AWS Big Data Blog
How AWS Data Lab helped BMW Financial Services design and build a multi-account modern data architecture
This post is co-written by Martin Zoellner, Thomas Ehrlich and Veronika Bogusch from BMW Group.
BMW Group and AWS announced a comprehensive strategic collaboration in 2020. The goal of the collaboration is to further accelerate BMW Group’s pace of innovation by placing data and analytics at the center of its decision-making. A key element of the collaboration is the further development of the Cloud Data Hub (CDH) of BMW Group. This is the central platform for managing company-wide data and data solutions in the cloud. At the AWS re:Invent 2019 session, BMW and AWS demonstrated the new Cloud Data Hub platform by outlining different archetypes of data platforms and then walking through the journey of building BMW Group’s Cloud Data Hub. To learn more about the Cloud Data Hub, refer to BMW Cloud Data Hub: A reference implementation of the modern data architecture on AWS.
As part of this collaboration, BMW Group is migrating hundreds of data sources across several data domains to the Cloud Data Hub. Several of these sources pertain to BMW Financial Services.
In this post, we talk about how the AWS Data Lab is helping BMW Financial Services build a regulatory reporting application for one of the European BMW market using the Cloud Data Hub on AWS.
Solution overview
In the context of regulatory reporting, BMW Financial Services works with critical financial services data that contains personally identifiable information (PII). We need to provide monthly insights on our financial data to one of the European National Regulator, and we also need to be compliant with the Schrems II and GDPR regulations as we process PII data. This requires the PII to be pseudonymized when it’s loaded into the Cloud Data Hub, and it has to be processed further in pseudonymized form. For an overview of pseudonymization process, check out Build a pseudonymization service on AWS to protect sensitive data .
To address these requirements in a precise and efficient way, BMW Financial Services decided to engage with the AWS Data Lab. The AWS Data Lab has two offerings: the Design Lab and the Build Lab.
Design Lab
The Design Lab is a 1-to-2-day engagement for customers who need a real-world architecture recommendation based on AWS expertise, but aren’t ready to build. In the case of BMW Financial Services, before beginning the build phase, it was key to get all the stakeholders in the same room and record all the functional and non-functional requirements introduced by all the different parties that might influence the data platform—from owners of the various data sources to end-users that would use the platform to run analytics and get business insights. Within the scope of the Design Lab, we discussed three use cases:
- Regulatory reporting – The top priority for BMW Financial Services was the regulatory reporting use case, which involves collecting and calculating data and reports that will be declared to the National Regulator.
- Local data warehouse – For this use case, we need to calculate and store all key performance indicators (KPIs) and key value indicators (KVIs) that will be defined during the project. The historical data needs to be stored, but we need to apply a pseudonymization process to respect GDPR directives. Moreover, historical data has to be accessed on a daily basis through a tableau visualization tool. Regarding the structure, it would be valuable to define two levels (at minimum): one at the contract level to justify the calculation of all KPIs, and another at an aggregated level to optimize restitutions. Personal data is limited in the application, but a reidentification process must be possible for authorized consumption patterns.
- Accounting details – This use case is based on the BMW accounting tool IFT, which provides the accounting balance at the contract level from all local market applications. It must run at least once a month. However, if some issues are identified on IFT during closing, we must be able to restart it and erase the previous run. When the month-end closing is complete, this use case has to keep the last accounting balance version generated during the month and store it. In parallel, all accounting balance versions have to be accessible by other applications for queries and be able to retrieve the information for 24 months.

Based on these requirements, we developed the following architecture during the Design Lab.
This solution contains the following components:
- The main data source that hydrates our three use cases is the already available in the Cloud Data Hub. The Cloud Data Hub uses AWS Lake Formation resource links to grant access to the dataset to the consumer accounts.
- For standard, periodic ETL (extract, transform, and load) jobs that involve operations such as converting data types, or creating labels based on numerical values or Boolean flags based on a label, we used AWS Glue ETL jobs.
- For historical ETL jobs or more complex calculations such as in the account details use case, which may involve huge joins with custom configurations and tuning, we recommended to use Amazon EMR. This gives you the opportunity to control cluster configurations at a fine-grained level.
