AWS Big Data Blog
Category: Intermediate (200)

Simplifying Kafka operations with Amazon MSK Express brokers
In this post, we show you how Amazon Managed Streaming for Apache Kafka (Amazon MSK) Express brokers brokers streamline the end-to-end activities for Kafka administration.

Filter catalog assets using custom metadata search filters in Amazon SageMaker Unified Studio
Finding the right data assets in large enterprise catalogs can be challenging, especially when thousands of datasets are cataloged with organization-specific metadata. Amazon SageMaker Unified Studio now supports custom metadata search filters. In this post, you learn how to create custom metadata forms, publish assets with metadata values, and use structured filters to discover those assets.
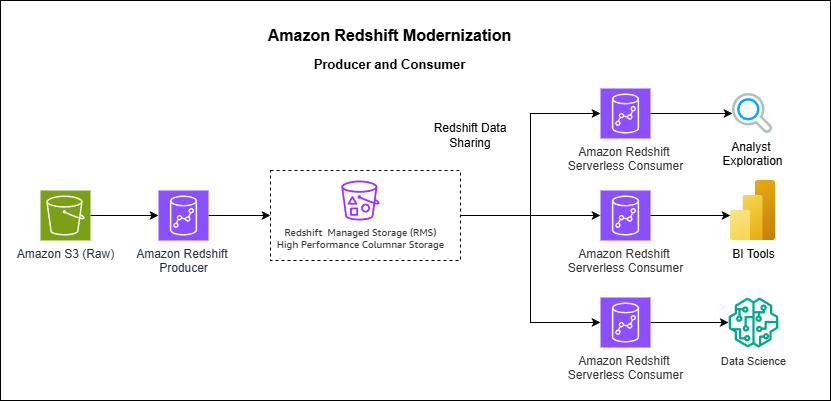
How Vanguard transformed analytics with Amazon Redshift multi-warehouse architecture
In this post, Vanguard’s Financial Advisor Services division describes how they evolved from a single Amazon Redshift cluster to a multi-warehouse architecture using data sharing and serverless endpoints to eliminate performance bottlenecks caused by exponential growth in ETL jobs, dashboards, and user queries.

Amazon Redshift DC2 migration approach with a customer case study
In this post, we share insights from one of our customers’ migration from DC2 to RA3 instances. The customer, a large enterprise in the retail industry, operated a 16-node dc2.8xlarge cluster for business intelligence (BI) and ETL workloads. Facing growing data volumes and disk capacity limitations, they successfully migrated to RA3 instances using a Blue-Green deployment approach, achieving improved ETL query performance and expanded storage capacity while maintaining cost efficiency.

Kinesis On-demand Advantage saves 60%+ on streaming costs
On November 4, 2025, Amazon Kinesis Data Streams introduced On-demand Advantage mode, a capability that enables on-demand streams to handle instant throughput increases at scale and cost optimization for consistent streaming workloads. Historically, you had to choose between provisioned mode, which required managing stream capacity, and on-demand mode, which automatically scaled capacity, but this new offering removes the need to think about stream type at all. In this post, we show three real-world scenarios comparing different usage patterns and demonstrate how On-demand Advantage mode can optimize your streaming costs while maintaining performance and flexibility.
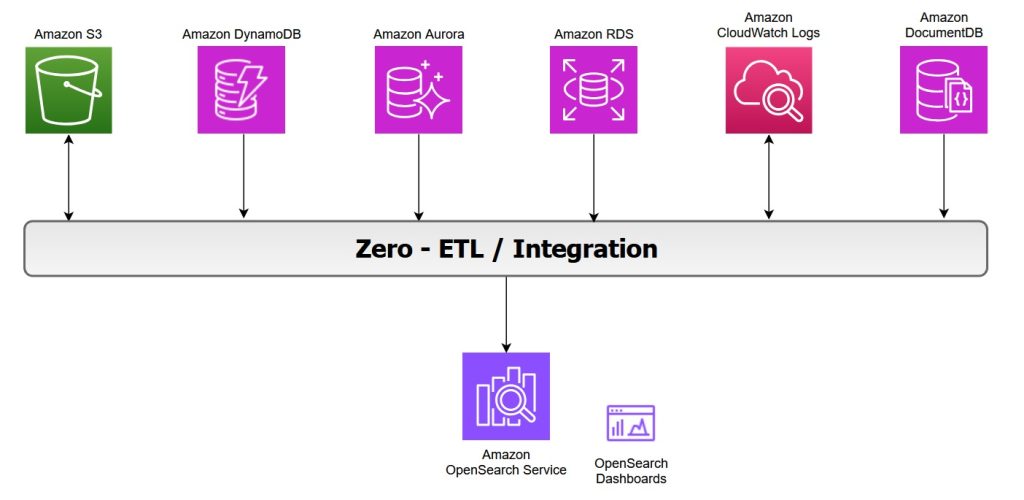
Zero-ETL integrations with Amazon OpenSearch Service
OpenSearch Service offers zero-ETL integrations with other Amazon Web Service (AWS) services, enabling seamless data access and analysis without the need for maintaining complex data pipelines. Zero-ETL refers to a set of integrations designed to minimize or eliminate the need to build traditional extract, transform, load (ETL) pipelines. In this post, we explore various zero-ETL integrations available with OpenSearch Service that can help you accelerate innovation and improve operational efficiency.
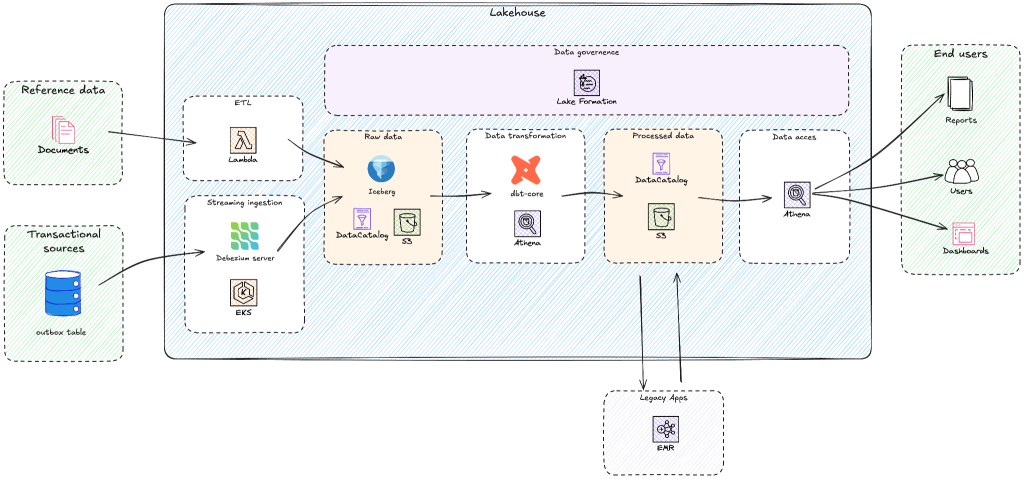
Building a modern lakehouse architecture: Yggdrasil Gaming’s journey from BigQuery to AWS
Yggdrasil Gaming develops and publishes casino games globally, processing massive amounts of real-time gaming data for game performance analytics, player behavior insights, and industry intelligence. Yggdrasil Gaming reduced multi-cloud complexity and built a scalable analytics foundation by migrating from Google BigQuery to AWS analytics services. In this post, you’ll discover how Yggdrasil Gaming transformed their data architecture to meet growing business demands. You will learn practical strategies for migrating from proprietary systems to open table formats such as Apache Iceberg while maintaining business continuity. Yggdrasil worked with GOStack, an AWS Partner, to migrate to an Apache Iceberg-based lakehouse architecture. The migration helped reduce operational complexity and enabled real-time gaming analytics and machine learning.

