AWS Big Data Blog
Category: Advanced (300)

Streamline Apache Kafka topic management with Amazon MSK
In this post, we show you how to use the new topic management capabilities of Amazon MSK to streamline your Apache Kafka operations. We demonstrate how to manage topics through the console, control access with AWS Identity and Access Management (IAM), and bring topic provisioning into your continuous integration and continuous delivery (CI/CD) pipelines.

Navigating multi-account deployments in Amazon SageMaker Unified Studio: a governance-first approach
In this post, we explore SageMaker Unified Studio multi-account deployments in depth: what they entail, why they matter, and how to implement them effectively. We examine architecture patterns, evaluate trade-offs across security boundaries, operational overhead, and team autonomy. We also provide practical guidance to help you design a deployment that balances centralized control with distributed ownership across your organization.

Improve the discoverability of your unstructured data in Amazon SageMaker Catalog using generative AI
This is a two-part series post. In the first part, we walk you through how to set up the automated processing for unstructured documents, extract and enrich metadata using AI, and make your data discoverable through SageMaker Catalog. The second part is currently in the works and will show you how to discover and access the enriched unstructured data assets as a data consumer. By the end of this post, you will understand how to combine Amazon Textract and Anthropic Claude through Amazon Bedrock to extract key business terms and enrich metadata using Amazon SageMaker Catalog to transform unstructured data into a governed, discoverable asset.

Build AWS Glue Data Quality pipeline using Terraform
AWS Glue Data Quality is a feature of AWS Glue that helps maintain trust in your data and support better decision-making and analytics across your organization. You can use Terraform to deploy AWS Glue Data Quality pipelines. Using Terraform to deploy AWS Glue Data Quality pipeline enables IaC best practices to ensure consistent, version controlled and repeatable deployments across multiple environments, while fostering collaboration and reducing errors due to manual configuration. In this post, we explore two complementary methods for implementing AWS Glue Data Quality using Terraform.

Automating data classification in Amazon SageMaker Catalog using an AI agent
If you’re struggling with manual data classification in your organization, the new Amazon SageMaker Catalog AI agent can automate this process for you. Most large organizations face challenges with the manual tagging of data assets, which doesn’t scale and is unreliable. In some cases, business terms aren’t applied consistently across teams. Different groups name and tag data assets based on local conventions. This creates a fragmented catalog where discovery becomes unreliable and governance teams spend more time normalizing metadata than governing. In this post, we show you how to implement this automated classification to help reduce the manual tagging effort and improve metadata consistency across your organization.
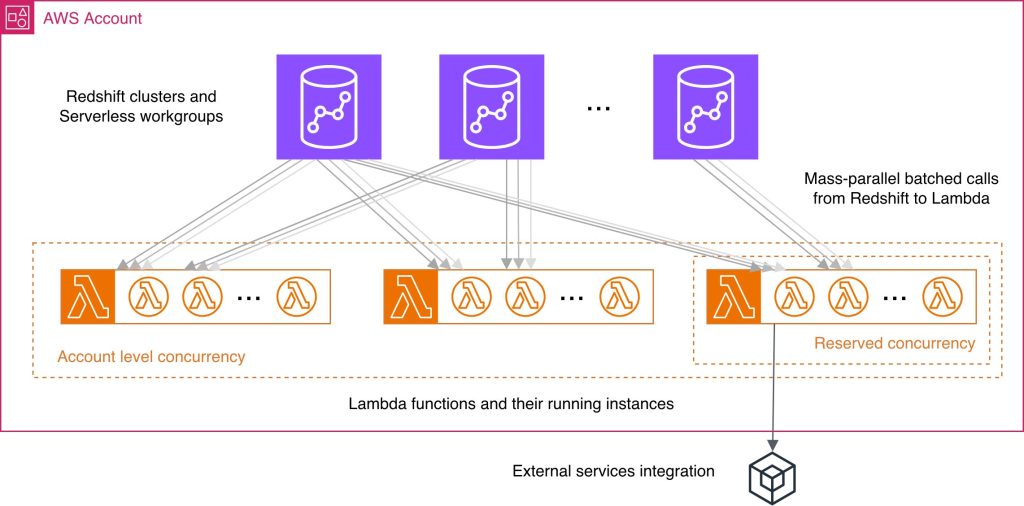
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.

