AWS Database Blog
Amazon Aurora MySQL zero-ETL integration with Amazon SageMaker Lakehouse
Companies face mounting pressure to extract timely insights from their rapidly growing transactional data without compromising system performance or operational simplicity. Traditionally, connecting MySQL databases with machine learning (ML) tools and analytics engines required complex data pipeline development and maintenance, leading to increased latency and operational overhead.
AWS has simplified this process by introducing a powerful new capability: zero-ETL integration between Amazon Aurora MySQL and Amazon RDS for MySQL with Amazon SageMaker. This seamless integration syncs your MySQL data into your lakehouse automatically and in near real time, enabling immediate access for analytics and ML workloads without the burden of managing custom code or infrastructure.
In this post, we explore how zero-ETL integration works, the key benefits it delivers for data-driven teams, and how it aligns with the broader zero-ETL strategy in AWS services. You’ll learn how this integration can enhance your data workflows, whether you’re building predictive models, entering interactive SQL queries, or visualizing business trends. By eliminating traditional extract, transform, and load (ETL) processes, this solution enables real-time intelligence securely and at scale to help you make faster, data-driven decisions.
What is zero-ETL integration?
Zero-ETL integration is a modern data integration approach designed to eliminate the need for traditional ETL pipelines. In conventional workflows, ETL is used to extract data from multiple sources, transform it into a common format, and load it into analytics or ML environments. Although effective, these processes are often time consuming, complex to maintain, and slow to adapt to changing business needs.
Zero-ETL integration streamlines the process by facilitating direct, point-to-point data movement without requiring complex pipelines or transformation logic. This enables near real-time data availability in downstream analytics systems such as Amazon SageMaker and Amazon Redshift. You don’t need to write custom ETL code, manage jobs, or schedule batch updates. Instead, data flows automatically and securely from source to destination, keeping it fresh and ready for analytics without impacting production systems.
Zero-ETL integrations address several challenges by eliminating traditional ETL overhead. These integrations significantly reduce system complexity compared to traditional ETL pipelines. Conventional ETL processes require intricate data mapping, conflict resolution, error handling, and monitoring frameworks, but zero-ETL integration simplifies these components into a streamlined workflow. By reducing these moving parts, companies can build, secure, and maintain their data workflows with greater ease and efficiency.
Zero-ETL integration also delivers substantial operational cost savings compared to traditional ETL systems. As data volumes continue to grow, conventional ETL processes demand increasing compute and storage resources, driving up costs. By eliminating the need for duplicate storage and reducing infrastructure requirements, zero-ETL integration provides a more cost-effective approach to scaling analytics workloads.
Zero-ETL integration dramatically accelerates time to insights by eliminating the delays inherent in traditional ETL development and deployment cycles. Instead of waiting for data pipelines to be built and executed, companies gain immediate access to fresh, production-grade data in their analytics and ML tools. This real-time data delivery enables faster, more agile decision-making, helping businesses respond quickly to emerging opportunities and challenges.
Zero-ETL integration use cases
You can use zero-ETL integration to access fresh, secure data across analytics and ML environments without traditional pipeline requirements, unlocking numerous high-impact use cases that deliver tangible business value.
Zero-ETL integration transforms automatically and continuously replicates data from Aurora MySQL-Compatible or Amazon RDS for MySQL into your Amazon SageMaker Lakehouse environment. Changes in your source database become available almost instantly to your analytics engines, SQL queries, and ML models. This allows for real-time decision-making and intelligent applications without the complexity of ETL pipeline management. Key use cases include:
- Content targeting – Deliver personalized digital content by using the latest clickstream and profile data from your MySQL database.
- Fraud detection – Instantly monitor financial systems and trigger alerts for suspicious behavior.
- Customer behavior analytics – Dynamically adjust campaigns based on real-time user activity.
- Data quality monitoring – Use ML models to identify data anomalies before they affect downstream systems.
- Gaming experience optimization – Fine-tune game mechanics and matchmaking based on real-time player activity.
By using fresh data for decision-making, companies can enhance customer experience, minimize risk exposure, and respond more quickly to changing user behavior. Companies often face challenges with MySQL databases distributed across teams, Regions, and applications, creating data silos that hinder comprehensive analysis. Traditional approaches require complex ETL pipelines to extract, clean, and consolidate data into a central location. This can result in increased latency and engineering overhead.
