AWS Big Data Blog
How Socure achieved 50% cost reduction by migrating from self-managed Spark to Amazon EMR Serverless
Socure is one of the leading providers of digital identity verification and fraud solutions. Its predictive analytics platform applies artificial intelligence (AI) and machine learning (ML) techniques to process both online and offline intelligence, including government-issued documents, contact information (email, phone, address), personal identifiers (DOB, SSN), and device or network data (IP, velocity) to verify identities accurately and in real time.
Socure ID+ is an identity verification platform that uses multiple Socure offerings such as KYC, SIGMA, eCBSV. Phone Risk and more. It has two environments focused on proof of concept (POC) and live customers. The Data Science (DS) environment is designed for the POC or proof of value (POV) stage. In this environment, customers provide datasets via SFTP, which are processed by Socure’s data scientists through an internal endpoint. The data undergoes ML-based scoring and other intelligence calculations depending on the selected modules and processed results are stored in Amazon Simple Storage Service (Amazon S3) in delta open table format . In the Production (Prod) environment, customers can verify identities either in real time through live endpoints or via a batch processing interface.
Socure’s data science environment includes a streaming pipeline called Transaction ETL (TETL), built on OSS Apache Spark running on Amazon EKS. TETL ingests and processes data volumes ranging from small to large datasets while maintaining high-throughput performance.
The primary purpose of this pipeline is to give data scientists a flexible environment to run POC workloads for customers.
Data scientists…
- trigger ingestion of POC datasets, ranging from small batches to large-scale volumes.
- consume the processed outputs written by the pipeline for analysis and model development.
- share the results with Socure’s customers.
The following diagram shows the Transaction ETL (TETL) architecture.

This pipeline directly supports customer POCs, ensuring that the right data is available for experimentation, validation, and demonstration. As such, it is a critical link between raw data and customer-facing outcomes, making its reliability and performance essential for delivering value. In this post, we show how Socure was able to achieve 50% cost reduction by migrating the TETL streaming pipeline from self-managed spark to Amazon EMR serverless.
Motivation
As data volumes have scaled by 10x, several challenges like latency and data reliability have emerged that directly impact the customer experience:
- Performance issues due to inefficient autoscaling leading to increase in latency up to 5x
- High operational cost of maintaining an OSS Spark environment on EKS
Additionally, we have identified other important issues:
- Resource constraints due to instance provisioning limits, forcing the use of smaller nodes. This leads to frequent spark executor out of memory (OOM) failures under heavy loads, increasing job latency and delaying data availability.
- Performance bottlenecks with Delta Lake, where large batch operations such as OPTIMIZE compete for resources and slow down streaming workloads.
During this migration, we also took the opportunity to transition to AWS Graviton, enabling additional cost efficiencies as explained in this post.
With these two primary drivers we began exploring alternative architecture using Amazon EMR. We already dd extensive benchmarking on several identity verification related batch workloads on different EMR platforms and came to the conclusion that Amazon EMR Serverless (EMR-S) offers a path to reduce operational cost, improve reliability, and better handle large-scale batch and streaming workloads; tackling both customer-facing issues and platform-level inefficiencies.
