AWS Big Data Blog
Tag: Data Mesh
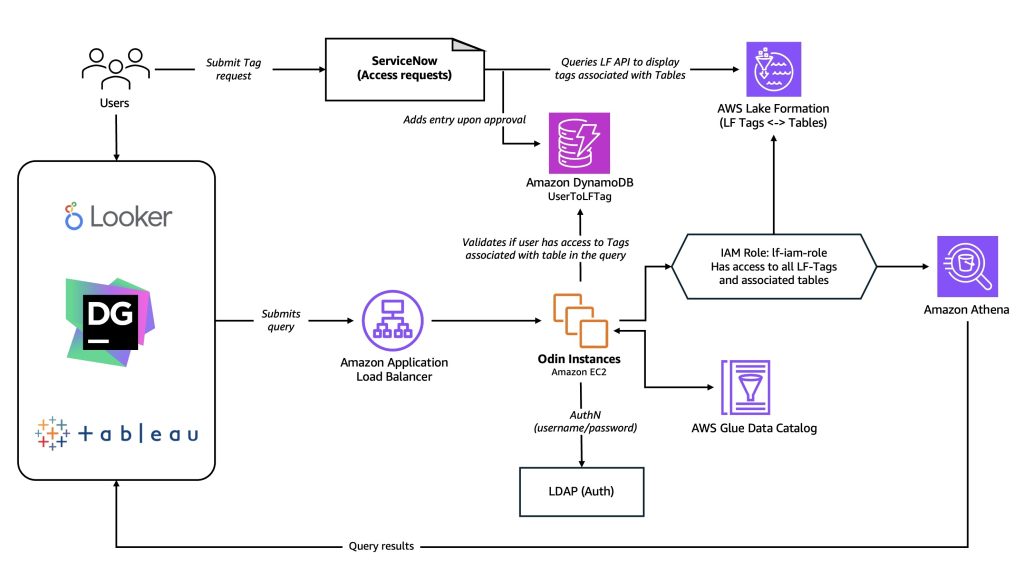
How Twilio secured their multi-engine query platform with AWS Lake Formation
Twilio is a cloud communications platform that provides programmable APIs and tools for developers to easily integrate voice, messaging, email, video, and other communication features into their applications and customer engagement workflows. In this blog series we discuss how we built a multi-engine query platform at Twilio. The first part introduces the use case that led us to build a new platform and why we selected Amazon Athena alongside our open-source Presto implementation. This second part discusses how Twilio’s query infrastructure platform integrates with AWS Lake Formation to provide fine-grained access control to all their data.

Breaking down data silos: Volkswagen’s approach with Amazon DataZone
In this post, we introduce Amazon DataZone and explore how Volkswagen used Amazon DataZone to build their data mesh, tackle the challenges encountered, and break the data silos.

The art and science of data product portfolio management
This post is the first in a series dedicated to the art and science of practical data mesh implementation (for an overview of data mesh, read the original whitepaper The data mesh shift). The series attempts to bridge the gap between the tenets of data mesh and its real-life implementation by deep-diving into the functional […]

Extend your data mesh with Amazon Athena and federated views
Amazon Athena is a serverless, interactive analytics service built on the Trino, PrestoDB, and Apache Spark open-source frameworks. You can use Athena to run SQL queries on petabytes of data stored on Amazon Simple Storage Service (Amazon S3) in widely used formats such as Parquet and open-table formats like Apache Iceberg, Apache Hudi, and Delta […]

Build a multi-Region and highly resilient modern data architecture using AWS Glue and AWS Lake Formation
AWS Lake Formation helps with enterprise data governance and is important for a data mesh architecture. It works with the AWS Glue Data Catalog to enforce data access and governance. Both services provide reliable data storage, but some customers want replicated storage, catalog, and permissions for compliance purposes. This post explains how to create a […]