AWS for Industries
BMW Cloud Data Hub: A reference implementation of the modern data architecture on AWS
BMW Group and Amazon Web Services (AWS) announced a comprehensive strategic collaboration in 2020. The goal of the collaboration is to further accelerate the BMW Group’s pace of innovation by placing data and analytics at the center of its decision-making. A key element of the collaboration is the further development of the Cloud Data Hub (CDH) of the BMW Group. It is the central platform for managing company-wide data and data solutions in the cloud (see the case study).
At the AWS re:Invent 2019 session, BMW Group and AWS demonstrated the new CDH platform by outlining different archetypes of data platforms and then walking through the journey of building BMW Group’s Cloud Data Hub.
In this blog, we will talk about how BMW Group overcame challenges faced in their on-premise data lake by rearchitecting data lake with cloud-native technologies on AWS and rethought our organizational processes around data.
Challenges of an on-premises data lake
To generate these innovations, in 2015 the BMW Group created a centralized, on-premises data lake that collects and combines anonymized data from sensors in vehicles, operational systems, and data warehouses to derive historical, real-time, and predictive insights.
Building and operating an enterprise-grade data lake consumed many resources of development that the team could not focus on providing new features to its customers. Furthermore, as the adoption of the data lake increased, it became harder to scale the computational resources and the resources of the central ingest team that was responsible for onboarding data sources, as depicted in Figure 1.

Figure 1. Legacy on-premises data lake and its challenges
Solution overview of the Cloud Data Hub
We were heavily inspired by the data mesh and data fabric concepts, which were rising in popularity at the same time as the development of the Cloud Data Hub. The data mesh concept focuses on a decentralized, product-driven organization with explicit data products, responsible agile teams, and strong ownership inside domains—values that we already know and love in software development.
In contrast, the data fabric concept is a more centralized, tech-driven approach that focuses on providing a central metadata layer, automating services for data management, and establishing enterprise-wide guardrails. We used these high-level concepts to derive our own set of guiding principles to architect and design our platform. We strove to deliver a self-serve data platform that abstracts away the technical complexity. It revolves around automation, self-service onboarding, and global interoperability standards. Data is treated as an asset provided by data producers toward a data platform. Data assets are defined, read optimized, and ready for broad consumption.
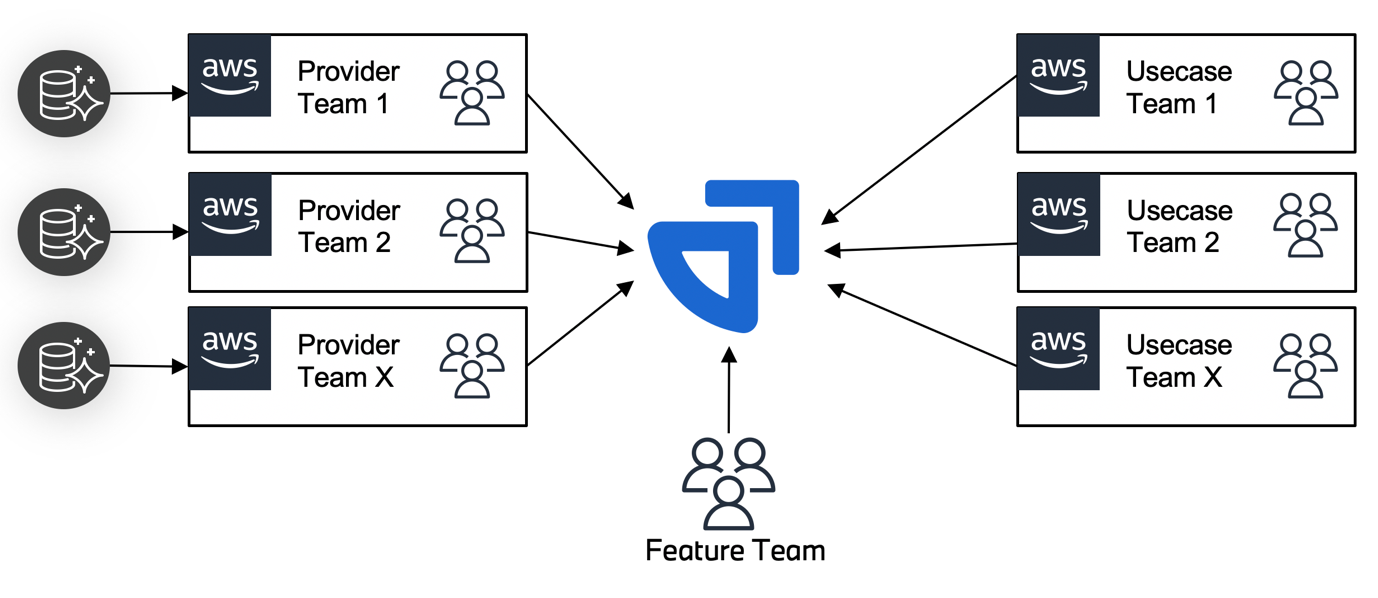
Figure 2. Cloud Data Hub
Data portal provides unified user journey
A highly decentralized architecture and fragmented account structure can be hard to overview, manage, and govern. From a user perspective, this is abstracted by a clear set of APIs for management and, more importantly, the data portal as the single point of entry for all data-related user journeys. This includes all operations on the meta model, like creating, editing, or deleting providers, use cases, or datasets. More importantly, users can directly ingest new data sources, request access to use cases or datasets, explore data through SQL, or create analyses through code workbooks seamlessly through the data portal. The goal is to abstract away the complicated details of the platform and facilitate self-service capabilities for all user groups.

