AWS Big Data Blog
Extend your data mesh with Amazon Athena and federated views
Amazon Athena is a serverless, interactive analytics service built on the Trino, PrestoDB, and Apache Spark open-source frameworks. You can use Athena to run SQL queries on petabytes of data stored on Amazon Simple Storage Service (Amazon S3) in widely used formats such as Parquet and open-table formats like Apache Iceberg, Apache Hudi, and Delta Lake. However, Athena also allows you to query data stored in 30 different data sources—in addition to Amazon S3—including relational, non-relational, and object stores running on premises or in other cloud environments.
In Athena, we refer to queries on non-Amazon S3 data sources as federated queries. These queries run on the underlying database, which means you can analyze the data without learning a new query language and without the need for separate extract, transform, and load (ETL) scripts to extract, duplicate, and prepare data for analysis.
Recently, Athena added support for creating and querying views on federated data sources to bring greater flexibility and ease of use to use cases such as interactive analysis and business intelligence reporting. Athena also updated its data connectors with optimizations that improve performance and reduce cost when querying federated data sources. The updated connectors use dynamic filtering and an expanded set of predicate pushdown optimizations to perform more operations in the underlying data source rather than in Athena. As a result, you get faster queries with less data scanned, especially on tables with millions to billions of rows of data.
In this post, we show how to create and query views on federated data sources in a data mesh architecture featuring data producers and consumers.
The term data mesh refers to a data architecture with decentralized data ownership. A data mesh enables domain-oriented teams with the data they need, emphasizes self-service, and promotes the notion of purpose-built data products. In a data mesh, data producers expose datasets to the organization and data consumers subscribe to and consume the data products created by producers. By distributing data ownership to cross-functional teams, a data mesh can foster a culture of collaboration, invention, and agility around data.
Let’s dive into the solution.
Solution overview
For this post, imagine a hypothetical ecommerce company that uses multiple data sources, each playing a different role:
- In an S3 data lake, ecommerce records are stored in a table named
Lineitems - Amazon ElastiCache for Redis stores
NationsandActiveOrdersdata, ensuring ultra-fast reads of operational data by downstream ecommerce systems - On Amazon Relational Database Service (Amazon RDS), MySQL is used to store data like email addresses and shipping addresses in the Orders, Customer, and Suppliers tables
- For flexibility and low-latency reads and writes, an Amazon DynamoDB table holds
PartandPartsuppdata
We want to query these data sources in a data mesh design. In the following sections, we set up Athena data source connectors for MySQL, DynamoDB, and Redis, and then run queries that perform complex joins across these data sources. The following diagram depicts our data architecture.

As you proceed with this solution, note that you will create AWS resources in your account. We have provided you with an AWS CloudFormation template that defines and configures the required resources, including the sample MySQL database, S3 tables, Redis store, and DynamoDB table. The template also creates the AWS Glue database and tables, S3 bucket, Amazon S3 VPC endpoint, AWS Glue VPC endpoint, and other AWS Identity and Access Management (IAM) resources that are used in the solution.
The template is designed to demonstrate how to use federated views in Athena, and is not intended for production use without modification. Additionally, the template uses the us-east-1 Region and will not work in other Regions without modification. The template creates resources that incur costs while they are in use. Follow the cleanup steps at the end of this post to delete the resources and avoid unnecessary charges.
Prerequisites
Before you launch the CloudFormation stack, ensure you have the following prerequisites:
- An AWS account that provides access to AWS services
- An IAM user with an access key and secret key to configure the AWS Command Line Interface (AWS CLI), and permissions to create an IAM role, IAM policies, and stacks in AWS CloudFormation
Create resources with AWS CloudFormation
To get started, complete the following steps:
- Choose Launch Stack:

- Select I acknowledge that this template may create IAM resources.
The CloudFormation stack takes approximately 20–30 minutes to complete. You can monitor its progress on the AWS CloudFormation console. When status reads CREATE_COMPLETE, your AWS account will have the resources necessary to implement this solution.
