AWS Big Data Blog
Implementing Authorization and Auditing using Apache Ranger on Amazon EMR
Updated 3/30/2022: Amazon EMR has announced official support of Apache Ranger (link). Open-source plugin support will not be maintained moving forward and compatibility with latest versions will not be tested. We recommend customers to move to the Amazon EMR support for Apache Ranger. Ranger Presto plugin support on EMR has been deprecated. Updated 12/03/2020: Support for […]

Analyzing Data in S3 using Amazon Athena
April 2024: This post was reviewed for accuracy. Amazon Athena is an interactive query service that makes it easy to analyze data directly from Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to set up or manage and you can start analyzing your data immediately. You don’t even need to […]

Introducing the Data Lake Solution on AWS
NOTE: The solution in this post is in the process of being updated. For the most current information, please visit the What is a data lake? page. This blog post has been translated into Japanese. Many of our customers choose to build their data lake on AWS. They find the flexible, pay-as-you-go, cloud model is […]

Low-Latency Access on Trillions of Records: FINRA’s Architecture Using Apache HBase on Amazon EMR with Amazon S3
John Hitchingham is Director of Performance Engineering at FINRA The Financial Industry Regulatory Authority (FINRA) is a private sector regulator responsible for analyzing 99% of the equities and 65% of the option activity in the US. In order to look for fraud, market manipulation, insider trading, and abuse, FINRA’s technology group has developed a robust […]
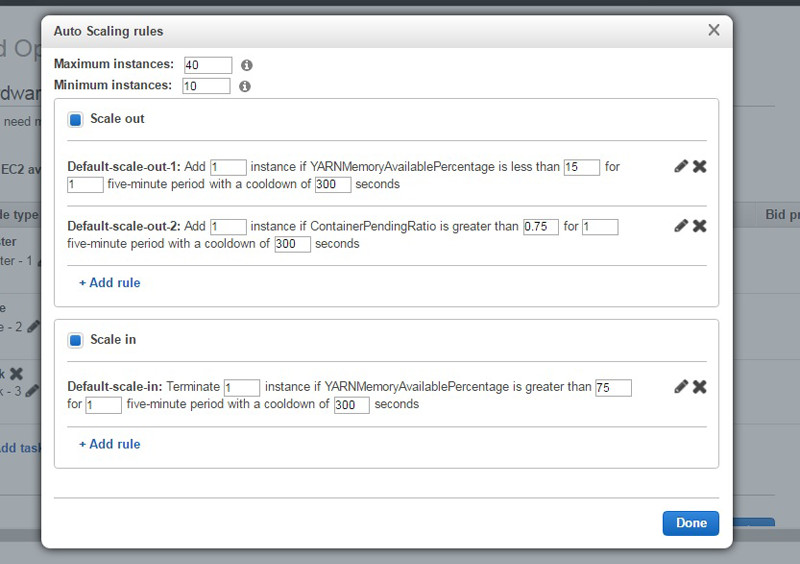
Dynamically Scale Applications on Amazon EMR with Auto Scaling
Jonathan Fritz is a Senior Product Manager for Amazon EMR Customers running Apache Spark, Presto, and the Apache Hadoop ecosystem take advantage of Amazon EMR’s elasticity to save costs by terminating clusters after workflows are complete and resizing clusters with low-cost Amazon EC2 Spot Instances. For instance, customers can create clusters for daily ETL or machine learning […]

Build a Community of Analysts with Amazon QuickSight
Imagine you’ve just landed your dream job. You’ve always liked tackling the hardest problems and you’ve got one now: You’ll work for a chain of coffee shops that’s struggling against fierce competition, tight budgets, and low morale. But there’s a new management team in place. As head of business intelligence (BI), you think you can […]

Scale Your Amazon Kinesis Stream Capacity with UpdateShardCount
Allan MacInnis is a Kinesis Solution Architect for Amazon Web Services Starting today, you can easily scale your Amazon Kinesis streams to respond in real time to changes in your streaming data needs. Customers use Amazon Kinesis to capture, store, and analyze terabytes of data per hour from clickstreams, financial transactions, social media feeds, and […]

re:Invent 2016: AWS Big Data & Machine Learning Sessions
Roy Ben-Alta is Sr. Business Development Manager at AWS – Big Data & Machine Learning Updated December 9, 2016 with links to session videos. We can’t believe that there are just a couple of weeks left before re:Invent 2016. If you are attending this year, you will want to check out our Big Data sessions! […]
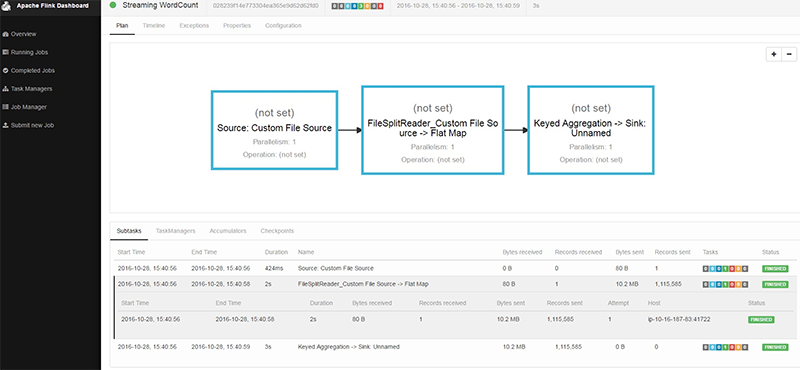
Use Apache Flink on Amazon EMR
Today we are making it even easier to run Flink on AWS as it is now natively supported in Amazon EMR 5.1.0. EMR supports running Flink-on-YARN so you can create either a long-running cluster that accepts multiple jobs or a short-running Flink session in a transient cluster that helps reduce your costs by only charging you for the time that you use.

Month in Review: October 2016
Another month of big data solutions on the Big Data Blog. Take a look at our summaries below and learn, comment, and share. Thanks for reading! Building Event-Driven Batch Analytics on AWS Modern businesses typically collect data from internal and external sources at various frequencies throughout the day. In this post, you learn an elastic […]