AWS Big Data Blog

Grant fine-grained access to the Amazon Redshift Management Console
As a fully managed service, Amazon Redshift is designed to be easy to set up and use. In this blog post, we demonstrate how to grant access to users in an operations group to perform only specific actions in the Amazon Redshift Management Console. If you implement a custom IAM policy, you can set it […]
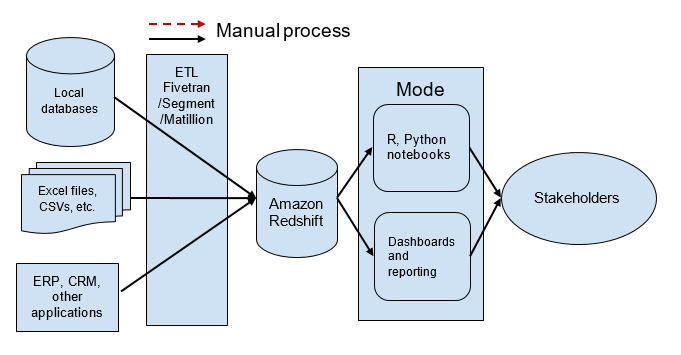
Build a modern analytics stack optimized for sharing and collaborating with Mode and Amazon Redshift
Leading technology companies, such as Netflix and Airbnb, are building on AWS to solve problems on the edge of the data ecosystem. While these companies show us what data and analytics make possible, the complexity and scale of their problems aren’t typical. Most of our challenges aren’t figuring out how to process billions of records […]

Amazon QuickSight Announces General Availability of ML Insights
At re:Invent 2018, we announced the preview of ML Insights, a set of out-of-the-box machine learning and natural language features that provide Amazon QuickSight users with business insights beyond visualization. Today, we are announcing the general availability of ML Insights. As the volume of data that customers generate continues to grow every day, it’s becoming […]
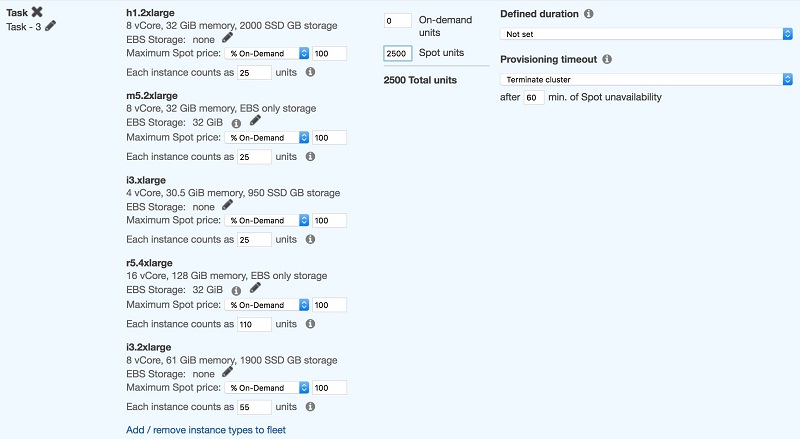
Best practices for running Apache Spark applications using Amazon EC2 Spot Instances with Amazon EMR
In this blog post, we are going to focus on cost-optimizing and efficiently running Spark applications on Amazon EMR by using Spot Instances. We recommend several best practices to increase the fault tolerance of your Spark applications and use Spot Instances. These work without compromising availability or having a large impact on performance or the length of your jobs.

How to enable cross-account Amazon Redshift COPY and Redshift Spectrum query for AWS KMS–encrypted data in Amazon S3
This post shows a step-by-step walkthrough of how to set up a cross-account Amazon Redshift COPY and Spectrum query using a sample dataset in Amazon S3. The sample dataset is encrypted at rest using AWS KMS-managed keys (SSE-KMS). About AWS Key Management Service (AWS KMS) With AWS Key Management Service (AWS KMS), you can have […]

Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy. The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance […]

Spark enhancements for elasticity and resiliency on Amazon EMR
This blog post provides an overview of the issues with how open-source Spark handles node loss and the improvements in Amazon EMR to address the issues.

Run a petabyte scale cluster in Amazon OpenSearch Service
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When you use Amazon OpenSearch Service for log data, you’re drinking from what usually becomes a forceful firehose. As your OpenSearch and Kibana knowledge deepens, you find many compelling uses of your […]

Visualize over 200 years of global climate data using Amazon Athena and Amazon QuickSight
Climate Change continues to have a profound effect on our quality of life. As a result, the investigation into sustainability is growing. Researchers in both the public and private sector are planning for the future by studying recorded climate history and using climate forecast models. To help explain these concepts, this post introduces the Global […]
Increase availability for Amazon OpenSearch Service by deploying in three Availability Zones
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Today, Amazon OpenSearch Service announced support for deploying your domains across three Availability Zones (AZ). This feature is available in all AWS Regions that support at least three Availability Zones. With this new feature, you can spread out your master and data […]