Deploy connectors and connect to data sources
With our resources provisioned, we can begin to connect the dots in our data mesh. Let’s start by connecting the data sources created by the CloudFormation stack with Athena.
- On the Athena console, choose Data sources in the navigation pane.
- Choose Create data source.
- For Data sources, select MySQL, then choose Next.
- For Data source name, enter a name, such as
mysql. The Athena connector for MySQL is an AWS Lambda function that was created for you by the CloudFormation template. - For Connection details, choose Select or enter a Lambda function.
- Choose
mysql, then choose Next. - Review the information and choose Create data source.
- Return to the Data sources page and choose
mysql. - On the connector details page, choose the link under Lambda function to access the Lambda console and inspect the function associated with this connector.

- Return to the Athena query editor.
- For Data source, choose
mysql. - For Database, choose the
salesdatabase. - For Tables, you should see a listing of MySQL tables that are ready for you to query.
- Repeat these steps to set up the connectors for DynamoDB and Redis.
After all four data sources are configured, we can see the data sources on the Data source drop-down menu. All other databases and tables, like the lineitem table, which is stored on Amazon S3, are defined in the AWS Glue Data Catalog and can be accessed by choosing AwsDataCatalog as the data source.
Analyze data with Athena
With our data sources configured, we are ready to start running queries and using federated views in a data mesh architecture. Let’s start by trying to find out how much profit was made on a given line of parts, broken out by supplier nation and year.
For such a query, we need to calculate, for each nation and year, the profit for parts ordered in each year that were filled by a supplier in each nation. Profit is defined as the sum of [(l_extendedprice*(1-l_discount)) - (ps_supplycost * l_quantity)] for all line items describing parts in the specified line.
Answering this question requires querying all four data sources—MySQL, DynamoDB, Redis, and Amazon S3—and is accomplished with the following SQL:
Running this query on the Athena console produces the following result.
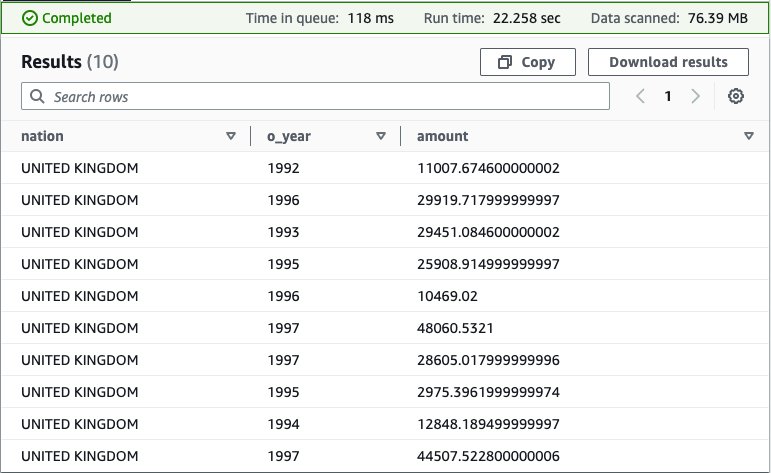
This query is fairly complex: it involves multiple joins and requires special knowledge of the correct way to calculate profit metrics that other end-users may not possess.
To simplify the analysis experience for those users, we can hide this complexity behind a view. For more information on using views with federated data sources, see Querying federated views.
Use the following query to create the view in the data_lake database under the AwsDataCatalog data source:
Next, run a simple select query to validate the view was created successfully: SELECT * FROM federated_view limit 10
The result should be similar to our previous query.
With our view in place, we can perform new analyses to answer questions that would be challenging without the view due to the complex query syntax that would be required. For example, we can find the total profit by nation:
Your results should resemble the following screenshot.