Building a scalable, transactional data lake using dbt, Amazon EMR, and Apache Iceberg
Growing data volume, variety, and velocity has made it crucial for businesses to implement architectures that efficiently manage and analyze data, while maintaining data integrity and consistency. In this post, we show you a solution that combines Apache Iceberg, Data Build Tool (dbt), and Amazon EMR to create a scalable, ACID-compliant transactional data lake. You can use this data lake to process transactions and analyze data simultaneously while maintaining data accuracy and real-time insights for better decision-making.
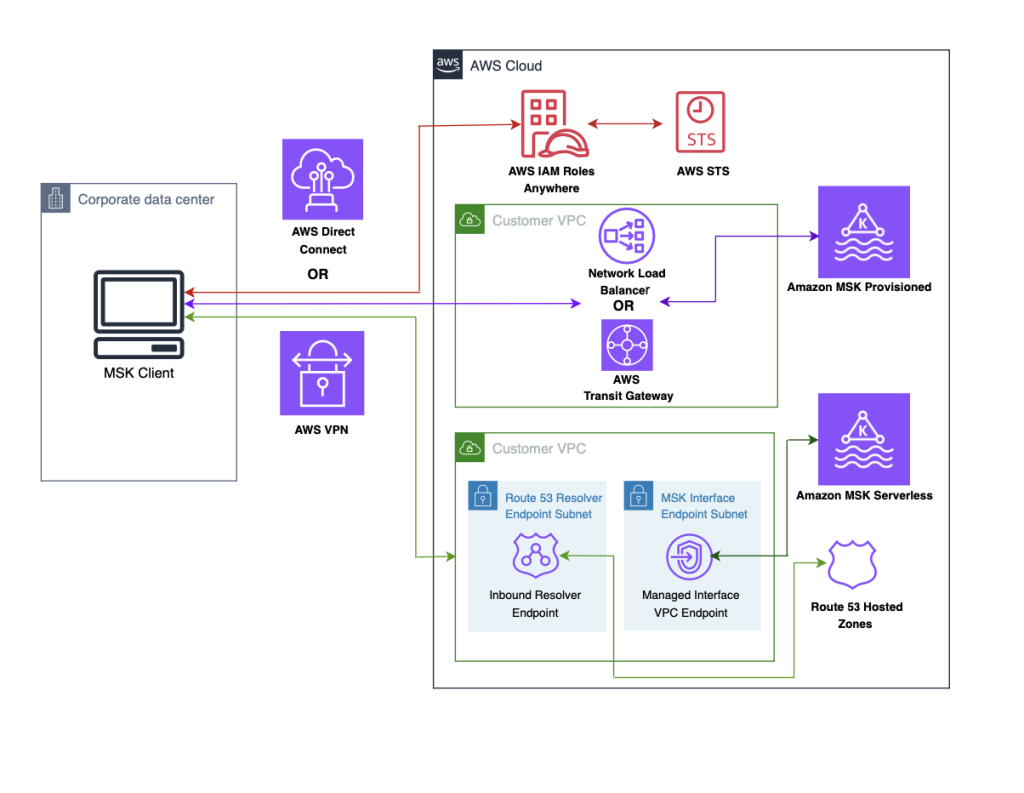
Securely connect Kafka clients running outside AWS to Amazon MSK with IAM Roles Anywhere
In this post, we demonstrate how to use AWS IAM Roles Anywhere to request temporary AWS security credentials, using x.509 certificates for client applications which enables secure interactions with an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster. The solution described in this post is compatible with both Amazon MSK Provisioned and Serverless clusters.

How Razorpay achieved 11% performance improvement and 21% cost reduction with Amazon EMR
In this post, we explore how Razorpay, India’s leading FinTech company, transformed their data platform by migrating from a third-party solution to Amazon EMR, unlocking improved performance and significant cost savings. We’ll walk through the architectural decisions that guided this migration, the implementation strategy, and the measurable benefits Razorpay achieved.

How Amplitude implemented natural language-powered analytics using Amazon OpenSearch Service as a vector database
Amplitude is a product and customer journey analytics platform. Our customers wanted to ask deep questions about their product usage. Ask Amplitude is an AI assistant that uses large language models (LLMs). It combines schema search and content search to provide a customized, accurate, low latency, natural language-based visualization experience to end customers. Amplitude’s search architecture evolved to scale, simplify, and cost-optimize for our customers, by implementing semantic search and Retrieval Augmented Generation (RAG) powered by Amazon OpenSearch Service. In this post, we walk you through Amplitude’s iterative architectural journey and explore how we address several critical challenges in building a scalable semantic search and analytics platform.