AWS Compute Blog
Replacing web server functionality with serverless services
Web servers bring together many useful services in traditional web development. Developers use servers like Apache and NGINX for many common tasks. Linux, Apache, MySQL, and PHP formed the LAMP stack to power a large percentage of the world’s websites. Other variants, like the MEAN stack (MongoDB, Express.js, AngularJS, Node.js), have also been popular.
In the migration to serverless, it’s important to understand where this functionality moves to. There are significant benefits in taking a serverless approach to developing web apps but there are differences in where developers spend their efforts. This blog post provides a guide to serverless development for traditional web developers to help with this transition.
Comparing a “Hello World” example
To run a “Hello World” example in a highly available configuration, using a traditional webserver approach you need more than one server in more than one Availability Zone. This server contains an operating system, runtime, and web server software, together with your code. You might build an Amazon Machine Image (AMI) to help with creating more servers.

With a web framework like Express, the following code starts a server and listens on port 3000 for connections. For requests at the root URL, it responds with the “Hello World” greeting:

There is a reasonable amount of configuration and infrastructure needed to make this example work. Even creating a TLS connection requires you to maintain a certificate or install and maintain a service like Let’s Encrypt. Additionally, you must patch and maintain the underlying EC2 instance to keep this service running once it’s deployed.
The serverless equivalent is simpler. I can define the Hello World example using an AWS Serverless Application Model (SAM) template:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: hello-world
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
Handler: index.lambdaHandler
Runtime: nodejs12.x
InlineCode: |
exports.lambdaHandler = async (event, context) => {
return { 'statusCode': 200, 'body': 'Hello World!' }
}
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: getThe SAM deployment creates an AWS Lambda function with an Amazon API Gateway endpoint:
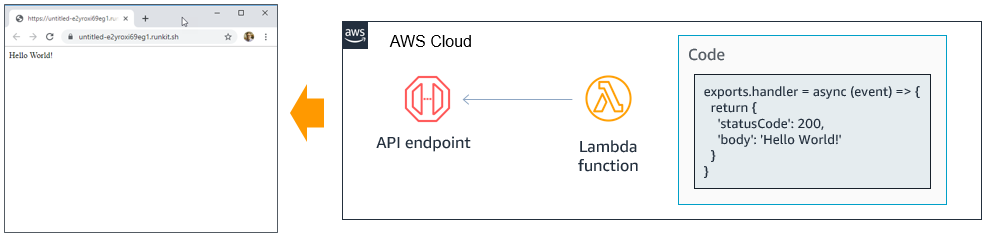
This is a highly available, scalable endpoint. The developer does not need to define VPCs, subnets or security groups, or install and manage a web server stack. A considerable part of the underlying infrastructure is managed for you, letting you focus primarily on the business logic of the application.
Additionally, using the default Service Quotas, this Endpoint can handle millions of requests a day. To handle this equivalent load with a traditional web server, you may need EC2 Auto Scaling. Lambda manages the scaling automatically, and also scales down as needed without any intervention from the developer.
Implementing authentication in serverless web apps
Many traditional web servers use web frameworks like Python Flask or Express and implement session-based authentication. This allows the server to authenticate users, often with a user name and password validation scheme. The server is responsible for storing user lists, and hashing and salting passwords securely. There are also user administration flows required for tasks such as creating accounts and resetting passwords.
While you can implement all these within a Lambda function, there is another approach that can be more secure and reduce boilerplate code. You can implement authorization and authentication in serverless development by using open standard JSON Web Tokens (JWTs). API Gateway then authenticates the user at the service level using Amazon Cognito, a Lambda authorizer, or with a JWT authorizer with HTTP APIs.
You use an identity provider such as Amazon Cognito or Auth0 to generate the user token. You pass the token in the API request in the Authorization header. The API Gateway service then validates the token before the request is sent downstream to your application.
While you can use JWTs in server-based web applications, there are benefits to separating out this functionality using serverless services:
- Failed requests do not put any additional load on your infrastructure. API Gateway also does not charge on authenticated routes when authorization headers are missing.
- You eliminate custom code for handling and processing logins since this happens before reaching your business logic.
- You can add support for social logins, multi-factor authentication (MFA) and OAuth without changing your code.
Additionally, as your application grows to more functions or across Regions, you are not relying on a single authentication point in your architecture. Each microservice validates a JWT independently and can verify the authorization claims that can be securely embedded in the token’s payload.
For web developers, one of the most common questions is how to handle the user interface elements related to authorization within the application. Auth0 offers a number of customizable components that you can integrate into any JavaScript application. Amplify Framework provides the Authenticator component that provides a wrapper for common flows for signing in users.