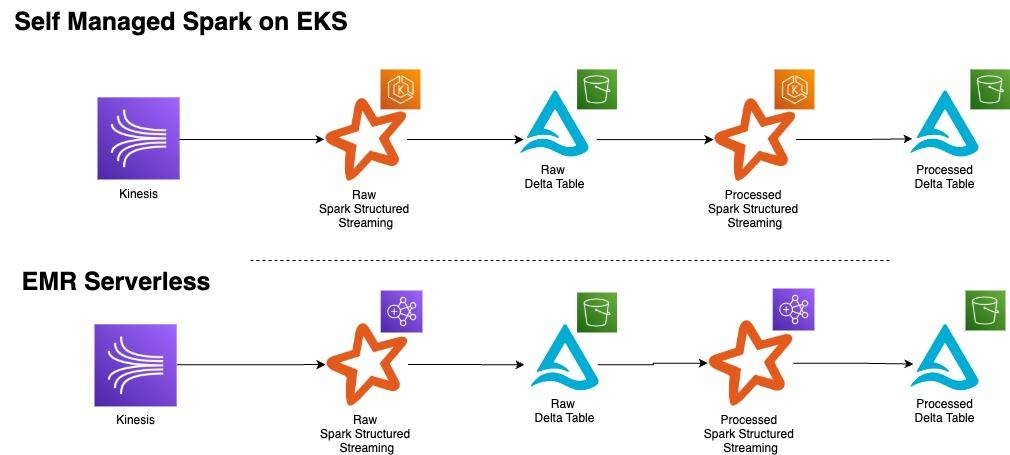
The new pipeline architecture
The data processing pipeline follows a two-stage architecture where streaming data from Amazon Kinesis Data Stream first flows into the raw layer, which parses incoming data into large JSON blobs, applies encryption, and stores the results in append-only Delta Tables. The processed layer consumes data from these raw Delta tables, performs decryption, transforms the data into a flattened and wide structure with proper field parsing, applies individual encryption to personally identifiable information (PII) fields, and writes the refined data to separate append-only Delta Tables for downstream consumption.
The following diagram shows the TETL before/after architecture we implemented, transitioning from OSS Spark on EKS to Spark on EMR Serverless.
Benchmarking
We benchmarked end-to-end pipeline performance across OSS Spark on EKS and EMR Serverless. The evaluation focused on latency and cost under comparable resource configurations.
Resource Configuration
EKS (OSS Spark):
- Min 30 executors
- Max 90 executors
- 14 GB memory / 2 cores per executor
EMR Serverless:
- Min 10 executors
- Max 30 executors
- 27 GB memory / 4 cores per executor
- Effectively ~60 executors when normalized for 2x memory and cores, designed to mitigate the OOM issues described earlier.
Observations
- Autoscaling Efficiency: EMR Serverless scaled down effectively to 20 workers on average over the weekend (low traffic day), resulting in lower costs up to 12% compared to weekday.
- Executor Sizing: Larger executors on EMR Serverless prevented OOM failures and improved stability under load.
Definitions
- Cost: It is the service cost for both raw & processed jobs from the AWS Cost Explorer.
- Latency: End-to-end latency measures the time from Socure ID+ event generation until data arrives in the processed delta table, calculated as Inserted Date minus Event Date.
Results
The values in the following table represent percentage improvements observed when running on EMR compared to EKS.
| Low Traffic (Weekend) | Regular Traffic (Weekday) | |
| Records Count | ~1M | ~5M |
| Min Latency (best case) | 73.3% | 69.2% |
| Avg Latency (representative workload) | 51.0% | 47.9% |
|
Max Latency (worst case) |
12.3% | 34.7% |
| Total Cost | 57.1% | 45.2% |
Note: Even with a conservative 40% cost reduction applied to the EKS environment to account for Graviton, EMR-S remains approximately 15% cheaper.
