AWS Big Data Blog
Category: Advanced (300)

Perform time series forecasting using Amazon Redshift ML and Amazon Forecast
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Many businesses use different software tools to analyze historical data and past patterns to forecast future demand and trends to make more […]

Configure cross-Region table access with the AWS Glue Catalog and AWS Lake Formation
Today’s modern data lakes span multiple accounts, AWS Regions, and lines of business in organizations. Companies also have employees and do business across multiple geographic regions and even around the world. It’s important that their data solution gives them the ability to share and access data securely and safely across Regions. The AWS Glue Data […]

Create an Apache Hudi-based near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight
We recently announced support for streaming extract, transform, and load (ETL) jobs in AWS Glue version 4.0, a new version of AWS Glue that accelerates data integration workloads in AWS. AWS Glue streaming ETL jobs continuously consume data from streaming sources, clean and transform the data in-flight, and make it available for analysis in seconds. AWS also offers a broad selection of services to support your needs. A database replication service such as AWS Database Migration Service (AWS DMS) can replicate the data from your source systems to Amazon Simple Storage Service (Amazon S3), which commonly hosts the storage layer of the data lake. This post demonstrates how to apply CDC changes from Amazon Relational Database Service (Amazon RDS) or other relational databases to an S3 data lake, with flexibility to denormalize, transform, and enrich the data in near-real time.
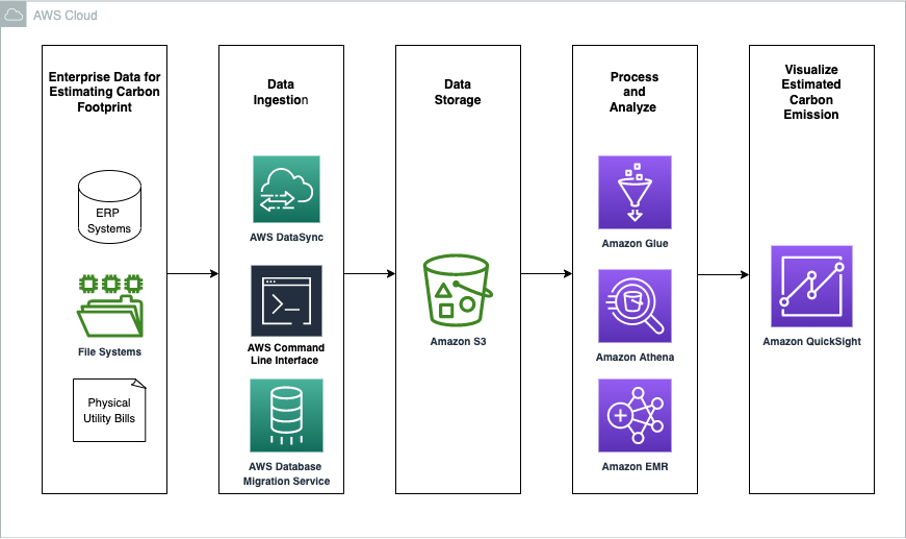
Estimating Scope 1 Carbon Footprint with Amazon Athena
Today, more than 400 organizations have signed The Climate Pledge, a commitment to reach net-zero carbon by 2040. Some of the drivers that lead to setting explicit climate goals include customer demand, current and anticipated government relations, employee demand, investor demand, and sustainability as a competitive advantage. AWS customers are increasingly interested in ways to […]

Amazon Kinesis Data Streams on-demand capacity mode now scales up to 10 GB/second ingest capacity
April 2025: This post was reviewed and updated for accuracy. Amazon Kinesis Data Streams is a serverless data streaming service that makes it easy to capture, process, and store streaming data at any scale. As customers collect and stream more types of data, they have asked for simpler, elastic data streams that can handle variable and […]

Migrate your existing SQL-based ETL workload to an AWS serverless ETL infrastructure using AWS Glue
Data has become an integral part of most companies, and the complexity of data processing is increasing rapidly with the exponential growth in the amount and variety of data. Data engineering teams are faced with the following challenges: Manipulating data to make it consumable by business users Building and improving extract, transform, and load (ETL) […]

Extend your data mesh with Amazon Athena and federated views
Amazon Athena is a serverless, interactive analytics service built on the Trino, PrestoDB, and Apache Spark open-source frameworks. You can use Athena to run SQL queries on petabytes of data stored on Amazon Simple Storage Service (Amazon S3) in widely used formats such as Parquet and open-table formats like Apache Iceberg, Apache Hudi, and Delta […]

Find the best Amazon Redshift configuration for your workload using Redshift Test Drive
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. With the launch of Amazon Redshift Serverless and the various deployment options Amazon Redshift provides (such as instance types and cluster sizes), customers […]

Implement tag-based access control for your data lake and Amazon Redshift data sharing with AWS Lake Formation
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. Many organizations have a distributed tools and infrastructure across various business units. This leads to having data across many instances of data warehouses and data lakes using a modern data architecture […]

Build and share a business capability model with Amazon QuickSight
The technology landscape has been evolving rapidly, with waves of change impacting IT from every angle. It is causing a ripple effect across IT organizations and shifting the way IT delivers applications and services. The change factors impacting IT organizations include: The shift from a traditional application model to a services-based application model (SaaS, PaaS) […]