AWS Big Data Blog
Amazon QuickSight announces ML Insights in preview
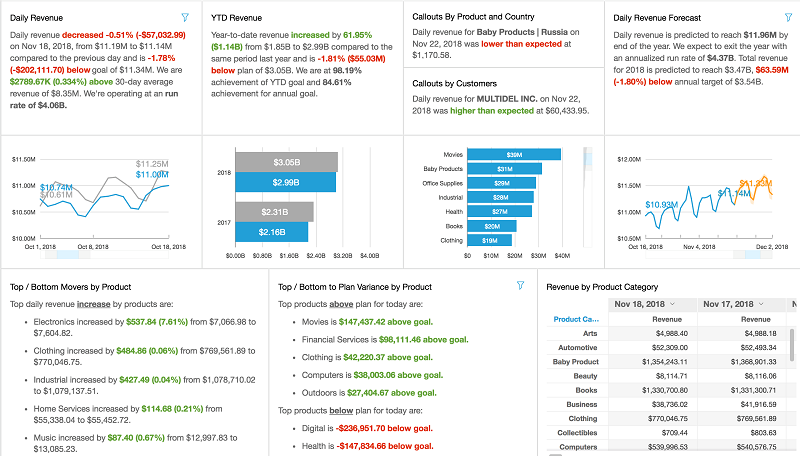
Amazon QuickSight is a fast, cloud-powered BI service that makes it easy for everyone in an organization to get business insights from their data through rich, interactive dashboards. With pay-per-session pricing and embedded dashboard, we made BI even more cost-effective and accessible to everyone. However, as the volume of data that customers generate continues to […]
Scale your Amazon Redshift clusters up and down in minutes to get the performance you need, when you need it
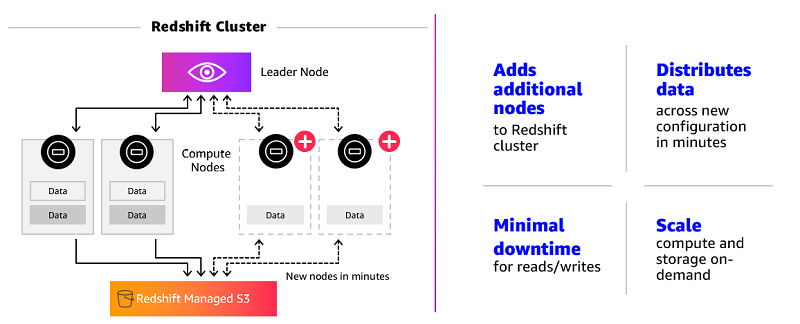
Amazon Redshift is the cloud data warehouse of choice for organizations of all sizes—from fast-growing technology companies such as Turo and Yelp to Fortune 500 companies such as 21st Century Fox and Johnson & Johnson. With quickly expanding use cases, data sizes, and analyst populations, these customers have a critical need for scalable data warehouses. […]

Scale Amazon Kinesis Data Streams with AWS Application Auto Scaling
Recently, AWS launched a new feature of AWS Application Auto Scaling that let you define scaling policies that automatically add and remove shards to an Amazon Kinesis Data Stream. For more detailed information about this feature, see the Application Auto Scaling GitHub repository. As your streaming information increases, you require a scaling solution to accommodate […]

Your guide to Amazon Kinesis sessions, chalk talks, and workshops at AWS re:Invent 2018
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. AWS re:Invent 2018 is almost here! This post includes a list of Amazon Kinesis sessions, chalk talks, and workshops at AWS re:Invent 2018. You can choose the link next to each session description for the […]
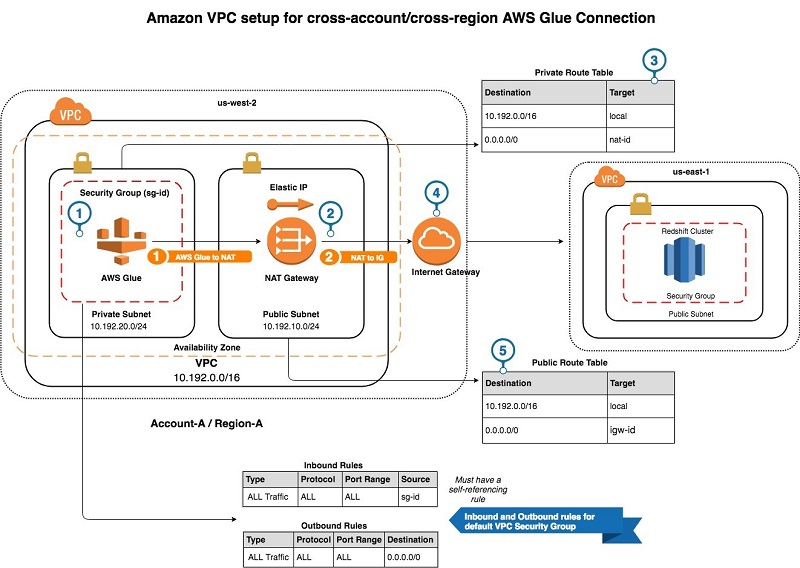
Create cross-account and cross-region AWS Glue connections
In this blog post, we describe how to configure the networking routes and interfaces to give AWS Glue access to a data store in an AWS Region different from the one with your AWS Glue resources. In our example, we connect AWS Glue, located in Region A, to an Amazon Redshift data warehouse located in Region B.
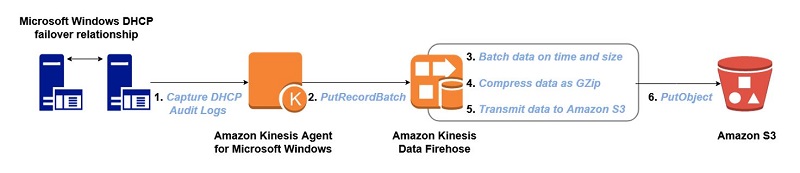
Turn Windows DHCP Server logs into actionable metrics using Amazon Kinesis Agent for Windows
Understanding Windows system and service health on a global scale is challenging. You capture server log data, and then analyze and manipulate the data in real time to create actionable telemetry insights. Amazon Kinesis Agent for Microsoft Windows makes it efficient to ingest Windows server log data into your AWS ecosystem for analysis. This blog […]

