AWS Big Data Blog
Federated access to Amazon Redshift clusters in AWS China Regions with Active Directory Federation Services
Many customers already manage user identities through identity providers (IdPs) for single sign-on access. With an IdP such as Active Directory Federation Services (AD FS), you can set up federated access to Amazon Redshift clusters as a mechanism to control permissions for the database objects by business groups. This provides a seamless user experience, and centralizes the governance of authentication and permissions for end-users. For more information, refer to the blog post series “Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS)” (part 1, part 2).
Due to the differences in the implementation of Amazon Web Services in China, customers have to adjust the configurations accordingly. For example, AWS China Regions (Beijing and Ningxia) are in a separate AWS partition, therefore all the Amazon Resource Names (ARNs) include the suffix -cn. AWS China Regions are also hosted at a different domain: www.amazonaws.cn.
This post introduces a step-by-step procedure to set up federated access to Amazon Redshift in AWS China Regions. It pinpoints the key differences you should pay attention to and provides a troubleshooting guide for common errors.
Solution overview
The following diagram illustrates the process of Security Assertion Markup Language 2.0 (SAML)-based federation access to Amazon Redshift in AWS China Regions. The workflow includes the following major steps:
- The SQL client provides a user name and password to AD FS.
- AD FS authenticates the credential and returns a SAML response if successful.
- The SQL client makes an API call to AWS Security Token Service (AWS STS) to assume a preferred role with SAML.
- AWS STS authenticates the SAML response based on the mutual trust and returns temporary credentials if successful.
- The SQL client communicates with Amazon Redshift to get back a database user with temporary credentials, then uses it to join database groups and connect to the specified database.

We organize the walkthrough in the following high-level steps:
- Configure an AD FS relying party trust for AWS China Regions and define basic claim rules.
- Provision an AWS Identity and Access Management (IAM) identity provider and roles.
- Complete the remaining relying party trust’s claim rules based on the IAM resources.
- Connect to Amazon Redshift with federated access via a JDBC-based SQL client.
Prerequisites
This post assumes that you have the following prerequisites:
- Windows Server 2016
- The ability to create users and groups in AD
- The ability to configure a relying party trust and define claim rules in AD FS
- An AWS account
- Sufficient permissions to provision IAM identity providers, roles, Amazon Virtual Private Cloud (Amazon VPC) related resources, and an Amazon Redshift cluster via AWS Cloud Development Kit (AWS CDK)
Configure an AD FS relying party trust and define claim rules
A relying party trust allows AWS and AD FS to communicate with each other. It is possible to configure two relying party trusts for both AWS China Regions and AWS Regions in the same AD FS at the same time. For AWS China Regions, we need to use a different SAML metadata document at https://signin.amazonaws.cn/static/saml-metadata.xml. The relying party’s identifier for AWS China Regions is urn:amazon:webservices:cn-north-1, whereas that for AWS Global Regions is urn:amazon:webservices. Note down this identifier to use later in this post.

Add AD groups and users
With SAML-based federation, end-users assume an IAM role and use it to join multiple database (DB) groups. The permissions on such roles and DB groups can be effectively managed by AD groups. We use different prefixes in AD group names to distinguish them, which help map to roles and DB group claim rules. It’s important to distinguish correctly the two types of AD groups because they’re mapped to different AWS resources.
We continue our walkthrough with an example. Suppose in business there are two roles: data scientist and data engineer, and two DB groups: oncology and pharmacy. Data scientists can join both groups, and data engineers can only join the pharmacy group. On the AD side, we define one AD group for each role and group. On the AWS side, we define one IAM role for each role and one Amazon Redshift DB group for each DB group. Suppose Clement is a data scientist and Jimmy is a data engineer, and both are already managed by AD. The following diagram illustrates this relationship.

You may create the AD groups and users with either the AWS Command Line Interface (AWS CLI) or the AWS Management Console. We provide sample commands in the README file in the GitHub repo.
Follow substeps a to o of Step 2 in Setting up JDBC or ODBC Single Sign-on authentication with AD FS to set up the relying party with the correct SAML metadata document for AWS China Regions and define the first three claim rules (NameId, RoleSessionName, and Get AD Groups). We resume after the IAM identity provider and roles are provisioned.
Provision an IAM identity provider and roles
You establish the trust for AD with AWS by provisioning an IAM identity provider. The IAM identity provider and assumed roles should be in one AWS account, otherwise you get the following error message during federated access: “Principal exists outside the account of the Role being assumed.” Follow these steps to provision the resources:
- Download the metadata file at
https://yourcompany.com/FederationMetadata/2007-06/FederationMetadata.xmlfrom your AD FS server. - Save it locally at
/tmp/FederationMetadata.xml. - Check out the AWS CDK code on GitHub.
