What is a Data Pipeline?
What is a Data Pipeline?
A data pipeline is a series of processing steps to prepare enterprise data for analysis. Organizations have a large volume of data from various sources like applications, Internet of Things (IoT) devices, and other digital channels. However, raw data is useless; it must be moved, sorted, filtered, reformatted, and analyzed for business intelligence. A data pipeline includes various technologies to verify, summarize, and find patterns in data to inform business decisions. Well-organized data pipelines support various big data projects, such as data visualizations, exploratory data analyses, and machine learning tasks.
What are the benefits of a data pipeline?
Data pipelines let you integrate data from different sources and transform it for analysis. They remove data silos and make your data analytics more reliable and accurate. Here are some key benefits of a data pipeline.
Improved data quality
Data pipelines clean and refine raw data, improving its usefulness for end users. They standardize formats for fields like dates and phone numbers while checking for input errors. They also remove redundancy and ensure consistent data quality across the organization.
Efficient data processing
Data engineers have to perform many repetitive tasks while transforming and loading data. Data pipelines allow them to automate data transformation tasks and focus instead on finding the best business insights. Data pipelines also help data engineers more quickly process raw data that loses value over time.
Comprehensive data integration
A data pipeline abstracts data transformation functions to integrate data sets from disparate sources. It can cross-check values of the same data from multiple sources and fix inconsistencies. For example, imagine that the same customer makes a purchase from your ecommerce platform and your digital service. However, they misspell their name in the digital service. The pipeline can fix this inconsistency before sending the data for analytics.
How does a data pipeline work?
Just like a water pipeline moves water from the reservoir to your taps, a data pipeline moves data from the collection point to storage. A data pipeline extracts data from a source, makes changes, then saves it in a specific destination. We explain the critical components of data pipeline architecture below.
Data sources
A data source can be an application, a device, or another database. Disparate sources may push data into the pipeline. The pipeline may also extract data points using an API call, webhook, or data duplication process. You can synchronize data extraction for real-time processing or collect data in scheduled intervals from your data sources.
Transformations
As raw data flows through the pipeline, it changes to become more useful for business intelligence. Transformations are operations—such as sorting, reformatting, deduplication, verification, and validation—that change data. Your pipeline can filter, summarize, or process data to meet your analysis requirements.
Dependencies
As changes happen sequentially, specific dependencies may exist that reduce the speed of moving data in the pipeline. There are two main types of dependencies—technical and business. For example, if the pipeline has to wait for a central queue to fill up before proceeding, it’s a technical dependency. Conversely, if the pipeline has to pause until another business unit cross-verifies the data, it’s a business dependency.
Destinations
The endpoint of your data pipeline can be a data warehouse, data lake, or another business intelligence or data analysis application. Sometimes the destination is also called a data sink.
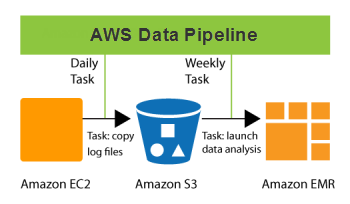
What are the types of data pipelines?
There are two main types of data pipelines—stream processing pipelines and batch processing pipelines.
Stream processing pipelines
A data stream is a continuous, incremental sequence of small-sized data packets. It usually represents a series of events occurring over a given period. For example, a data stream could show sensor data containing measurements over the last hour. A single action, like a financial transaction, can also be called an event. Streaming pipelines process a series of events for real-time analytics.
Streaming data requires low latency and high fault tolerance. Your data pipeline should be able to process data even if some data packets are lost or arrive in a different order than expected.
Batch processing pipelines
Batch processing data pipelines process and store data in large volumes or batches. They are suitable for occasional high-volume tasks like monthly accounting.
The data pipeline contains a series of sequenced commands, and every command is run on the entire batch of data. The data pipeline gives the output of one command as the input to the following command. After all data transformations are complete, the pipeline loads the entire batch into a cloud data warehouse or another similar data store.
Difference between batch and streaming data pipelines
Batch processing pipelines run infrequently and typically during off-peak hours. They require high computing power for a short period when they run. In contrast, stream processing pipelines run continuously but require low computing power. Instead, they need reliable, low-latency network connections.
What is the difference between data pipelines and ETL pipelines?
An extract, transform, and load (ETL) pipeline is a special type of data pipeline. ETL tools extract or copy raw data from multiple sources and store it in a temporary location called a staging area. They transform data in the staging area and load it into data lakes or warehouses.
Not all data pipelines follow the ETL sequence. Some may extract the data from a source and load it elsewhere without transformations. Other data pipelines follow an extract, load, and transform (ELT) sequence, where they extract and load unstructured data directly into a data lake. They perform changes after moving the information to cloud data warehouses.
How can AWS support your data pipeline requirements?
AWS Glue is a serverless data integration service that makes it easier for analytics users to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning, and application development.
- You can discover and connect to 80+ diverse data stores.
- You can manage your data in a centralized data catalog.
- Data Engineers, ETL developers, data analysts, and business users can use AWS Glue Studio to create, run, and monitor ETL pipelines to load data into data lakes.
- AWS Glue Studio offers Visual ETL, Notebook, and code editor interfaces, so users have tools appropriate to their skillsets.
- With Interactive Sessions, data engineers can explore data as well as author and test jobs using their preferred IDE or notebook.
- AWS Glue is serverless and automatically scales on demand, so you can focus on gaining insights from petabyte-scale data without managing infrastructure.
Get started with AWS Glue by creating an AWS account.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages