AWS Big Data Blog

Test data quality at scale with Deequ
In this blog post, we introduce Deequ, an open source tool developed and used at Amazon. Deequ allows you to calculate data quality metrics on your dataset, define and verify data quality constraints, and be informed about changes in the data distribution. Instead of implementing checks and verification algorithms on your own, you can focus on describing how your data should look.

Optimize Amazon EMR costs with idle checks and automatic resource termination using advanced Amazon CloudWatch metrics and AWS Lambda
Many customers use Amazon EMR to run big data workloads, such as Apache Spark and Apache Hive queries, in their development environment. Data analysts and data scientists frequently use these types of clusters, known as analytics EMR clusters. Users often forget to terminate the clusters after their work is done. This leads to idle running […]

Query your Amazon Redshift cluster with the new Query Editor
Data warehousing is a critical component for analyzing and extracting actionable insights from your data. Amazon Redshift is a fast, scalable data warehouse that makes it cost-effective to analyze all of your data across your data warehouse and data lake. The Amazon Redshift console recently launched the Query Editor. The Query Editor is an in-browser […]

Build and automate a serverless data lake using an AWS Glue trigger for the Data Catalog and ETL jobs
September 2022: This post was reviewed and updated with latest screenshots and instructions. Today, data is flowing from everywhere, whether it is unstructured data from resources like IoT sensors, application logs, and clickstreams, or structured data from transaction applications, relational databases, and spreadsheets. Data has become a crucial part of every business. This has resulted […]

Amazon Data Firehose custom prefixes for Amazon S3 objects
July 2024: This post was reviewed and updated for accuracy. In February 2019, Amazon Web Services (AWS) announced a new feature in Amazon Data Firehose called Custom Prefixes for Amazon S3 Objects. It lets customers specify a custom expression for the Amazon S3 prefix where data records are delivered. Previously, Firehose allowed only specifying a […]

Build and run streaming applications with Apache Flink and Amazon Kinesis Data Analytics for Java Applications
In this post, we discuss how you can use Apache Flink and Amazon Kinesis Data Analytics for Java Applications to address these challenges. We explore how to build a reliable, scalable, and highly available streaming architecture based on managed services that substantially reduce the operational overhead compared to a self-managed environment.
Improve clinical trial outcomes by using AWS technologies
We are living in a golden age of innovation, where personalized medicine is making it possible to cure diseases that we never thought curable. Digital medicine is helping people with diseases get healthier, and we are constantly discovering how to use the body’s immune system to target and eradicate cancer cells. According to a report […]

Federate Amazon Redshift access with Okta as an identity provider
December 2022: This post was reviewed and updated for accuracy. Managing database users and access can be a daunting and error-prone task. In the past, database administrators had to determine which groups a user belongs to and which objects a user/group is authorized to use. These lists were maintained within the database and could easily […]

Grant fine-grained access to the Amazon Redshift Management Console
As a fully managed service, Amazon Redshift is designed to be easy to set up and use. In this blog post, we demonstrate how to grant access to users in an operations group to perform only specific actions in the Amazon Redshift Management Console. If you implement a custom IAM policy, you can set it […]
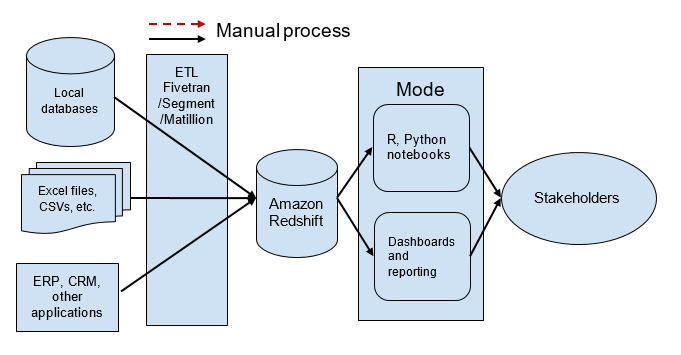
Build a modern analytics stack optimized for sharing and collaborating with Mode and Amazon Redshift
Leading technology companies, such as Netflix and Airbnb, are building on AWS to solve problems on the edge of the data ecosystem. While these companies show us what data and analytics make possible, the complexity and scale of their problems aren’t typical. Most of our challenges aren’t figuring out how to process billions of records […]