Figure 3. Data portal provides unified user journey
Dataset as logical entity
The central entity on our platform is a dataset. It is our instance of a data product and a container for all metadata and resources related to that entity as shown in Figure 4. The fundamental metadata includes the owner of the dataset, the originating domain, and the staging layer. It works as a bundle for resources that are bound to a specific staging environment and region to store data on Amazon Simple Storage Service (Amazon S3)—an object storage service offering industry-leading scalability, data availability, security, and performance—or table definitions in AWS Glue Data Catalog, which contains references to data that is used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue.

Figure 4. Logical dataset as a container of metadata and resources
Data providers and data consumers are the two fundamental users of a dataset. Datasets are created by data providers that can create any number of datasets in its assigned domains. As the owner of a dataset, they are responsible for the actual content and for providing appropriate metadata. They can use their own toolsets or rely on provided blueprints to ingest the data from source systems. After a dataset has been released for usage, consumers can use the datasets created by different providers for their analyses or machine learning (ML) workloads.
Multi-account strategy
To embrace the idea of a fully decentralized architecture, we use individual AWS accounts as boundaries for data producers and consumers. This approach puts accountability to where the data is produced or consumed. For data producers, it decentralizes the responsibility of data procurement and data quality—accuracy, completeness, reliability, relevance, and freshness—and puts accountability on the data producers because they are the experts on their own data domain. They are responsible for working closely with the data source owners to define how the data is procured.
Similarly for data consumers, having a segregated AWS account provides them with the flexibility to operate and maintain outgoing data pipelines from the data platform. They are free to choose appropriate services for use cases. They are also responsible for their business priorities, analytics development, and creation of new insights.
Using a multi-account strategy helped us to provide a lot of freedom to the data producers and consumers to be as agile and innovative as possible. Because AWS account is the lowest granularity at which the AWS costs are allocated, having individual AWS accounts meant that existing billing and charge-back mechanisms could be easily used. This was extremely important because we wanted to provide disparate development, staging, and production environments that the consumers of the platform are using for building and testing new use cases. To read more about the benefits of using multiple AWS accounts, refer to Organizing Your AWS Environment Using Multiple Accounts.
Decentralized compute and centralized storage
When deciding between decentralized and centralized approaches, we had to consider a range of factors that led us to a decentralized compute and centralized storage model. The data mesh focuses on a decentralized explicit data, products-based approach with the FLAIR principals at the core of it:
- F—findability: The ability to view which data assets are available; access metadata, including ownership and data classification; and other mandatory attributes for data governance and compliance.
- L—lineage: The ability to find data origin, ability to trace data back, and understand and visualize data as it flows through the layers of the data platform. This blog gives a good overview.
- A—accessibility: The ability to request access that grants permission to access the data asset.
- I—interoperability: Data is stored in a format that will be accessible to most, if not all, internal and external processing systems
- R—reusability: Data is registered with a known schema, and attribution of the data source is clear.
However, none of the above principles require centralized storage by itself. The motivation to have centralized storage was to facilitate compliance from the data producers in terms of consistency when providing the data and the related metadata. The centralized storage helped us to avoid repeated efforts of core platform service development and to set guiding principles for the platform. The following diagram illustrates how the central storage accounts were orchestrated. The grey boxes in Figure 5 below mark an account boundary for a stage (dev, int & prod) and hub (global, market1, market2). It is a one-to-many mapping between hub/stage and an AWS account. This ensures the ability for the platform to isolate data based on markets, regulatory, and compliance factors.
