AWS Big Data Blog
Implement anti-money laundering solutions on AWS
The detection and prevention of financial crime continues to be an important priority for banks. Over the past 10 years, the level of activity in financial crimes compliance in financial services has expanded significantly, with regulators around the globe taking scores of enforcement actions and levying $36 billion in fines. Apart from the fines, the overall cost of compliance for global financial services companies is suspected to have reached $181 billion in 2020. For most banks, know your customer (KYC) and anti-money laundering (AML) constitute the largest area of concern within the broader financial crime compliance. In light of this, there is an urgent need to have effective AML systems that are scalable and fit for purpose in order to manage the risk of money laundering as well as the risk of non-compliance by the banks. Addressing money laundering at a high-level covers the following areas:
- Client screening and identity
- Transaction monitoring
- Extended customer risk profile
- Reporting of suspicious transactions
In this post we focus on transaction monitoring by looking at the general challenges with implementing transaction monitoring (TM) solutions and how AWS services can be leveraged to build a solution in the cloud from the perspectives of data analytics; risk management and ad hoc analysis. The following diagram is a conceptual architecture for a transaction monitoring solution on the AWS Cloud.
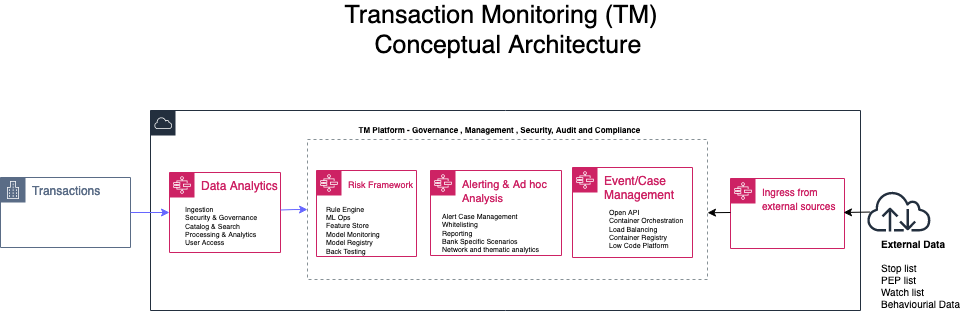
Current challenges
Due to growing digital channels for facilitating financial transactions, the increasing access to financial services for more people, and the growth in global payments; capturing and processing data related to TM is now considered a big data challenge. The big data challenges and observations include:
- The volume of data continues to prove to be too expansive for effective processing in a traditional on-premises data center solution.
- The velocity of banking transactions continues to rise despite the economic challenges of COVID-19.
- The variety of the data that needs to be processed for TM platforms continues to increase as more data sources with unstructured data become available. These data sources require techniques such as optical character recognition (OCR) and natural language processing (NLP) to automate the process of getting value out of such data without excessive manual effort.
- Finally, due to the layered nature of complex transactions involved in TM solutions, having data aggregated from multiple financial institutions provides a more comprehensive insight into the flow of financial transactions. Such an aggregation is usually less viable in a traditional on-premises solution.
Data Analytics
The first challenge with implementing TM solutions is having the tools and services to ingest data into a central store (often called a data lake) that is secure and scalable. Not only does this data lake need to capture terabytes or even petabytes of data, but it also needs to facilitate the process of moving data in and out of purpose-built data stores for time series, graph, data marts, and machine learning (ML) processing. In AWS, we refer to a data architecture which covers data lakes, purpose-built data stores and the data movement across data stores as a lake house architecture.
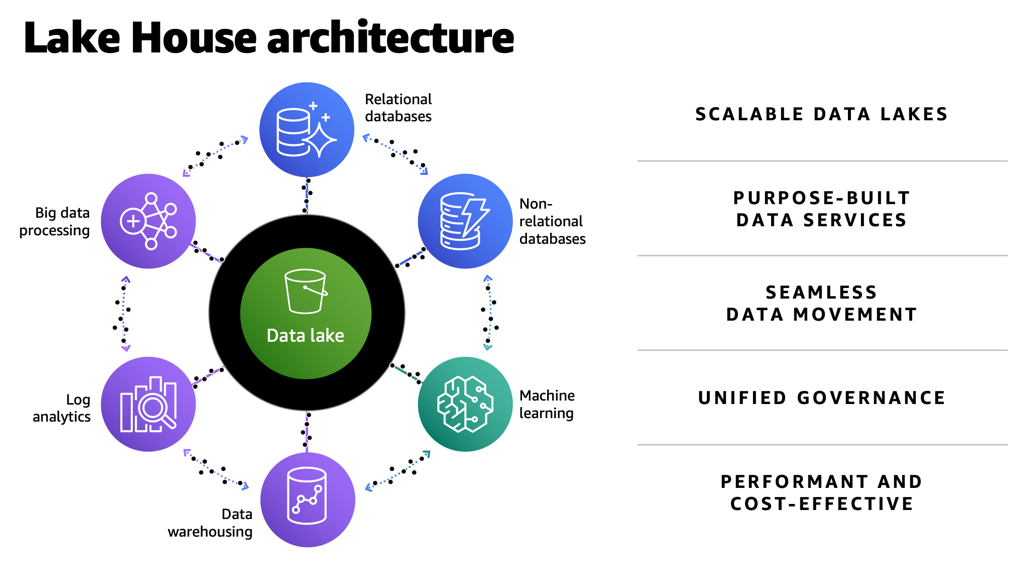
The following diagram illustrates a TM architecture on the AWS Cloud. This is a more detailed sample architecture of the lake house approach.
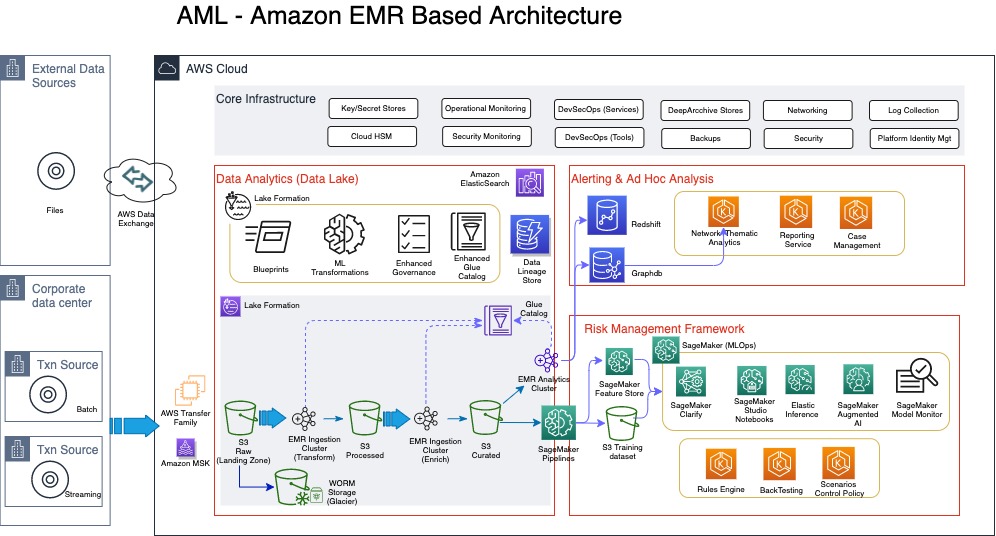
Ingestion of data into the lake house typically comes from a client’s data center (if the client is not already on the cloud), or from different client AWS accounts that host transaction systems or from external sources. For clients with transaction systems still on premises, we notice although several AWS services can be used to transfer data from on premises to the AWS Cloud, a number of our clients with a batch requirement utilize AWS Transfer Family, which provides fully managed support for secure file transfers directly into and out of Amazon Simple Storage Service (Amazon S3) or Amazon Elastic File System (Amazon EFS). With real-time requirements, we see the use of Amazon Managed Streaming for Apache Kafka (Amazon MSK), which is a fully managed service that makes it easy for you to build and run applications that use Apache Kafka to process streaming data. One other way to bring in reference data or external data like politically exposed persons (PEP) lists, watch lists, or stop lists for the AML process is via AWS Data Exchange, which makes it easy to find, subscribe to, and use third-party data in the cloud.
In this architecture, the ingestion process always stores the raw data in Amazon S3, which offers industry-leading scalability, data availability, security, and performance. For those clients already on the AWS Cloud, it’s very likely your data is already stored in Amazon S3.
For TM, the ingestion of the data comes from KYC systems, customer account stores, as well as transaction repositories. Data from KYC systems need to have the entity information, which can relate to a company or individual. For the corporate entities, information on the underlying beneficiary owners (UBOs)—the natural persons who directly or indirectly own or control a certain percentage of company—is also required. Before we discuss the data pipeline (the flow of data from the landing zone to the curated data layer) in detail, it’s important to address some of the security and audit requirements of the sensitive data classes typically used in AML processing.
