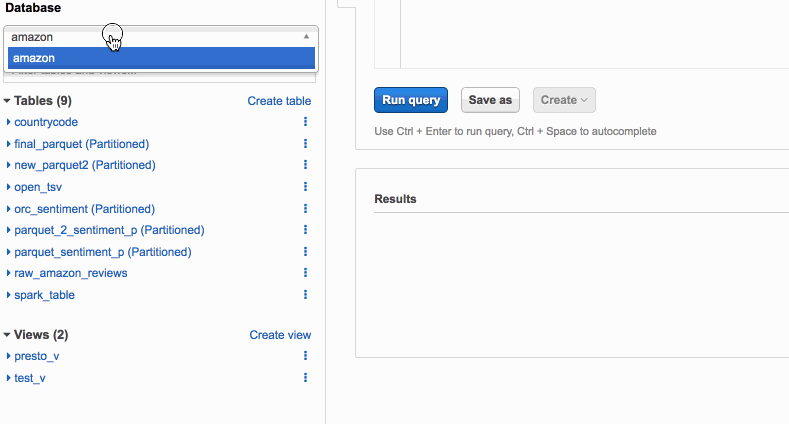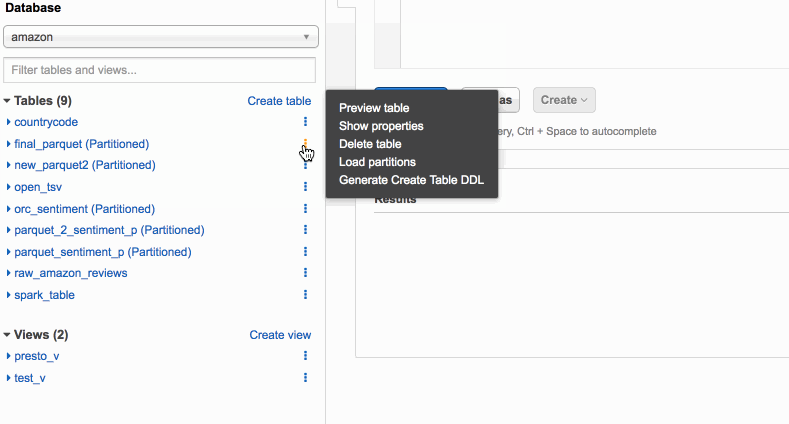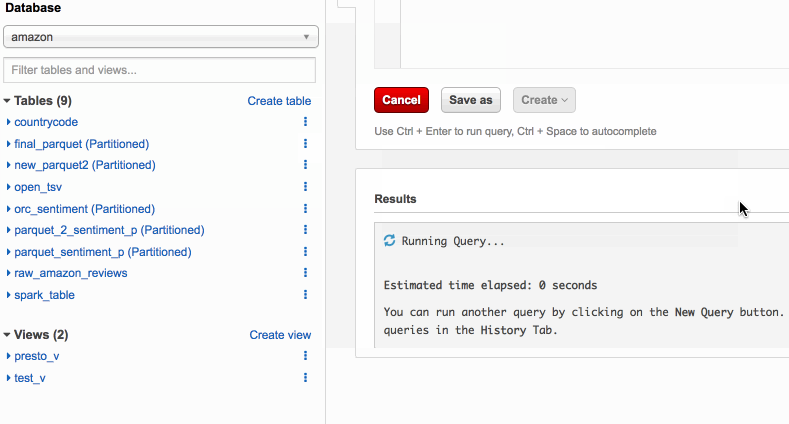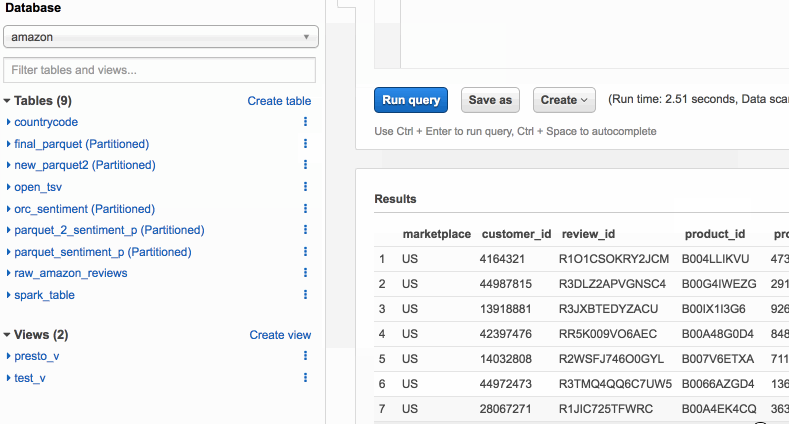
Separate queries and managing costs using Amazon Athena workgroups
Amazon Athena is a serverless query engine for data on Amazon S3. Many customers use Athena to query application and service logs, schedule automated reports, and integrate with their applications, enabling new analytics-based capabilities. Different types of users rely on Athena, including business analysts, data scientists, security, and operations engineers. In this post, I show you how to use workgroups to separate workloads, control user access, and manage query usage and costs.