AWS Big Data Blog
Tag: Amazon Redshift

Accelerate Amazon Redshift secure data use with Satori – Part 1
This post is co-written by Lisa Levy, Content Specialist at Satori. Data democratization enables users to discover and gain access to data faster, improving informed data-driven decisions and using data to generate business impact. It also increases collaboration across teams and organizations, breaking down data silos and enabling cross-functional teams to work together more effectively. […]

Stored procedure enhancements in Amazon Redshift
In this post, we discuss the enhancements to Amazon Redshift stored procedures for non-atomic transaction mode. This mode provides enhanced transaction controls that enable you to automatically commit the statements inside the stored procedure.

Build an ETL process for Amazon Redshift using Amazon S3 Event Notifications and AWS Step Functions
In this post we discuss how we can build and orchestrate in a few steps an ETL process for Amazon Redshift using Amazon S3 Event Notifications for automatic verification of source data upon arrival and notification in specific cases. And we show how to use AWS Step Functions for the orchestration of the data pipeline. It can be considered as a starting point for teams within organizations willing to create and build an event driven data pipeline from data source to data warehouse that will help in tracking each phase and in responding to failures quickly. Alternatively, you can also use Amazon Redshift auto-copy from Amazon S3 to simplify data loading from Amazon S3 into Amazon Redshift.

Dimensional modeling in Amazon Redshift
Amazon Redshift is a fully managed and petabyte-scale cloud data warehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model. Amazon Redshift […]

Centralize near-real-time governance through alerts on Amazon Redshift data warehouses for sensitive queries
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. In many organizations, one or multiple Amazon Redshift data warehouses […]

How SafetyCulture scales unpredictable dbt Cloud workloads in a cost-effective manner with Amazon Redshift
This post is co-written by Anish Moorjani, Data Engineer at SafetyCulture. SafetyCulture is a global technology company that puts the power of continuous improvement into everyone’s hands. Its operations platform unlocks the power of observation at scale, giving leaders visibility and workers a voice in driving quality, efficiency, and safety improvements. Amazon Redshift is a […]

Code conversion from Greenplum to Amazon Redshift: Handling arrays, dates, and regular expressions
Amazon Redshift is a fully managed service for data lakes, data analytics, and data warehouses for startups, medium enterprises, and large enterprises. Amazon Redshift is used by tens of thousands of businesses around the globe for modernizing their data analytics platform. Greenplum is an open-source, massively parallel database used for analytics, mostly for on-premises infrastructure. […]

How Etleap and Amazon Redshift Serverless optimize costs for ETL
Amazon Redshift Serverless lets you avoid managing infrastructure while only paying for what you use. Etleap provides data integration software that is natively built on AWS. It’s an AWS Advanced Technology Partner with the AWS Data & Analytics Competency and Amazon Redshift Service Ready designation. In this post, we share how you can minimize the […]

Automate data archival for Amazon Redshift time series tables
Amazon Redshift is a fast, petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all of your data using standard SQL. Tens of thousands of customers today rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud data warehouse. You can […]
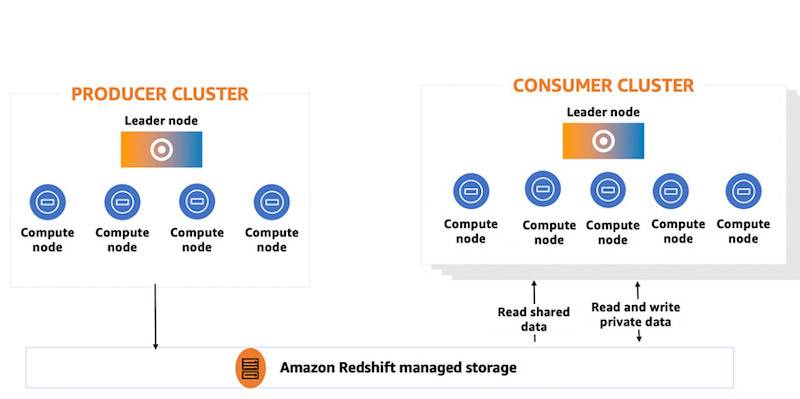
From centralized architecture to decentralized architecture: How data sharing fine-tunes Amazon Redshift workloads
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. With the significant growth of data for big […]