- To store job metadata that enables features such as reprocessing inputs or rerunning failed jobs, we recommended building a data registry. The goal of the data registry is to create a centralized inventory for any data being ingested in the data lake. A schedule-based AWS Lambda function could be triggered to register data landing on the semantic layer of the Cloud Data Hub in a centralized metadata store. We recommended using Amazon DynamoDB for the data registry.
- Amazon Simple Storage Service (Amazon S3) serves as the storage mechanism that powers the regulatory reporting use case using the data management framework Apache Hudi. Apache Hudi is useful for our use cases because we need to develop data pipelines where record-level insert, update, upsert, and delete capabilities are desirable. Hudi tables are supported by both Amazon EMR and AWS Glue jobs via the Hudi connector, along with query engines such as Amazon Athena and Amazon Redshift Spectrum.
- As part of the data storing process in the regulatory reporting S3 bucket, we can populate the AWS Glue Data Catalog with the required metadata.
- Athena provides an ad hoc query environment for interactive analysis of data stored in Amazon S3 using standard SQL. It has an out-of-the-box integration with the AWS Glue Data Catalog.
- For the data warehousing use case, we need to first de-normalize data to create a dimensional model that enables optimized analytical queries. For that conversion, we use AWS Glue ETL jobs.
- Dimensional data marts in Amazon Redshift enable our dashboard and self-service reporting needs. Data in Amazon Redshift is organized into several subject areas that are aligned with the business needs, and a dimensional model allows for cross-subject area analysis.
- As a by-product of creating an Amazon Redshift cluster, we can use Redshift Spectrum to access data in the regulatory reporting bucket of the architecture. It acts as a front to access more granular data without actually loading it in the Amazon Redshift cluster.
- The data provided to the Cloud Data Hub contains personal data that is pseudonymized. However, we need our pseudonymized columns to be re-personalized when visualizing them on Tableau or when generating CSV reports. Both Athena and Amazon Redshift support Lambda UDFs, which can be used to access Cloud Data Hub PII APIs to re-personalize the pseudonymized columns before presenting them to end-users.
- Both Athena and Amazon Redshift can be accessed via JDBC (Java Database Connectivity) to provide access to data consumers.
- We can use a Python shell job in AWS Glue to run a query against either of our analytics solutions, convert the results to the required CSV format, and store them to a BMW secured folder.
- Any business intelligence (BI) tool deployed on premises can connect to both Athena and Amazon Redshift and use their query engines to perform any heavy computation before it receives the final data to fuel its dashboards.
- For the data pipeline orchestration, we recommended using AWS Step Functions because of its low-code development experience and its full integration with all the other components discussed.
With the preceding architecture as our long-term target state, we concluded the Design Lab and decided to return for a Build Lab to accelerate solution development.
Preparing for Build Lab
The typical preparation of a Build Lab that follows a Design Lab involves identifying a few examples of common use case patterns, typically the more complex ones. To maximize the success in the Build Lab, we reduce the long-term target architecture to a subset of components that addresses those examples and can be implemented within a 3-to-5-day intense sprint.
For a successful Build Lab, we also need to identify and resolve any external dependencies, such as network connectivity to data sources and targets. If that isn’t feasible, then we find meaningful ways to mock them. For instance, to make the prototype closer to what the production environment would look like, we decided to use separate AWS accounts for each use case, based on the existing team structure of BMW, and use a consumer S3 bucket instead of BMW network-attached storage (NAS).
Build Lab
The BMW team set aside 4 days for their Build Lab. During that time, their dedicated Data Lab Architect worked alongside the team, helping them to build the following prototype architecture.