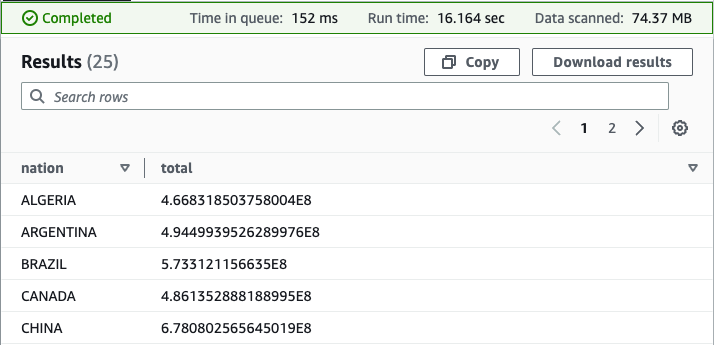
As you now see, the federated view makes it simpler for end-users to run queries on this data. Users are free to query a view of the data, defined by a knowledgeable data producer, rather than having to first acquire expertise in each underlying data source. Because Athena federated queries are processed where the data is stored, with this approach, we avoid duplicating data from the source system, saving valuable time and cost.
Use federated views in a multi-user model
So far, we have satisfied one of the principles of a data mesh: we created a data product (federated view) that is decoupled from its originating source and is available for on-demand analysis by consumers.
Next, we take our data mesh a step further by using federated views in a multi-user model. To keep it simple, assume we have one producer account, the account we used to create our four data sources and federated view, and one consumer account. Using the producer account, we give the consumer account permission to query the federated view from the consumer account.
The following figure depicts this setup and our simplified data mesh architecture.
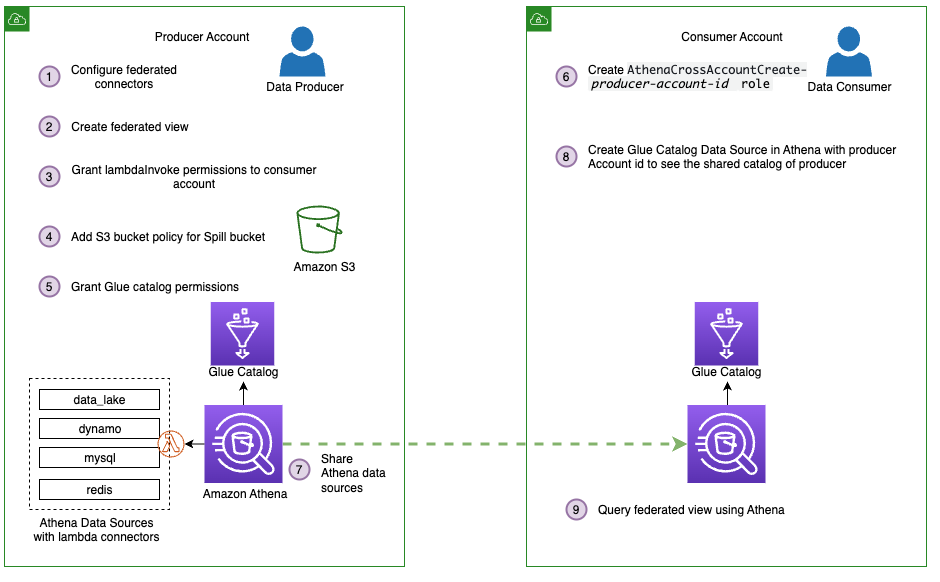
Follow these steps to share the connectors and AWS Glue Data Catalog resources from the producer, which includes our federated view, with the consumer account:
- Share the data sources
mysql,redis,dynamo, anddata_lakewith the consumer account. For instructions, refer to Sharing a data source in Account A with Account B. Note that Account A represents the producer and Account B represents the consumer. Make sure you use the same data source names from earlier when sharing data. This is necessary for the federated view to work in a cross-account model. - Next, share the producer account’s AWS Glue Data Catalog with the consumer account by following the steps in Cross-account access to AWS Glue data catalogs. For the data source name, use
shared_federated_catalog. - Switch to the consumer account, navigate to the Athena console, and verify that you see
federated_viewlisted under Views in theshared_federated_catalogData Catalog anddata_lakedatabase. - Next, run a sample query on the shared view to see the query results.