Zero-ETL integration addresses this challenge by automatically and continuously replicating data from multiple Aurora MySQL or RDS for MySQL instances into a central lakehouse environment. This approach eliminates the need for custom pipelines or batch jobs. After data is consolidated in a lakehouse, teams can use SageMaker or Amazon Redshift to process large-scale datasets by using familiar SQL, ML, or business intelligence tools. Cross-system analytics, predictive modeling, and real-time dashboards are possible without manual data preparation. Key use cases include:
- Cross-system reporting – Create unified dashboards that combine data from multiple business units or applications.
- Petabyte-scale analysis – Execute complex analytical queries across large datasets (orders, logs, events) without impacting transactional database performance.
- Built-in ML with SQL – Use Amazon Redshift ML to run billions of predictions by using SQL syntax, with SageMaker trained models deployed directly in your analytics platform.
- Federated queries – Combine MySQL data with content from Amazon Simple Storage Service (Amazon S3), other Amazon Redshift clusters, or third-party sources in single SQL queries.
By providing centralized data access and unified analytics capabilities, companies can uncover deeper insights, identify long-term trends, and power sophisticated AI and ML workloads without building custom data pipelines.
Managing ETL pipelines at scale presents significant challenges for data teams. Traditional approaches require custom development for schema mappings, data quality checks, retry logic, and monitoring systems. When source schemas change, manual pipeline updates are necessary to prevent failures. As data volumes grow and new sources are added, these systems become increasingly fragile, costly, and time consuming to maintain.
Zero-ETL integration helps eliminate these challenges by automatically and continuously replicating data and schema changes from Aurora MySQL or RDS for MySQL to your analytics environment. This automated approach removes the need for custom code, infrastructure deployment, pipeline maintenance, and batch job scheduling. Teams can redirect their focus from managing data movement to using data for analytics, reporting, and ML. Key uses include:
- Schema replication – Automatically propagate source table structure changes without manual reconfiguration.
- Change data capture – Maintain lakehouse synchronization with operational systems through near real-time updates, deletes, and inserts.
- Governed data sharing – Apply consistent, fine-grained access control across all data consumers, including SQL users, ML engineers, and BI tools.
This streamlined approach allows data engineers to focus on innovation rather than pipeline maintenance, and companies benefit from reduced costs, improved reliability, and faster time to insight.
Setting up zero-ETL integration
This post’s solution shows how to enable and use zero-ETL integration between SageMaker and your MySQL database (using either Aurora MySQL or RDS for MySQL). We’ll show you how to configure the integration, enabling automatic and continuous near real-time data replication to your lakehouse. You’ll learn how this data can be seamlessly used in SageMaker for ML workflows, including model training and inference, without the need to build or maintain ETL pipelines. Though we use Aurora MySQL in our examples, the same steps apply if you’re using RDS for MySQL.
The following diagram illustrates this post’s solution architecture.
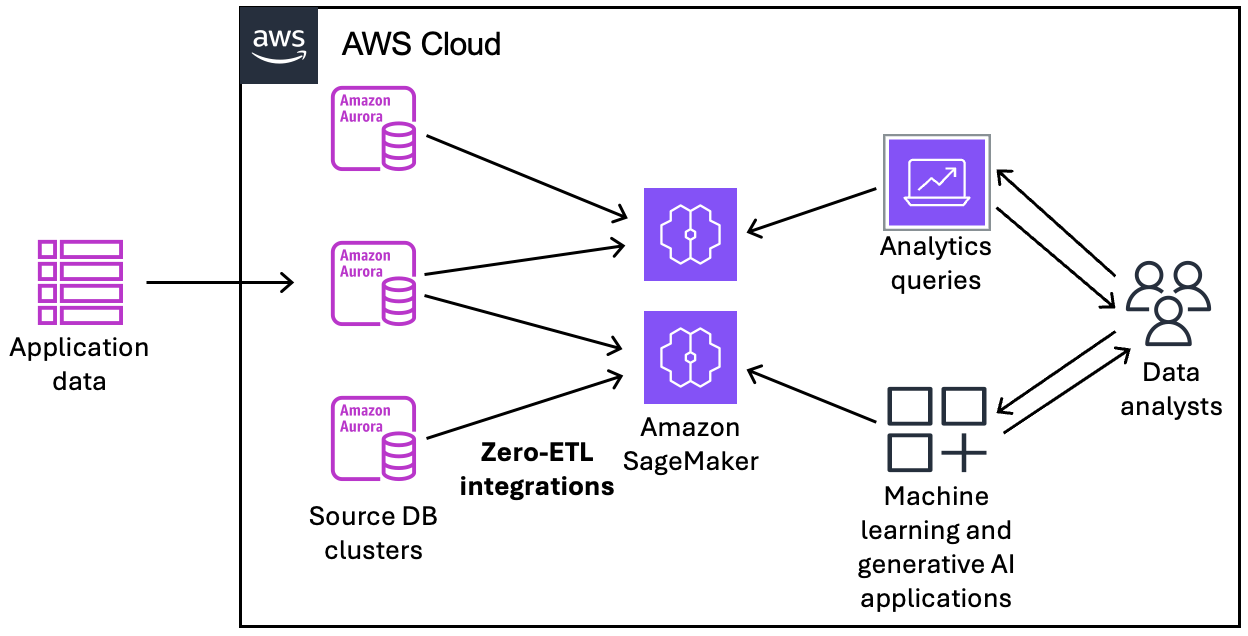
The following are the steps needed to set up zero-ETL integration. For complete zero-ETL integration getting started guides, see Aurora zero-ETL integrations and Creating zero-ETL integrations with an Amazon SageMaker lakehouse.
