AWS Big Data Blog
Tag: Amazon S3

Build a Data Lake Foundation with AWS Glue and Amazon S3
A data lake is an increasingly popular way to store and analyze data that addresses the challenges of dealing with massive volumes of heterogeneous data. A data lake allows organizations to store all their data—structured and unstructured—in one centralized repository. Because data can be stored as-is, there is no need to convert it to a predefined schema. This post walks you through the process of using AWS Glue to crawl your data on Amazon S3 and build a metadata store that can be used with other AWS offerings.

Setting up Read Replica Clusters with HBase on Amazon S3
Many customers have taken advantage of the numerous benefits of running Apache HBase on Amazon S3 for data storage, including lower costs, data durability, and easier scalability. Customers such as FINRA have lowered their costs by 60% by moving to an HBase on S3 architecture along with the numerous operational benefits that come with decoupling […]
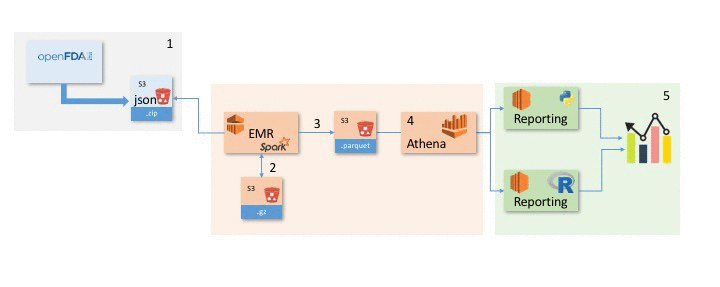
Analyze OpenFDA Data in R with Amazon S3 and Amazon Athena
One of the great benefits of Amazon S3 is the ability to host, share, or consume public data sets. This provides transparency into data to which an external data scientist or developer might not normally have access. By exposing the data to the public, you can glean many insights that would have been difficult with […]
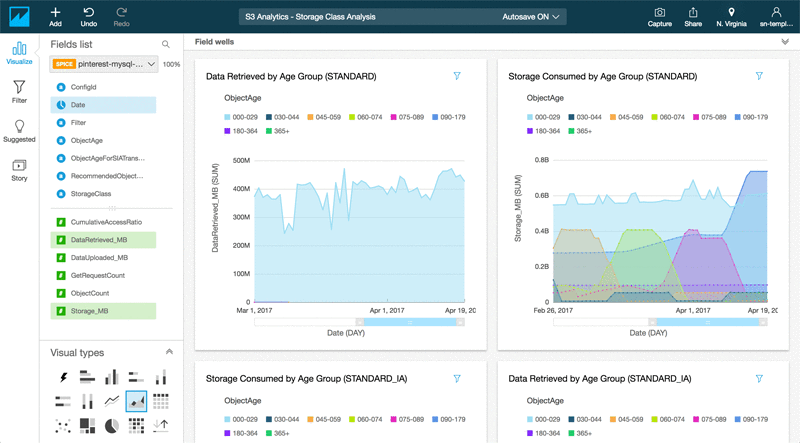
Visualize Amazon S3 Analytics Data with Amazon QuickSight
When Amazon S3 analytics was released in November 2016, it gave you the ability to analyze storage access patterns and transition the right data to the right storage class. You could also manually export the data to an S3 bucket to analyze, using the business intelligence tool of your choice, and gather deeper insights on usage and growth patterns. This helped you reduce storage costs while optimizing performance based on usage patterns. With today’s update, you can quickly and easily gain those deeper insights and benefits by analyzing and visualizing S3 analytics data in Amazon QuickSight. It takes just a single click from the S3 console, without the need for manual exports or additional data preparation.

Seven Tips for Using S3DistCp on Amazon EMR to Move Data Efficiently Between HDFS and Amazon S3
Although it’s common for Amazon EMR customers to process data directly in Amazon S3, there are occasions where you might want to copy data from S3 to the Hadoop Distributed File System (HDFS) on your Amazon EMR cluster. Additionally, you might have a use case that requires moving large amounts of data between buckets or regions. In these use cases, large datasets are too big for a simple copy operation.

Tips for Migrating to Apache HBase on Amazon S3 from HDFS
Starting with Amazon EMR 5.2.0, you have the option to run Apache HBase on Amazon S3. Running HBase on S3 gives you several added benefits, including lower costs, data durability, and easier scalability. HBase provides several options that you can use to migrate and back up HBase tables. The steps to migrate to HBase on […]

Securely Analyze Data from Another AWS Account with EMRFS
Sometimes, data to be analyzed is spread across buckets owned by different accounts. In order to ensure data security, appropriate credentials management needs to be in place. This is especially true for large enterprises storing data in different Amazon S3 buckets for different departments. For example, a customer service department may need access to data […]

Building an Event-Based Analytics Pipeline for Amazon Game Studios’ Breakaway
All software developers strive to build products that are functional, robust, and bug-free, but video game developers have an extra challenge: they must also create a product that entertains. When designing a game, developers must consider how the various elements—such as characters, story, environment, and mechanics—will fit together and, more importantly, how players will interact […]

Analyzing Data in S3 using Amazon Athena
April 2024: This post was reviewed for accuracy. Amazon Athena is an interactive query service that makes it easy to analyze data directly from Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to set up or manage and you can start analyzing your data immediately. You don’t even need to […]

Low-Latency Access on Trillions of Records: FINRA’s Architecture Using Apache HBase on Amazon EMR with Amazon S3
John Hitchingham is Director of Performance Engineering at FINRA The Financial Industry Regulatory Authority (FINRA) is a private sector regulator responsible for analyzing 99% of the equities and 65% of the option activity in the US. In order to look for fraud, market manipulation, insider trading, and abuse, FINRA’s technology group has developed a robust […]