AWS Big Data Blog
Tag: Amazon Redshift
Manage data transformations with dbt in Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. Amazon Redshift enables you to use your data to acquire new insights for your business and customers while keeping costs low. Together with price-performance, […]

Federated access to Amazon Redshift clusters in AWS China Regions with Active Directory Federation Services
Many customers already manage user identities through identity providers (IdPs) for single sign-on access. With an IdP such as Active Directory Federation Services (AD FS), you can set up federated access to Amazon Redshift clusters as a mechanism to control permissions for the database objects by business groups. This provides a seamless user experience, and centralizes the governance […]

Query and visualize Amazon Redshift operational metrics using the Amazon Redshift plugin for Grafana
Grafana is a rich interactive open-source tool by Grafana Labs for visualizing data across one or many data sources. It’s used in a variety of modern monitoring stacks, allowing you to have a common technical base and apply common monitoring practices across different systems. Amazon Managed Grafana is a fully managed, scalable, and secure Grafana-as-a-service […]

Accelerate self-service analytics with Amazon Redshift Query Editor V2
August 2023: This post was reviewed and updated with new features. Amazon Redshift is a fast, fully managed cloud data warehouse. Tens of thousands of customers use Amazon Redshift as their analytics platform. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift data warehouses. Amazon […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]

Synchronize and control your Amazon Redshift clusters maintenance windows
Amazon Redshift is a data warehouse that can expand to exabyte-scale. Today, tens of thousands of AWS customers (including NTT DOCOMO, Finra, and Johnson & Johnson) use Amazon Redshift to run mission-critical business intelligence dashboards, analyze real-time streaming data, and run predictive analytics jobs. Amazon Redshift powers analytical workloads for Fortune 500 companies, startups, and […]

Federating single sign-on access to your Amazon Redshift cluster with PingIdentity
Single sign-on (SSO) enables users to have a seamless user experience while accessing various applications in the organization. If you’re responsible for setting up security and database access privileges for users and tasked with enabling SSO for Amazon Redshift, you can set up SSO authentication using ADFS, PingIdentity, Okta, Azure AD or other SAML browser […]

Best practices using AWS SCT and AWS Snowball to migrate from Teradata to Amazon Redshift
This is a guest post from ZS. In their own words, “ZS is a professional services firm that works closely with companies to help develop and deliver products and solutions that drive customer value and company results. ZS engagements involve a blend of technology, consulting, analytics, and operations, and are targeted toward improving the commercial […]
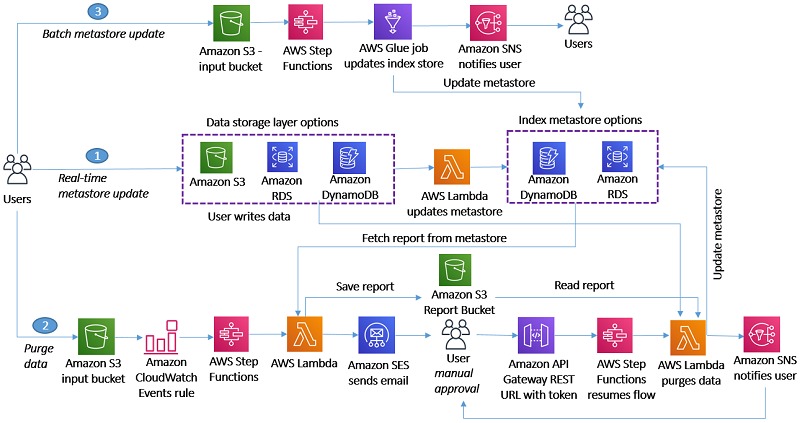
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]
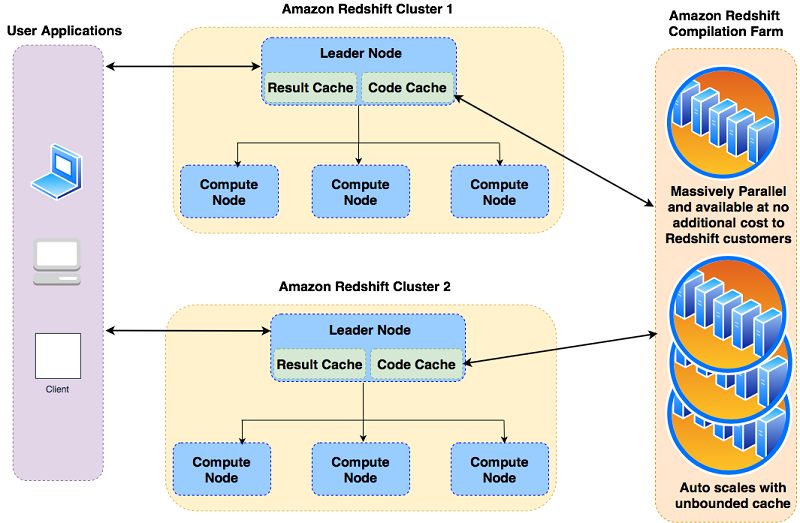
Fast and predictable performance with serverless compilation using Amazon Redshift
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Customers tell us that they want extremely fast query response times so they can make equally fast decisions. This post presents the recently launched, […]