AWS Big Data and Analytics Sessions at Re:Invent 2018
re:Invent 2018 is around the corner! This year, data and analytics tracks are bigger than ever. This blog post highlights the data and analytics sessions at re:Invent 2018. If you’re attending this year, you want to check out the sessions, workshops, chalk talks, and builder sessions that we have at the conference. As in previous […]
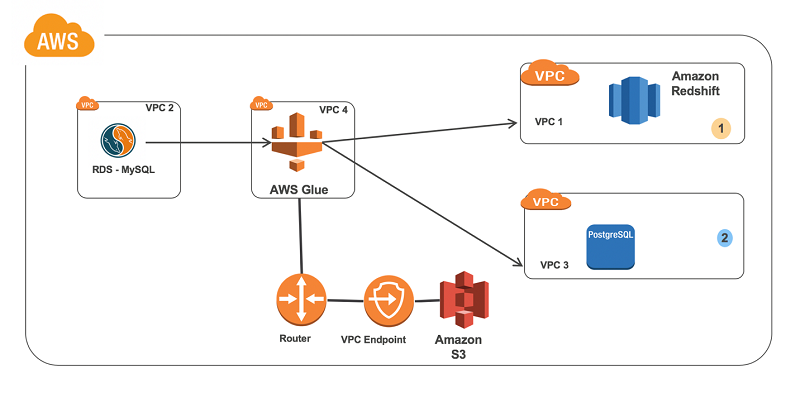
Connect to and run ETL jobs across multiple VPCs using a dedicated AWS Glue VPC
In this blog post, we’ll go through the steps needed to build an ETL pipeline that consumes from one source in one VPC and outputs it to another source in a different VPC. We’ll set up in multiple VPCs to reproduce a situation where your database instances are in multiple VPCs for isolation related to security, audit, or other purposes.
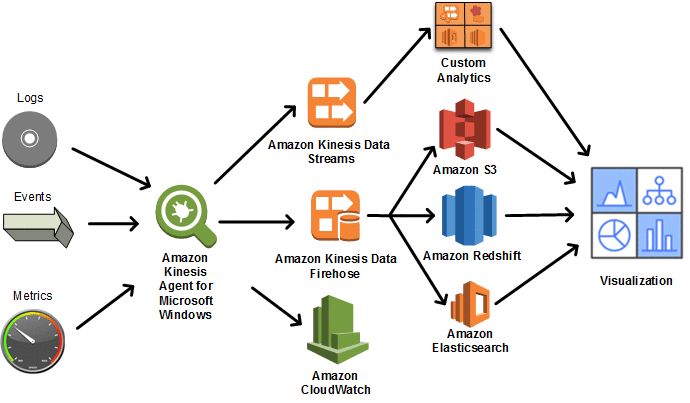
Collect, parse, transform, and stream Windows events, logs, and metrics using Amazon Kinesis Agent for Microsoft Windows
A complete data pipeline that includes Amazon Kinesis Agent for Microsoft Windows (KA4W) can help you analyze and monitor the performance, security, and availability of Windows-based services. You can build near-real-time dashboards and alarms for your Windows services. You can also use visualization and business intelligence tools such as Amazon Athena, Kibana, Amazon QuickSight, and […]

Chasing earthquakes: How to prepare an unstructured dataset for visualization via ETL processing with Amazon Redshift
As organizations expand analytics practices and hire data scientists and other specialized roles, big data pipelines are growing increasingly complex. Sophisticated models are being built using the troves of data being collected every second. The bottleneck today is often not the know-how of analytical techniques. Rather, it’s the difficulty of building and maintaining ETL (extract, transform, and load) jobs using tools that might be unsuitable for the cloud. In this post, I demonstrate a solution to this challenge.