Using either approach eliminates boilerplate user management code and helps provide a consistent and professional login experience for your users. To learn more about using Auth0’s integrated sign-in, see the Ask Around Me application code repo.
Generating HTML, CSS and front-end templates
Many web frameworks use templating languages like Jinja or Mustache to help developers inject dynamic content into static HTML and CSS layouts. Typically, the web server creates the entire page layout for each request. You can use the same approach with Lambda if preferred, having the function build the HTML response for the browser.
However, single-page application (SPA) frameworks such as React, Vue.js, and AngularJS offer a different paradigm that works well for serverless development. The build process for SPA applications generates static HTML, CSS, and JavaScript files. When downloaded to the browser, they use JavaScript to fetch dynamic data and interact with the backend application:
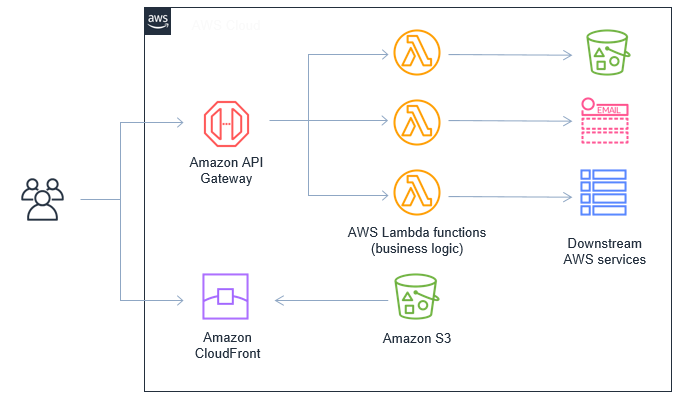
- The user visits the web application’s URL. The browser downloads the application’s HTML, CSS, and JavaScript files from Amazon S3 via Amazon CloudFront.
- The browser executes the application’s JavaScript.
- The application calls API Gateway endpoints to fetch and store dynamic data.
This architecture offers a number of benefits. First, serving the application’s assets is offloaded from your infrastructure to a global CDN. This reduces latency and increases scalability. Second, the HTML page building and rendering is managed entirely by the client browser, improving responsiveness and reducing network traffic with the application backend.
Uploading, processing, and saving binary files
Many web applications handle large binary files, such as user uploads. Processing these on web servers can be compute and network-intensive. You must also manage the amount of temporary space in use on the web server, and scale the fleet of servers appropriately during busy periods.
You can upload files serverlessly by using Amazon S3 directly. In this process, you request a presigned URL and upload the binary data directly to this endpoint. This reduces load on your infrastructure and increase scalability. The code is also simple to adapt for non-serverless applications that use S3. Watch this video to see how you can build an S3 uploader solution.
For processing binaries, you can use the S3 PutObject event to trigger serverless workflows. For example, you can process images, translate documents, or transcribe audio. For complex business workflows, the event can trigger AWS Step Functions workflows. This is a highly scalable way to bring automation and custom processing to binary uploads in your web applications.
When processing binary data, Lambda provides a 512 MB temporary file system (located at /tmp). You use this space for intermediate processing, not permanent storage, since the storage is ephemeral. For example, this can be useful for unzipping files or creating PDFs.
When saving files permanently in serverless applications, S3 buckets are the most common storage choice. S3 is highly durable and highly available, provides robust encryption options, and is a scalable, cost-effective solution for many workloads.
Storing application state
In many traditional applications, the web server stores temporary, context-specific application state, and a relational database stores data permanently.
Serverless tools have a range of different options available for managing state. Lambda functions are ephemeral and stateless, and there is no guarantee of reusing the same instance of a Lambda function multiple times.
For functions that need a durable store of user data that can be rehydrated between invocations, Amazon DynamoDB tables provide a low-latency, cost-effective solution. For example, this is ideal for recalling shopping cart contents or user profiles.
For more complex state, tracking long-lived or complex business workflows, the best practice is to use AWS Step Functions. You can model workflows in JSON that use parallel tasks, require human interaction, or take up to one year to complete.
Conclusion
In this post, I show how traditional web-server applications compare with their serverless counterparts. I show how the infrastructure is managed for you in serverless, and how code for serverless developers in primarily focused on business logic.
I look at how common web server tasks, such as authentication and authorization, are managed by scalable services. In single-page applications, front-end layouts are generated on the client-side, and the distribution is managed by a global CDN.
To learn more about how to build web applications with serverless, see the Ask Around Me application repo.