According to Gartner, “Data governance is the specification of decision rights and an accountability framework to ensure the appropriate behavior in the valuation, creation, consumption, and control of data and analytics.” From an AML perspective, the specification and the accountable framework mentioned in this definition requires several enabling components.
The first is a data catalog, which is sometimes grouped into technical, process, and business catalogs. On the AWS platform, this catalog is provided either directly through AWS Glue or indirectly through AWS Lake Formation. Although the catalog implemented by AWS Glue is fundamentally a technical catalog, you can still extend it to add process and business relevant attributes.
The second enabling component is data lineage. This service should be flexible enough to support the different types of data lineage, namely vertical, horizontal, and physical. From an AML perspective, vertical lineage can provide a trace from AML regulation, which requires the collection of certain data classes, all the way to the data models captured in the technical catalog. Horizontal and physical lineage provide a trace of the data from source to eventual suspicious activity reporting for suspected transactions. Horizonal lineage provides lineage at the metadata level, whereas physical lineage captures trace at the physical level.
The third enabling component of data governance is data security. This covers several aspects of dealing with requirements of encryption of data at rest and in transit, but also de-identification of data during processing. This area requires a range of de-identification techniques depending on the context of use. Some of the techniques include tokenization, encryption, generalization, masking, perturbation, redaction, and even substitution of personally identifiable information (PII) or sensitive data usually at the attribute level. It’s important to use the right de-identification technique to enforce the right level of privacy while still ensuring the data still has sufficient inference signals for use in ML. You can use Amazon Macie, a fully managed data security and data privacy service that uses ML and pattern matching to discover and protect sensitive data, to automate PII discovery prior to applying the right de-identification technique.
Moving data from landing zone (raw data) all the way to curated data involves several steps of processing, including data quality validation, compression, transformation, enrichment, de-duplication, entity resolution, and entity aggregation. Such processing is usually referred to as extract, transform, and load (ETL). In this architecture, we have a choice of using a serverless architecture based on AWS Glue (using Scala or Python programming languages) or implementing Amazon EMR (a cloud big-data platform for processing large datasets using open-source tools such as Apache Spark and Hadoop). Amazon EMR provides the flexibility to run these ETL workloads on Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Kubernetes Service (Amazon EKS) clusters and also on AWS Outposts.
Risk management framework
The risk management framework part of the architecture contains the rules, thresholds, algorithms, models, and control policies that govern the process of detecting and reporting suspicious transactions. Traditionally, most TM solutions have relied solely on rule-based controls to implement AML requirements. However, these rule-based implementations quickly become complex and difficult to maintain, as criminals find new and sophisticated ways to circumvent existing AML controls. Apart from the complexity and maintenance, rule-based approaches usually result in large number of false positives. False positives in this context are when transactions are flagged as suspicious but turn out not to be. Some of the numbers here are quite remarkable, with some studies revealing less than 2% of cases actually turning to be suspicious. The implication of this is the operational costs and the teams of operational resources required to investigate these false positives. Another implication that sometimes get overlooked is the customer experience, in which a customer service like payment or clearing of transactions is delayed or declined due to false positives. This usually leads to a less than satisfactory customer experience. Despite the number of false positives, AML failings and subsequent fines are hardly out of the news; in one case the Financial Conduct Authority (FCA) in the United Kingdom deciding to take the unprecedented step of bringing criminal proceedings against a bank over failed AML processes.
In light of some of the shortcomings of a rule-based AML approach, a lot of research and focus has been performed by financial services customers, including RegTechs, on applying ML to detect suspicious transactions. One comprehensive study on the use of ML techniques in suspicious transaction detection is a paper published by Z. Chen et al. This paper was published in 2018 (which in ML terms is a lifetime ago), but the concepts and findings are still relevant. The paper highlights some of the common algorithms and challenges with using ML for AML. AML data is a high-dimensional space that usually requires dimensionality reduction through the use of algorithms like Principal Component Analysis (PCA) or autoencoders (neural networks used to learn efficient data encodings in an unsupervised manner). As part of feature engineering, most algorithms require the value of transactions (debits and credits) aggregated by time intervals—daily, weekly, and monthly. Clustering algorithms like k-means or some variants of k-means are used to create clusters for customer or transaction profiles. There is also the need to deal with class imbalance usually found in AML datasets.
