AWS Big Data Blog
Tag: Amazon Redshift
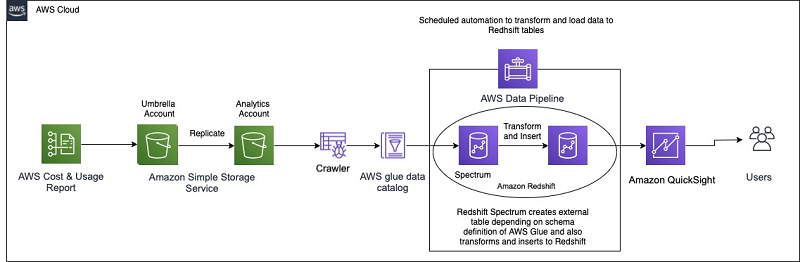
How Aruba Networks built a cost analysis solution using AWS Glue, Amazon Redshift, and Amazon QuickSight
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]

Top 10 performance tuning techniques for Amazon Redshift
Customers use Amazon Redshift for everything from accelerating existing database environments, to ingesting weblogs for big data analytics. Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that offers simple operations and high performance. Amazon Redshift provides an open standard JDBC/ODBC driver interface, which allows you to connect your existing business intelligence (BI) tools and reuse existing analytics queries. Amazon Redshift can run any type of data model, from a production transaction system third-normal-form model to star and snowflake schemas, data vault, or simple flat tables. This post takes you through the most common performance-related opportunities when adopting Amazon Redshift and gives you concrete guidance on how to optimize each one.
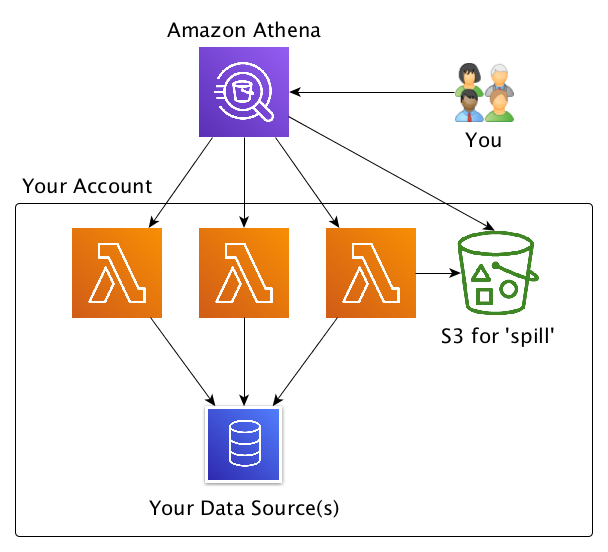
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.

Speed up data ingestion on Amazon Redshift with BryteFlow
This is a guest post by Pradnya Bhandary, Co-Founder and CEO at Bryte Systems. Data can be transformative for an organization. How and where you store your data for analysis and business intelligence is therefore an especially important decision that each organization needs to make. Should you choose an on-premises data warehouse solution or embrace […]
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]
Scale your cloud data warehouse and reduce costs with the new Amazon Redshift RA3 nodes with managed storage
One of our favorite things about working on Amazon Redshift, the cloud data warehouse service at AWS, is the inspiring stories from customers about how they’re using data to gain business insights. Many of our recent engagements have been with customers upgrading to the new instance type, Amazon Redshift RA3 with managed storage. In this […]

Optimize Python ETL by extending Pandas with AWS Data Wrangler
April 2024: This post was reviewed for accuracy. Developing extract, transform, and load (ETL) data pipelines is one of the most time-consuming steps to keep data lakes, data warehouses, and databases up to date and ready to provide business insights. You can categorize these pipelines into distributed and non-distributed, and the choice of one or […]

Stream Twitter data into Amazon Redshift using Amazon MSK and AWS Glue streaming ETL
This post demonstrates how customers, system integrator (SI) partners, and developers can use the serverless streaming ETL capabilities of AWS Glue with Amazon Managed Streaming for Kafka (Amazon MSK) to stream data to a data warehouse such as Amazon Redshift. We also show you how to view Twitter streaming data on Amazon QuickSight via Amazon Redshift.

Manage and control your cost with Amazon Redshift Concurrency Scaling and Spectrum
This post shares the simple steps you can take to use the new Amazon Redshift usage controls feature to monitor and control your usage and associated cost for Amazon Redshift Spectrum and Concurrency Scaling features. Redshift Spectrum enables you to power a lake house architecture to directly query and join data across your data warehouse and data lake, and Concurrency Scaling enables you to support thousands of concurrent users and queries with consistently fast query performance.

Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 2
In the first post of this series, Federating access to your Amazon Redshift cluster with Active Directory: Part 1, you set up Microsoft Active Directory Federation Services (AD FS) and Security Assertion Markup Language (SAML) based authentication and tested the SAML federation using a web browser. In Part 2, you learn to set up an […]