- Use AWS CDK to deploy the stack named
redshift-cn:
The AWS CDK version should be 2.0 or newer. For testing purposes, you may use the AdministratorAccess managed policy for the deployment. For production usage, use a profile with least privilege.
The following table summarizes the resources that the AWS CDK package provisions.
| Service | Resource | Count | Notes |
|---|---|---|---|
| Amazon VPC | VPC | 1 | . |
| Subnet | 2 | . | |
| Internet gateway | 1 | . | |
| Route table | 1 | . | |
| Security group | 1 | . | |
| IAM | SAML Identity provider | 1 | . |
| Role | 3 | 1 service role for cluster
2 federated roles |
|
| Amazon Redshift | Cluster | 1 | 1 node, dc2.large |
| AWS Secrets Manager | Secret | 1 | . |
In this example, the Publicly Accessible setting of the Amazon Redshift cluster is set to Enabled for simplicity. However, in a production environment, you should disable this setting and place the cluster inside a private subnet group. Refer to How can I access a private Amazon Redshift cluster from my local machine for more information.
Configure a security group
Add an inbound rule for your IP address to allow connection to the Amazon Redshift cluster.
- Find the security group named
RC Default Security Group. - Obtain the public IP address of your machine.
- Add an inbound rule for this IP address and the default port for Amazon Redshift 5439.
Complete the remaining claim rules
After you provision the IAM identity provider and roles, add a claim rule to define SAML roles. We add a customer claim rule with the name Roles. It finds AD groups with the prefix role_ and replaces it with a combined ARN string. Pay attention to the ARNs of the resources where the partition is aws-cn. Replace AWS_ACCOUNT with your AWS account ID. The following table demonstrates how the selected AD groups are transformed to IAM role ARNs.
| Selected AD Group | Transformed IAM Role ARN |
|---|---|
role_data_scientist |
arn:aws-cn:iam::AWS_ACCOUNT:role/rc_data_scientist |
role_data_engineer |
arn:aws-cn:iam::AWS_ACCOUNT:role/rc_data_engineer |

To add the claim rule, open the AD FS management console in your Windows Server and complete the following steps:
- Choose Relying Party Trusts, then choose the relying party for AWS China.
- Choose Edit Claim Issuance Policy, then choose Add Role.
- On the Claim rule template menu, choose Send Claims Using a Custom Rule.
- For Claim rule name, enter
Roles. - In the Custom rule section, enter the following:
The optional parameters of DbUser, AutoCreate, and DbGroups can be provided via either JDBC connection parameters or SAML attribute values. The benefit of user federation is to manage users in one place centrally. Therefore, the DbUser value should be automatically provided by the SAML attribute. The AutoCreate parameter should always be true, otherwise you have to create DB users beforehand. Finally, the DbGroups parameter could be provided by SAML attributes provided that such relationship is defined in AD.
To summarize, we recommend to provide at least DbUser and AutoCreate in SAML attributes, such that the end-user can save time by composing shorter connection strings. In our example, we provide all three parameters via SAML attributes.
- Add a customer claim rule named
DbUser. We use an email address as the value forDbUser:
You can also choose a Security Accounts Manager (SAM) account name, which is usually the user name of the email address. Using an email address plays an important role in IAM role policy setting. We revisit this issue later.
- Add the custom claim rule named
AutoCreate:
- Add a customer claim rule named
DbGroups. It finds all AD groups with the prefixgroup_and lists them as values for DbGroups:
You can test the preceding setting is correct by obtaining the SAML response via your browser.
- Visit
https://yourcompany.com/adfs/ls/IdpInitiatedSignOn.aspxon your Windows Server, log in with userclement, and check that the following SAML attributes exist. For userjimmy, the role isrc_data_engineerand the DB group contains onlygroup_pharmacy.
The preceding SAML attribute names are verified valid for AWS China Regions. The URLs end with amazon.com. It’s incorrect to change them to amazonaws.cn or amazon.cn.
Connect to Amazon Redshift with a SQL client
We use JDBC-based SQL Workbench/J (SQL client) to connect to the Amazon Redshift cluster. Amazon Redshift uses a DB group to collect DB users. The database privileges are managed collectively at group level. In this post, we don’t dive deep into privilege management. However, you need to create the preceding two DB groups.
- Connect to the provisioned cluster and create the groups. You can connect on the AWS Management Console via the query editor with temporary credentials, or via a SQL client with database user
adminand password. The password is stored in AWS Secrets Manager. You may need proper permissions for the above operations.