- Configure the Aurora MySQL source with a customized DB cluster parameter group.
- Configure the Amazon SageMaker Lakehouse destination with the required resource policy on the AWS Glue managed catalog to authorize inbound integrations.
- Configure the required permissions.
- Create a zero-ETL integration.
- Monitor and verify the integration.
Prerequisites
Before implementing zero-ETL integration, ensure you have the following components in place:
- An Amazon Elastic Compute Cloud (Amazon EC2) security group set up and an allowed DB instance port connection to the source and target DB instances.
- AWS Command Line Interface (AWS CLI) version 2 installed and configured with the appropriate AWS Identity and Access Management (IAM) credentials and permissions to interact with Amazon Relational Database Service (Amazon RDS) and SageMaker.
- A MySQL source such as an Aurora MySQL cluster or RDS for MySQL instance.
- For Aurora MySQL clusters, zero-ETL integrations require specific settings for the binary logging (binlog) parameters within the Aurora DB cluster parameter group. This is because the integration relies on the enhanced binlog (
aurora_enhanced_binlog=1) for real-time data replication. In addition, make sure that thebinlog_transaction_compressionparameter is not set toON, and that thebinlog_row_value_optionsparameter is not set toPARTIAL_JSON. By default, these parameters aren’t set, so for Aurora MySQL clusters, create an Aurora DB cluster parameter group and configure the parameters. - To use zero-ETL integration with an RDS for MySQL instance, you must enable binlogs by setting a positive, nonzero backup retention period. You also need to create a new RDS DB parameter group and configure the binlog parameters. Specifically, set
binlog_format=ROWandbinlog_row_image=full. These specific values are required for zero-ETL integration to control data replication.
Configure the source MySQL database for zero-ETL integration
When you have all the prerequisites in place, you can configure the source MySQL database for zero-ETL integration.In this post, we focus on integrating Aurora for MySQL with a SageMaker lakehouse, but you can alternatively use RDS for MySQL as the source database because the steps and configuration remain the same.
Create a custom Aurora MySQL cluster parameter group
As we discussed in the prerequisites of this post, an Aurora MySQL database needs to have binary logs (binlogs) enabled for real-time replication. In this section, you’ll create the DB cluster parameter group and configure binlogs. For more information see, Getting started with Aurora zero-ETL integrations.
Use the following AWS CLI command to create an Aurora MySQL cluster parameter group:
Now set the binlogs in the parameter group by modifying the parameter group:
The parameter group is now fully configured and ready to be applied to your Aurora MySQL cluster.
Note: For an RDS for MySQL instance, enable binlogs by setting a positive, nonzero backup retention period. You also need to create a new Amazon RDS DB parameter group and configure the binlog parameters. Specifically, set binlog_format=ROW and binlog_row_image=full. These specific values are required for zero-ETL integration to control data replication.
Select or create a source Aurora MySQL cluster
If you already have an Aurora MySQL cluster, you can use it, or you can create a new Aurora MySQL cluster. While creating an Aurora MySQL cluster, use the same parameter group (aurora-zetl-cluster-pg) you created in the preceding step:
Note: Throughout this post, be sure to replace the <placeholder values> with your own information.