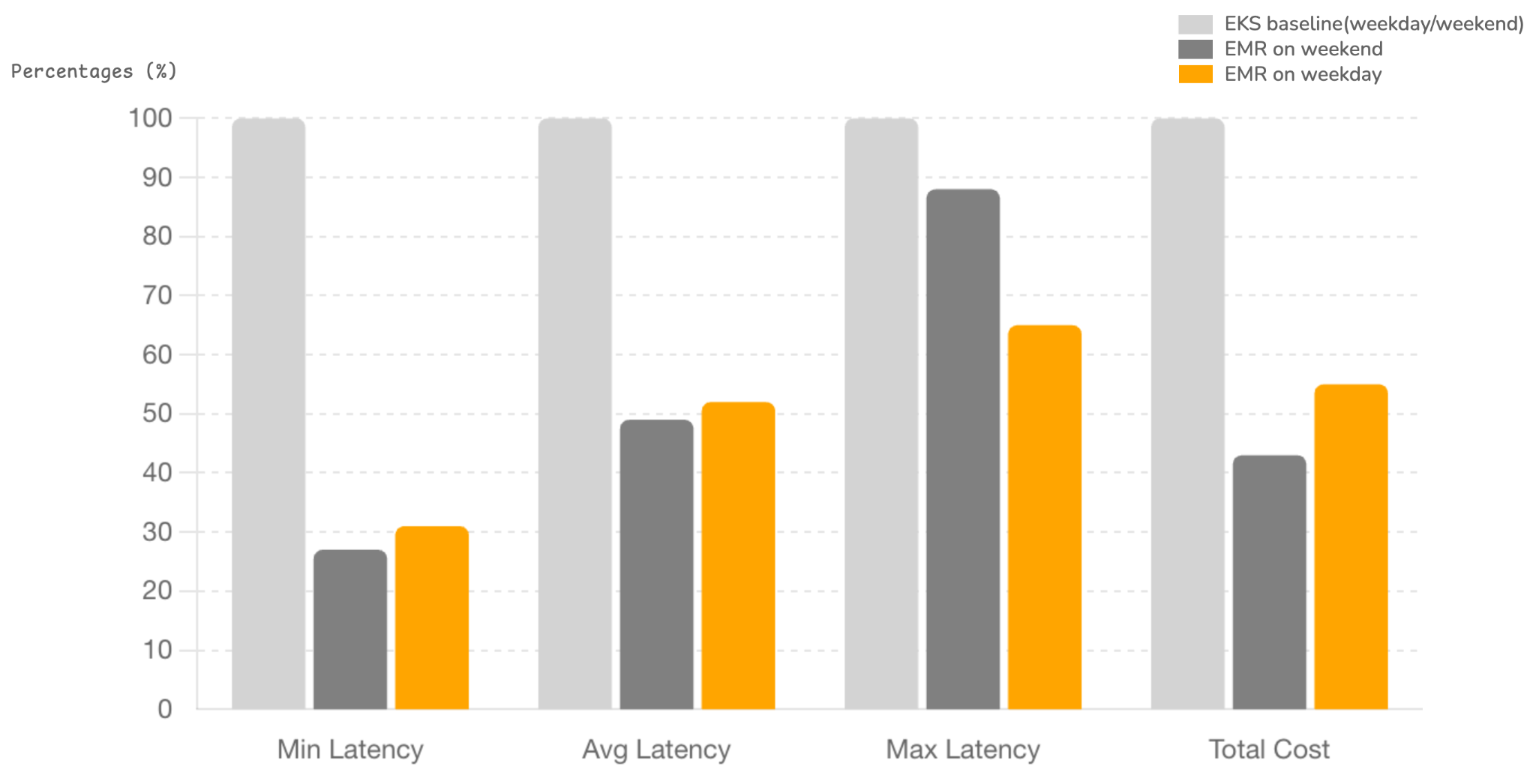
The benchmarking results clearly demonstrate that EMR Serverless outperforms OSS Spark on EKS for our end-to-end pipeline workloads. By moving to EMR Serverless, we achieved:
- Improved performance: Average latency reduced by more than 50%, with consistently lower min and max latencies.
- Cost efficiency: Overall pipeline execution costs dropped by more than half.
- Scalability: Autoscaling optimized resource usage, further lowering cost during off-peak periods.
- Operational overhead: EMR-S fully managed and serverless nature eliminates the need to maintain EKS and OSS Spark.
Conclusion
In this post, we showed how Socure transitioning to EMR Serverless not only resolved critical issues around cost, reliability, and latency, but also provided a more scalable and sustainable architecture for serving customer POCs effectively, enabling us to deliver results to customers faster and strengthen our position for potential custom contracts.