- Follow the instructions in Connect to your cluster by using SQL Workbench/J to download and install the SQL client and the Amazon Redshift JDBC driver.
We recommend the JDBC driver version 2.1 with AWS SDK driver-dependent libraries.
- Test that the cluster is connectable via its endpoint. The primary user name is
admin. You retrieve the secret value of the cluster’s password via Secrets Manager. SpecifyDSILogLevelandLogPathto collect driver logs and help diagnosis. The connection string looks like the following code. ReplaceCLUSTER_ENDPOINTwith the correct value and delete all line breakers. We split the line for readability.
For AWS China Regions, one extra JDBC driver option loginToRp must be set as you set up a separate relying party trust for the AWS China Regions. If an AD user is mapped to more than one AWS role, in the connection string, use preferred_role to specify the exact role to assume for federated access.
- Copy the role ARN directly and pay attention to the
aws-cnpartition.
If the user is mapped to only one role, this option can be omitted.
- Replace
CLUSTER_IDwith the correct cluster identifier. For the user name, enteryourcompany\clement; for the password, enter the credential from AD:
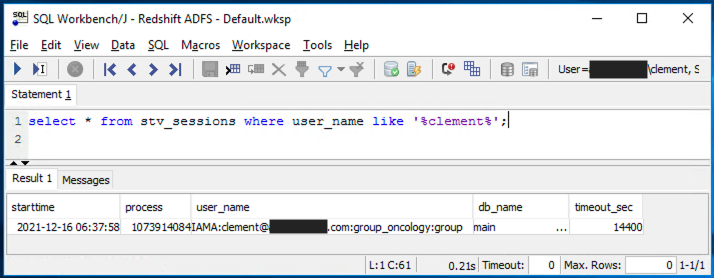
- When you’re connected, run the SQL statement as shown in the following screenshot.
The user prefixed with IAMA indicates that the user connected with federated access and was auto-created.
- As an optional step, in the connection string, you can set the
DbUser,AutoCreate, andDbGroupsparameters.
Parameters from the connection string are before those from SAML attributes. We recommend you set at least DbUser and AutoCreate via SAML attributes. If it’s difficult to manage DB groups in AD users or you want flexibility, specify DbGroups in the connection string. See the following code:
Use an email or SAM account name as DB user
The role policy follows the example policy for using GetClusterCredentials. It further allows redshift:DescribeClusters on the cluster because the role queries the cluster endpoint and port based on its identifier and Region. To make sure that the DB user is the same as the AD user, in this post, we use the following condition to check, where ROLE_ID is the unique identifier of the role:
The example policy uses the following condition:
The difference is apparent. The aws:userid contains the RoleSessionName, which is the email address. The SAM account name is the string before @ in the email address.
Redshift:DbUser is an authorization context variable (or IAM Policy variable) that can be used in IAM policy to limit the scope of which users are assumed by the principals. Because the connection string parameter is before the SAML attribute parameter, we summarize the possible cases as follows::
- If SAML attributes contain
DbUser:- If the condition value contains a domain suffix:
- If the
DbUserSAML attribute value is an email address,DbUsermust be in the connection string without the domain suffix. - If the
DbUserSAML attribute value is a SAM account name,DbUsercan be omitted in the connection string. Otherwise, the value must not contain a domain suffix.
- If the
- If the condition value doesn’t contain a domain suffix:
- If the
DbUserSAML attribute value is an email address,DbUsercan be omitted in the connection string. Otherwise, the value must contain a domain suffix. - If the
DbUserSAML attribute value is a SAM account name,DbUsermust be in the connection string with a domain suffix.
- If the
- If the condition value contains a domain suffix:
- If SAML attributes don’t contain
DbUser:- If the condition value contains a domain suffix,
DbUsermust be in the connection string without a domain suffix. - If the condition value doesn’t contain a domain suffix,
DbUsercan be omitted in the connection string, becauseRoleSessionNamevalue which is the email address acts asDbUser. Otherwise, the value must contain a domain suffix.