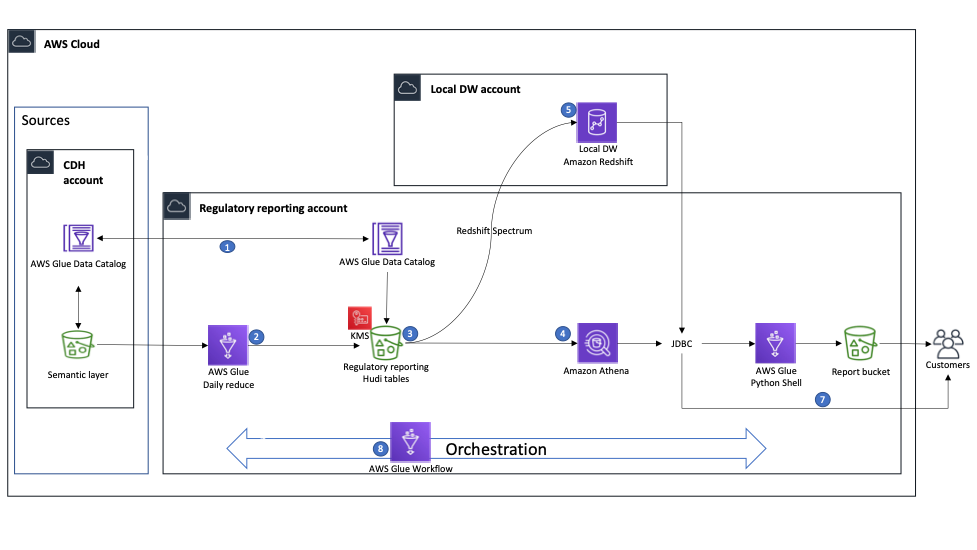
This solution includes the following components:
- The first step was to synchronize the AWS Glue Data Catalog of the Cloud Data Hub and regulatory reporting accounts.
- AWS Glue jobs running on the regulatory reporting account had access to the data in the Cloud Data Hub resource accounts. During the Build Lab, the BMW team implemented ETL jobs for six tables, addressing insert, update, and delete record requirements using Hudi.
- The result of the ETL jobs is stored in the data lake layer stored in the regulatory reporting S3 bucket as Hudi tables that are catalogued in the AWS Glue Data Catalog and can be consumed by multiple AWS services. The bucket is encrypted using AWS Key Management Service (AWS KMS).
- Athena is used to run exploratory queries on the data lake.
- To demonstrate the cross-account consumption pattern, we created an Amazon Redshift cluster on it, created external tables from the Data Catalog, and used Redshift Spectrum to query the data. To enable cross-account connectivity between the subnet group of the Data Catalog of the regulatory reporting account and the subnet group of the Amazon Redshift cluster on the local data warehouse account, we had to enable VPC peering. To accelerate and optimize the implementation of these configurations during the Build Lab, we received support from an AWS networking subject matter expert, who ran a valuable session, during which the BMW team understood the networking details of the architecture.
- For data consumption, the BMW team implemented an AWS Glue Python shell job that connected to Amazon Redshift or Athena using a JDBC connection, ran a query, and stored the results in the reporting bucket as a CSV file, which would later be accessible by the end-users.
- End-users can also directly connect to both Athena and Amazon Redshift using a JDBC connection.
- We decided to orchestrate the AWS Glue ETL jobs using AWS Glue Workflows. We used the resulting workflow for the end-of-lab demo.
With that, we completed all the goals we had set up and concluded the 4-day Build Lab.
Conclusion
In this post, we walked you through the journey the BMW Financial Services team took with the AWS Data Lab team to participate in a Design Lab to identify a best-fit architecture for their use cases, and the subsequent Build Lab to implement prototypes for regulatory reporting in one of the European BMW market.
To learn more about how AWS Data Lab can help you turn your ideas into solutions, visit AWS Data Lab.
Special thanks to everyone who contributed to the success of the Design and Build Lab: Lionel Mbenda, Mario Robert Tutunea, Marius Abalarus, Maria Dejoie.
About the authors
 Martin Zoellner is an IT Specialist at BMW Group. His role in the project is Subject Matter Expert for DevOps and ETL/SW Architecture.
Martin Zoellner is an IT Specialist at BMW Group. His role in the project is Subject Matter Expert for DevOps and ETL/SW Architecture.
 Thomas Ehrlich is the functional maintenance manager of Regulatory Reporting application in one of the European BMW market.
Thomas Ehrlich is the functional maintenance manager of Regulatory Reporting application in one of the European BMW market.
 Veronika Bogusch is an IT Specialist at BMW. She initiated the rebuild of the Financial Services Batch Integration Layer via the Cloud Data Hub. The ingested data assets are the base for the Regulatory Reporting use case described in this article.
Veronika Bogusch is an IT Specialist at BMW. She initiated the rebuild of the Financial Services Batch Integration Layer via the Cloud Data Hub. The ingested data assets are the base for the Regulatory Reporting use case described in this article.
 George Komninos is a solutions architect for the Amazon Web Services (AWS) Data Lab. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent three years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
George Komninos is a solutions architect for the Amazon Web Services (AWS) Data Lab. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent three years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
 Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.
Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.