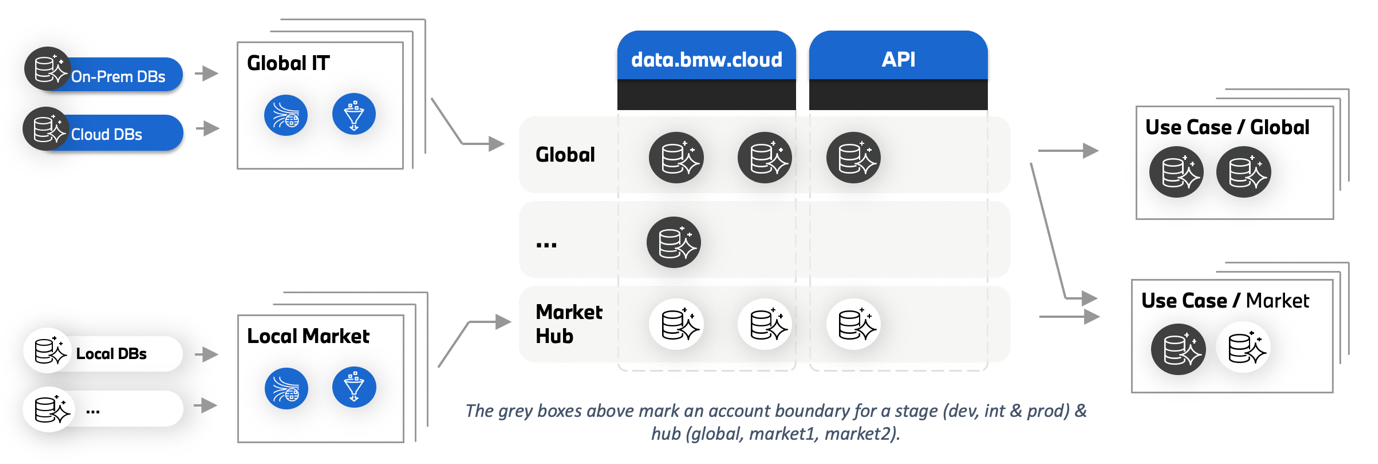
Figure 5. Cloud Data Hub’s decentralized compute, centralized storage, and multi-account strategy
With individual teams in charge of their own AWS accounts, the data provider teams were empowered to oversee their domain and the data being produced. This gave the data provider teams the freedom to choose the tools and services that met their needs. The teams used the AWS analytics services to procure, transform, and store the data in the data platform. This included services like AWS Glue, Amazon EMR, a cloud big data platform, and Amazon Kinesis, which makes it easy to collect, process, and analyze real-time streaming data. Other services included AWS Lambda, a serverless, event-driven compute service, and Amazon Athena, an interactive query service.
A set of reusable blueprints for data provider teams were established to guide the users to follow best practices. The goal of these blueprints was to make teams more agile by reducing manual processes and the slack in the process. A reusable modularized approach made it easier for the data provider teams to focus on the data procurement so the engineers could spend less time on repetitive tasks and more time on high-value tasks with clear business outcomes. The blueprints completely standardized the setup leading to reduced possibility of errors or deviations. This decreased the chances of incompatibility issues and allowed new features to be integrated seamlessly.
Serverless and managed services first
Having a serverless-first, managed-service approach helped the teams developing on Cloud Data Hub to focus on the business challenge at hand and avoid the focus on technical plumbing. Another benefit of using managed services is that the platform benefits from service improvements automatically. A prime example of this is how AWS Glue has gone through multiple improvements and upgrades from 2019 onward, and the platform and its tenants have benefitted from it automatically.
Evolution with AWS Lake Formation with fine-grained access control
Relying on a multi-account strategy to scale and better manage cloud data across various business objects and departments poses its own set of challenges. Prior to the advent of AWS Lake Formation, a service that makes it easy to set up a secure data lake, using a decentralized catalog came with the administrative overhead related to sharing metadata across different accounts. To overcome this, at re:Invent 2020 Cloud Data Hub showcased a catalog synchronization module to synchronize the AWS Glue Data Catalog metadata from one account to another. Prior to the AWS Lake Formation service launch, Cloud Data Hub focused on sharing data at a bucket level. This led to the creation of duplicate datasets with filters so that the appropriate data could be shared with the consumers.
With the adoption of AWS Lake Formation by the Cloud Data Hub, we can address these challenges. Data consumers can request access to respective datasets through the Cloud Data Hub data portal. Data providers who are responsible for granting access to their datasets can grant AWS Lake Formation–based fine-grained permissions to a consumer account based on direct entity sharing or tag-based access controls. They can use row-level or column-level fine-grained access controls. Data providers also have the flexibility to grant full access to the dataset’s underlying Amazon S3 bucket and its objects if they deem it necessary for the use case.
Conclusion
In this blog post, we have shown you how the BMW Group implemented a modern data architecture that helped users of the Cloud Data Hub discover trusted datasets using an advanced search algorithm and easily query data to generate new insights. In doing so, it has overcome the challenges that the company faced with the on-premises data lake. The BMW Group has turned to a mix of AWS Managed Services—including Amazon Athena, Amazon S3, Amazon Kinesis, Amazon EMR, and AWS Glue—to create an environment capable of scaling to meet the dynamic needs of the organization.
Learn more about BMW’s Cloud Data Hub in this 2020 AWS case study, and visit data.bmwgroup.com.