AWS Big Data Blog

Create real-time clickstream sessions and run analytics with Amazon Kinesis Data Analytics, AWS Glue, and Amazon Athena
April 2024: The content of this post is no longer relevant and deprecated. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Clickstream events are small pieces of data that are generated continuously with high speed […]
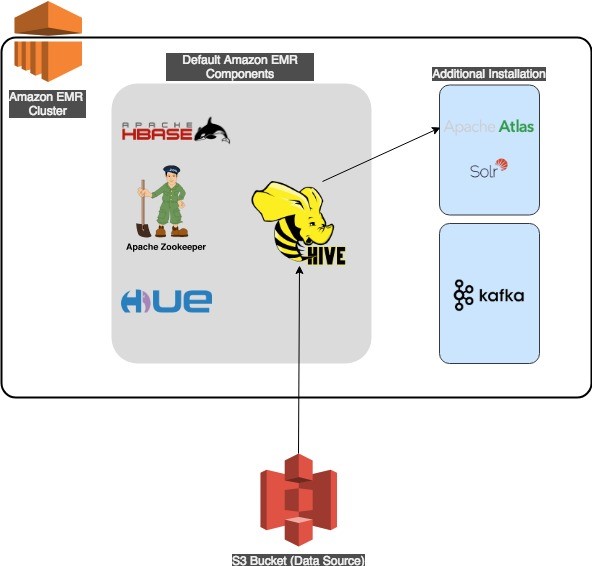
Metadata classification, lineage, and discovery using Apache Atlas on Amazon EMR
This blog post was last reviewed and updated April, 2022. The code repositories used in this blog have been reviewed and updated to fix the solution With the ever-evolving and growing role of data in today’s world, data governance is an essential aspect of effective data management. Many organizations use a data lake as a […]
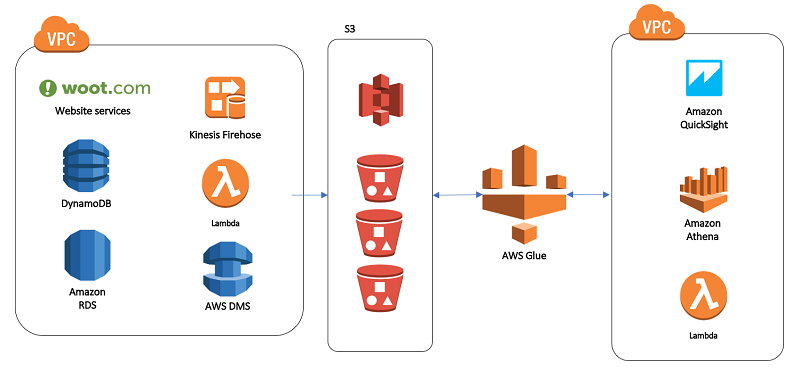
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]

Analyze and visualize nested JSON data with Amazon Athena and Amazon QuickSight
April 2024: This post was reviewed for accuracy. Although structured data remains the backbone for many data platforms, increasingly unstructured or semi-structured data is used to enrich existing information or create new insights. Amazon Athena enables you to analyze a wide variety of data. This includes tabular data in CSV or Apache Parquet files, data […]

Run Amazon payments analytics with 750 TB of data on Amazon Redshift
The Amazon Payments Data Engineering team is responsible for data ingestion, transformation, and storage of a growing dataset of more than 750 TB. The team makes these services available to more than 300 business customers around the globe. These customers include managers from the product, marketing, and programs domains; as well as data scientists, business analysts, […]