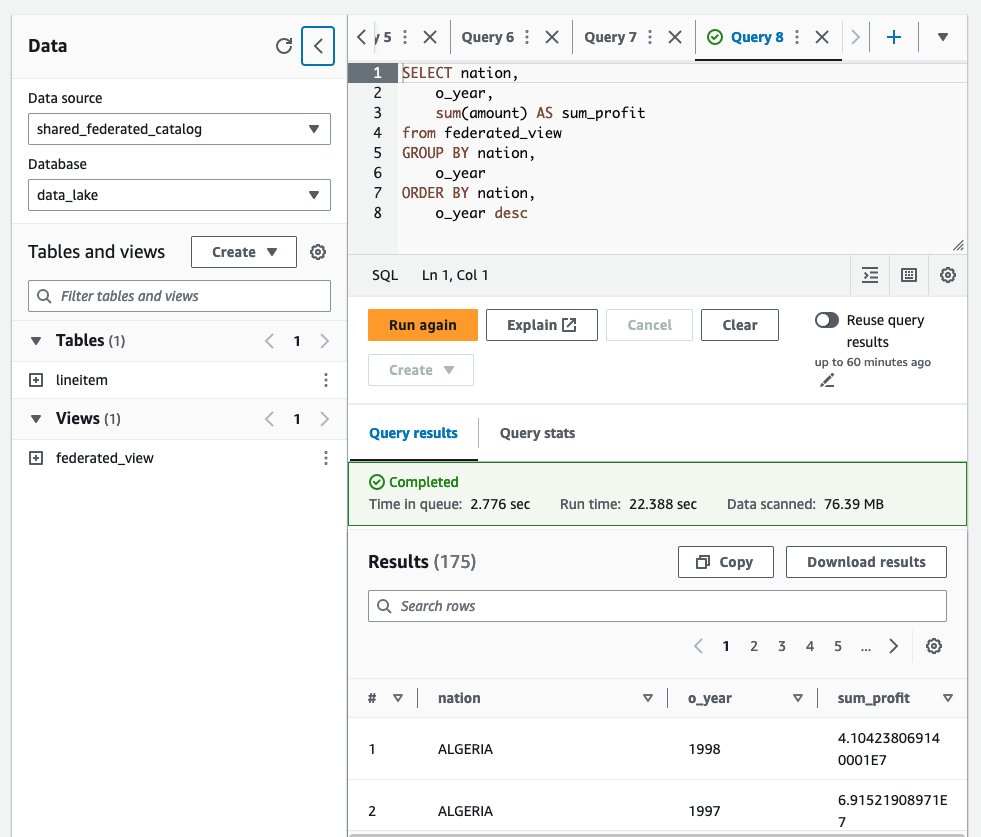
Clean up
To clean up the resources created for this post, complete the following steps:
- On the Amazon S3 console, empty the bucket
athena-federation-workshop-<account-id>. - If you’re using the AWS CLI, delete the objects in the
athena-federation-workshop-<account-id>bucket with the following code. Make sure you run this command on the correct bucket.
aws s3 rm s3://athena-federation-workshop-<account-id> --recursive - On the AWS CloudFormation console or the AWS CLI, delete the stack
athena-federated-view-blog.
Summary
In this post, we demonstrated the functionality of Athena federated views. We created a view spanning four different federated data sources and ran queries against it. We also saw how federated views could be extended to a multi-user data mesh and ran queries from a consumer account.
To take advantage of federated views, ensure you are using Athena engine version 3 and upgrade your data source connectors to the latest version available. For information on how to upgrade a connector, see Updating a data source connector.
About the Authors
 Saurabh Bhutyani is a Principal Big Data Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running scalable analytics solutions and data mesh architectures using AWS analytics services like Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Saurabh Bhutyani is a Principal Big Data Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running scalable analytics solutions and data mesh architectures using AWS analytics services like Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
 Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Big Data Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.