If you’re creating a new Aurora MySQL cluster, wait for your DB instance(s) to be in an Available status. You can also verify DB instance status by using the describe-db-instances API call:
Note: If you prefer to use RDS for MySQL, the process differs slightly because you would create an RDS for MySQL DB instance. For detailed step-by-step instructions about creating an RDS for MySQL DB instance, see Creating an Amazon RDS DB instance. Both Aurora MySQL and RDS for MySQL are supported as integration sources, so you can choose the option that best aligns with your workload.
Reboot the cluster to apply parameter changes
Because the binlog parameters were set with ApplyMethod=pending-reboot, a cluster reboot is required before zero-ETL integration can function correctly:
Wait until the cluster and the primary instance are back in Available status. For the RDS for MySQL DB instance, use the reboot-db-instance AWS CLI command. For more information, see reboot-db-instance.
Create a target AWS Glue managed catalog
With your source MySQL database configured for binary logging, the next step is setting up your target Amazon SageMaker Lakehouse environment. This destination configuration means your zero-ETL integration can replicate data continuously from your Aurora (or RDS for MySQL) database directly into the lakehouse. Zero-ETL integration uses AWS Glue Data Catalog backed by Amazon Redshift managed storage as its target destination. To enable this functionality, you need to create a managed catalog, configure IAM permissions for Amazon SageMaker Lakehouse to access and query the managed catalog, and set up authorization for incoming integration requests from your source database.
Create an AWS Glue managed catalog
You can reuse an existing AWS Glue managed catalog if you already have one configured for Amazon SageMaker Lakehouse. If not, you need to create a new catalog managed by AWS Glue to store table metadata and serve as the landing zone for your replicated datasets. The AWS Glue managed catalog is essentially the schema layer. Zero-ETL integration streams the data into Amazon Redshift managed storage, and AWS Glue keeps track of table definitions so that tools such as SageMaker, Athena, and Amazon Redshift Spectrum can query the data.
Create an IAM role for AWS Glue and Amazon Redshift to access the AWS Glue managed catalog
Now, use the following command to create an IAM role so that AWS Glue and Amazon Redshift can interact with the catalog. This role serves two key functions: It allows AWS Glue and Amazon Redshift to perform catalog operations, and it authorizes incoming integration requests from your source database. Both AWS Glue and Amazon Redshift will assume this role when accessing the managed catalog and processing data from your zero-ETL integration.
Next, attach a policy to this IAM role that provides the minimum required permissions for AWS Glue and Amazon Redshift. This policy should also include the necessary permissions for encryption key actions to ensure secure data handling throughout the integration process:
Set up AWS Lake Formation access
Before using the managed catalog for zero-ETL integration, you must configure data lake administrators in AWS Lake Formation who will have administrative or read-only privileges on the managed resources. Additionally, you need to grant ReadOnlyAdmin permissions to the Amazon Redshift service-linked role, AWSServiceRoleForRedshift , in your account. If this role doesn’t exist in your account or you need to verify its permissions, see Using service-linked roles for Amazon Redshift. These permission configurations allow AWS Glue and Amazon Redshift to securely access metadata while following least-privilege security principles.
Create the AWS Glue managed catalog backed by Amazon Redshift managed storage
Because you have configured IAM permissions and Lake Formation settings, you now can create the AWS Glue managed catalog. This managed catalog serves as the persistent metadata layer that will store and manage all table definitions and schema information for data flowing through your zero-ETL integration.
Register the catalog as a zero-ETL integration target
To prepare your target AWS Glue managed catalog for zero-ETL integration, use the create-integration-resource-property command with these required parameters:
- The
--resource-arnparameter specifies the Amazon Resource Name (ARN) of your AWS Glue managed catalog that will serve as the integration target - The
--target-processing-propertiesparameter requires the ARN of an IAM role that has describe permissions on the target AWS Glue managed catalog. These parameters ensure proper configuration and authorization for the zero-ETL integration to function correctly
You can use the GlueDataCatalogDataTransferRole created in the previous step because it already includes the minimal describe permissions required for this integration. Alternatively, you can create a new IAM role specifically for this purpose and attach the necessary minimal permissions to meet your company’s security requirements.
Configure authorization for inbound integration requests
The final step in creating a target managed catalog is to define a resource-based access policy that authorizes zero-ETL integration to push data into your catalog. This policy grants AWS Glue the necessary permissions to create and authorize incoming integration requests from your source database. Apply this resource policy by using the AWS Glue put-resource-policy API call to complete the catalog configuration for your zero-ETL integration:
With these configuration steps complete, your AWS Glue managed catalog is ready to receive data from your zero-ETL integration. The catalog will automatically maintain table metadata, allow downstream queries from analytics tools, and enforce secure access controls throughout the process. This setup makes sure seamless data flows from your Aurora or RDS for MySQL database into your Amazon SageMaker Lakehouse environment, providing a foundation for real-time analytics and ML workflows.