Standardize Amazon Redshift operations using Templates
In this post, we introduce Redshift Templates and show examples of how they can standardize and simplify your data loading operations across different scenarios. By encapsulating common COPY command parameters into reusable database objects, templates help remove repetitive parameter specifications, facilitate consistency across teams, and centralize maintenance.
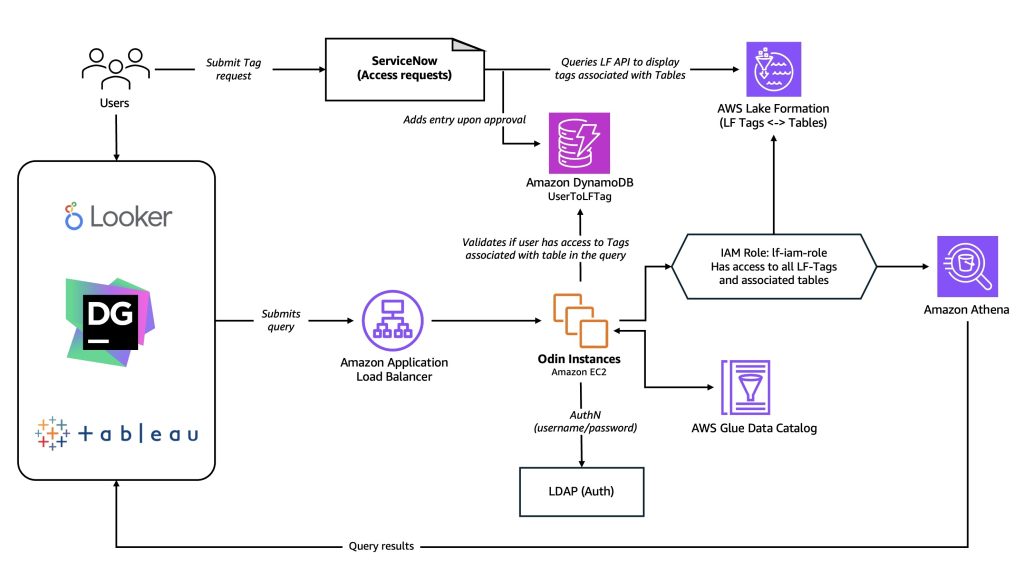
How Twilio secured their multi-engine query platform with AWS Lake Formation
Twilio is a cloud communications platform that provides programmable APIs and tools for developers to easily integrate voice, messaging, email, video, and other communication features into their applications and customer engagement workflows. In this blog series we discuss how we built a multi-engine query platform at Twilio. The first part introduces the use case that led us to build a new platform and why we selected Amazon Athena alongside our open-source Presto implementation. This second part discusses how Twilio’s query infrastructure platform integrates with AWS Lake Formation to provide fine-grained access control to all their data.

Amazon OpenSearch Serverless introduces collection groups to optimize cost for multi-tenant workloads
Today, we’re excited to announce the general availability of the collection groups feature for Amazon OpenSearch Serverless. With this feature you can reduce compute costs for multi-tenant workloads while creating secure tenant boundaries through per-tenant encryption, giving you the flexibility to balance cost efficiency with the exact level of isolation and security your applications requires.