Analyze your Amazon CloudFront access logs at scale
This blog post focuses on two measures to restructure Amazon CloudFront access logs for optimization: partitioning and conversion to columnar formats. For more details on performance tuning read the blog post about the top 10 performance tuning tips for Amazon Athena.
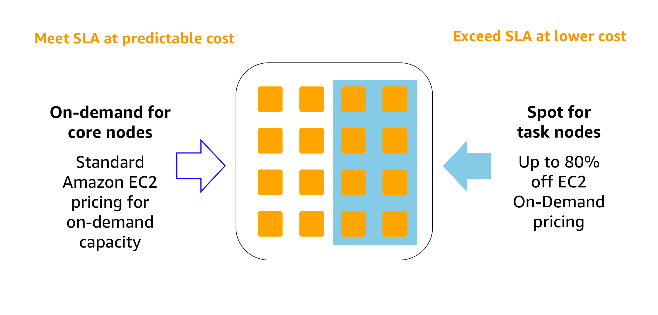
Reduce costs by migrating Apache Spark and Hadoop to Amazon EMR
Apache Spark and Hadoop are popular frameworks to process data for analytics, often at a fraction of the cost of legacy approaches, yet at scale they may still become expensive propositions. This blog post discusses ways to reduce your total costs of ownership, while also improving staff productivity at the same time. This can be […]
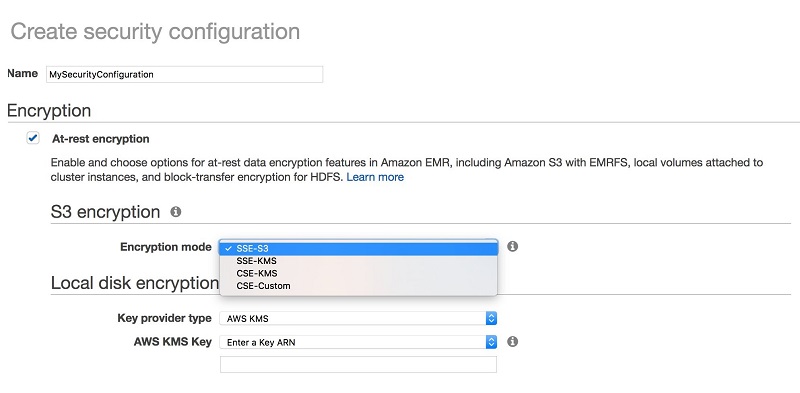
Best Practices for Securing Amazon EMR
This post walks you through some of the principles of Amazon EMR security. It also describes features that you can use in Amazon EMR to help you meet the security and compliance objectives for your business. We cover some common security best practices that we see used. We also show some sample configurations to get you started.
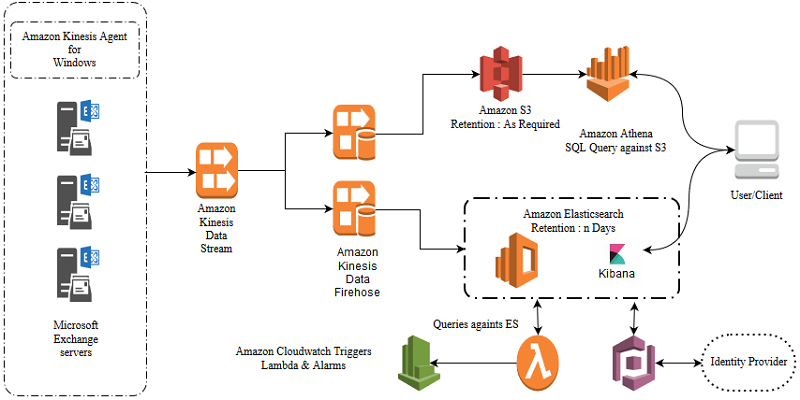
Manage centralized Microsoft Exchange Server logs using Amazon Kinesis Agent for Windows
This blog post discusses an efficient architecture to stream, analyze, and store Microsoft Exchange Server logs. For frequent queries and operational analytics, we use Amazon Elasticsearch Service (Amazon ES) and Kibana for real-time visualization.

Embed interactive dashboards in your application with Amazon QuickSight
Starting today, you can embed Amazon QuickSight dashboards in your applications. This means you can now quickly and efficiently enhance your applications with advanced interactive data visualizations and analytics capabilities without any custom development.