- If the condition value contains a domain suffix,

Troubleshooting
Federated access to Amazon Redshift is a non-trivial process. However, it consists of smaller steps that we can divide and conquer when problems occur. Refer to the access diagram in the solution overview. We can split the process into three phrases:
- Is SAML-based federation successful? Verify this by visiting the single sign-on page of AD FS and make sure you can sign in to the console with the federated role. Do you configure the relying party with the AWS China specific metadata document? Obtain the SAML response and check if the destination is https://signin.amazonaws.cn/saml. Are the SAML provider ARN and IAM role ARNs correct? Check if the role’s trust relationship contains the correct value for
SAML:aud. For other possible checkpoints, refer to Troubleshooting SAML 2.0 federation with AWS. - Are the role policies correct? If SAML-based federation is successful, check the role policies are correct. Compare yours with those provided by this post. Did you use
awswhereaws-cnshould be used? If the policy condition contains a domain suffix, is it the correct domain suffix? You can obtain the domain suffix in use if you get the error that the assumed role isn’t authorized to perform an action. - Is the SQL client connecting successfully? Is the cluster identifier correct? Make sure that your connection string contains the
loginToRpoption and points to the AWS China relying party. If multiple IAM roles are mapped, make surepreferred_roleis one of them with the correct role ARN. You can get the list of roles in the SAML response. Try to setssl_insecureto true temporarily for debugging. Check the previous subsection and make sure theDbUseris properly used or set according to theDbUserSAML attribute and condition value foraws:user. Turn on the driver logs and get debug hints there. Sometimes you may need to restart the SQL client to clear the cache and retry.
Security concerns
In a production environment, we suggest applying the following security settings, which aren’t used in this post.
For the Amazon Redshift cluster, complete the following:
- Disable the publicly accessible option and place the cluster inside a private or isolated subnet group
- Encrypt the cluster, for example, with a customer managed AWS Key Management Service (AWS KMS) key
- Enable enhanced VPC routing such that the network doesn’t leave your VPC
- Configure the cluster to require Secure Sockets Layer (SSL) and use one-way SSL authentication
For the IAM federated roles:
- Specify the exact DB groups for action
redshift:JoinGroup. If you want to use a wildcard, make sure it doesn’t permit unwanted DB groups. - Check
StringEqualsforaws:useragainst the role ID along with the Amazon Redshift DB user. This condition can be checked forGetClusterCredentials,CreateClusterUser, andJoinGroupactions. Refer to the sample code for detailed codes.
In Amazon Redshift, the DB group is used to manage privileges for a collection of DB users. A DB user joins some DB groups during a login session and is granted the privileges associated to the groups. As we discussed before, you can use either the SAML attribute value or the connection property to specify the DB groups. The Amazon Redshift driver prefers the value from the connection string to that from the SAML attribute. As a result, the end-user can override the DB groups in the connection string. Therefore, to confine the privileges a DB user can be granted, the IAM role policy must restrict which DB groups the DB user is allowed to join safely, otherwise there might be a security risk. The following policy snippet shows such a risk. Always follow the least privilege principle when defining permission policies.
Clean up
Run the following command to destroy the resources and stop incurring charges:
Remove the users and groups created in the AD FS. Finally, remove the relying party trust for AWS China Regions in your AD FS if you don’t need it anymore.
Conclusion
In this post, we walked you through how to connect to Amazon Redshift in China with federated access based on AD FS. AWS China Regions are in a partition different from other AWS Regions, so you must pay special attention during the configuration. In summary, you need to check AWS resources ARNs with the aws-cn partition, SAML-based federation with the AWS China specific metadata document, and an Amazon Redshift JDBC driver with extra connecting options. This post also discusses different usage scenarios for the redshift:Dbuser parameter and provides common troubleshooting suggestions.
For more information, refer to the Amazon Redshift Cluster Management Guide. Find the code used for this post in the following GitHub repository.
About the Authors
 Wenjun Yuan is a Cloud Infra Architect in AWS Professional Services based in Chengdu, China. He works with various customers, from startups to international enterprises, helping them build and implement solutions with state-of-the-art cloud technologies and achieve more in their cloud explorations. He enjoys reading poetry and traveling around the world in his spare time.
Wenjun Yuan is a Cloud Infra Architect in AWS Professional Services based in Chengdu, China. He works with various customers, from startups to international enterprises, helping them build and implement solutions with state-of-the-art cloud technologies and achieve more in their cloud explorations. He enjoys reading poetry and traveling around the world in his spare time.
{kind=link}
 Khoa Nguyen is a Big Data Architect in AWS Professional Services. He works with large enterprise customers and AWS partners to accelerate customers’ business outcomes by providing expertise in Big Data and AWS services.
Khoa Nguyen is a Big Data Architect in AWS Professional Services. He works with large enterprise customers and AWS partners to accelerate customers’ business outcomes by providing expertise in Big Data and AWS services.
 Yewei Li is a Data Architect in AWS Professional Services based in Shanghai, China. He works with various enterprise customers to design and build data warehousing and data lake solutions on AWS. In his spare time, he loves reading and doing sports.
Yewei Li is a Data Architect in AWS Professional Services based in Shanghai, China. He works with various enterprise customers to design and build data warehousing and data lake solutions on AWS. In his spare time, he loves reading and doing sports.