All of these algorithms referenced in the Z. Chen et al paper are supported by Amazon SageMaker. SageMaker is a fully managed ML service that allows data scientists and developers to easily build, train, and deploy ML models for AML. You can also implement some of the other categories of algorithms that support AML such as behavioral modelling, risk scoring, and anomaly detection with SageMaker. You can use a wide range of algorithms to address AML challenges, including supervised, semi-supervised, and unsupervised models. Some additional factors that determine the suitability of algorithms include high recall and precision rate of the models, and the ability to utilize approaches such as SHapley Additive exPlanation (SHAP) and Local Interpretable Model-Agnostic Explanations (LIME) values to explain the model output. Amazon SageMaker Clarify can detect bias and increases transparency of ML models.
Algorithms that focus on risk scoring enable a risk profile that can span across various data classes such as core customer attributes including industry, geography, bank product, business size, complex ownership structure for entities, as well as transactions (debits and credits) and frequency of such transactions. In addition, external data such as PEP lists, various stop lists and watch lists, and in some cases media coverage related to suspected fraud or corruption can also be weighted into a customer’s risk profile.
Rule-based and ML approaches aren’t mutually exclusive, but it’s likely that rules will continue to play a peripheral role as better algorithms are researched and implemented. One of the reasons why the development of algorithms for AML has been sluggish is the availability of reliable datasets, which include result data indicating when a correct suspicious activity report (SAR) was filed for a given scenario. Unlike other areas of ML in which findings have been openly shared for further research, with AML, a lot of the progress first appears in commercial products belonging to vendors who are protective of their intellectual property.
Ad hoc analysis and reporting
The final part of the architecture includes support for case or event management tooling and a reporting service for the eventual SAR. These services can be AWS Marketplace solutions or developed from scratch using AWS services such as Amazon EKS or Amazon ECS. This part of the architecture also provides support for a very important aspect of AML: network analytics. Network or link analysis has three main components:
- Clustering – The construction of graphs and representation of money flow. Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets.
- Statistical analysis – Used to assist with finding metrics around centrality, normality, clustering, and eigenvector centrality.
- Data visualization – An interactive and extensible data visualization platform to support exploratory data analysis. Findings from the network analytics can also feed into customer risk profiles and supervised ML algorithms.
Conclusion
None of the services or architecture layers described in this architecture are tightly coupled; different layers and services can be swapped with AWS Marketplace solutions or other FinTech or RegTech solutions that support cloud-based deployment. This means the AWS Cloud has a powerful ecosystem of native services and third-party solutions that can be deployed on the foundation of a Lake House Architecture on AWS to build a modern TM solution in the cloud. To find out more information about key of parts of the architecture described in this post, refer to the following resources:
For seeding data into a data lake (including taking advantage of ACID compliance):
- Simplify data integration pipeline development using AWS Glue custom blueprints
- Effective data lakes using AWS Lake Formation, Part 1: Getting started with governed tables
- Effective data lakes using AWS Lake Formation, Part 2: Creating a governed table for streaming data sources
For using Amazon EMR for data pipeline processing and some of recent updates to the Amazon EMR:
- Orchestrate an Amazon EMR on Amazon EKS Spark job with AWS Step Functions
- Amazon EMR 2020 year in review
For taking advantage of SageMaker to support financial crime use cases:
- Creating high-quality machine learning models for financial services using Amazon SageMaker Autopilot
- How Zopa enhanced their fraud detection application using Amazon SageMaker Clarify
- Detecting fraud in heterogeneous networks using Amazon SageMaker and Deep Graph Library
Please contact AWS if you need help developing a full-scale AML solution (covering client screening and identity, transaction monitoring, extended customer risk profile and reporting of suspicious transactions) on AWS.
About the Author
 Yomi Abatan is a Sr. Solution Architect based in London, United Kingdom. He works with financial services organisations, architecting, designing and implementing various large-scale IT solutions. He, currently helps established financial services AWS customers embark on Digital transformations using AWS cloud as an accelerator. Before joining AWS he worked in various architecture roles with several tier-one investment banks.
Yomi Abatan is a Sr. Solution Architect based in London, United Kingdom. He works with financial services organisations, architecting, designing and implementing various large-scale IT solutions. He, currently helps established financial services AWS customers embark on Digital transformations using AWS cloud as an accelerator. Before joining AWS he worked in various architecture roles with several tier-one investment banks.