Load data in the source Aurora MySQL database
Now that your Aurora MySQL database is configured and ready, you need to populate it with sample data that will serve as the historical baseline for your zero-ETL integration. This initial dataset provides the foundation for testing and demonstrating the integration capabilities. After establishing the zero-ETL integration, subsequent database changes will be streamed automatically in near real-time to your target AWS Glue managed catalog.
Connect to the source Aurora MySQL cluster
Use the following commands to establish a connection to your source Aurora MySQL cluster:
Create a database and table
Use the following code to create a database:CREATE DATABASE my_db;USE my_db;
Now, create a table named books_table to store information about books:
Insert historical data
Use the following code to insert a row:
This table serves as a representative dataset to demonstrate the zero-ETL integration’s data capture and streaming capabilities. After your zero-ETL integration is active, all database changes including inserts, updates, and deletes will be automatically captured and streamed to your AWS Glue managed catalog. This creates a seamless data pipeline from your Aurora MySQL database to your Amazon SageMaker Lakehouse environment, enabling real-time analytics on your operational data.
Create a zero-ETL integration
Because your Aurora MySQL database is now populated with historical data, you can establish the zero-ETL integration that will continuously stream database changes to your AWS Glue managed catalog backed by Amazon Redshift managed storage. This integration eliminates the complexity of building and maintaining manual ETL pipelines while enabling near real-time analytics capabilities within your Amazon SageMaker Lakehouse environment. The result is a seamless, automated data pipeline that keeps your analytics environment synchronized with your operational database.
Create the integration
Create the integration between your source MySQL database and target AWS Glue catalog by using the aws rds create-integration AWS CLI command. This command establishes the connection and begins the data streaming process. You can customize the integration by specifying additional configurations, such as data filters, to control which data gets replicated to your target environment:
When you execute the command, the zero-ETL integration begins provisioning and enters a ‘creating’ state. The AWS CLI response provides important details about the integration configuration, including:
Example output:
When the integration status changes to “active”, your zero-ETL integration pipeline is fully operational. From this point forward, all database changes in your source Aurora MySQL (or RDS for MySQL) cluster will be automatically captured and replicated to the AWS Glue catalog in near real-time. This seamless replication provides immediate access to both your existing historical data and newly streaming live data, enabling continuous analytics without manual intervention.
Monitor the integration
Before generating new live data, let’s verify that the integration has reached an “active” state by running the describe-integrations AWS CLI command. This monitoring step is crucial for confirming that changes from your source Aurora cluster are successfully streaming to the AWS Glue managed catalog without errors:
Verify the zero-ETL integration
Now that your historical data is loaded and the zero-ETL integration is “active”, you need to validate that the data has been successfully replicated to your Amazon SageMaker Lakehouse environment. This validation process confirms that both your initial baseline dataset and subsequent real-time updates are flowing correctly through the integration pipeline, ensuring your analytics environment has access to complete and current data.
Grant Lake Formation permissions
Before you can query the AWS Glue managed catalog by using the Amazon Redshift Data API, you must make sure the IAM user or role has the appropriate permissions to create and manage tables within the catalog. Use the Lake Formation grant-permissions API to provide these necessary permissions so that Amazon Redshift can properly interact with your AWS Glue managed catalog for the zero-ETL integration. These permissions are essential for successful data access and query execution. For more information, see Creating an Amazon Redshift managed catalog in the AWS Glue Data Catalog.
These Lake Formation permissions allow your queries to create temporary tables or query tables when necessary. They also allow metadata inspection for data verification and validation purposes, which translates to smooth query execution and proper interaction with your zero-ETL integrated data.
Query historical data by using the Amazon Redshift Data API
With the necessary permissions in place, you can now verify your historical data by querying the AWS Glue managed catalog through the Amazon Redshift Data API. Begin this verification process by executing a simple SELECT statement against the catalog to confirm that your data has been successfully replicated and is accessible for analysis:
The following command returns a unique query identifier that allows you to monitor the execution status and retrieve results from your query:
Monitor your query’s progress by using the describe-statement API with the query ID. Continue checking until the status shows , indicating that your query has completed successfully:
To complete the verification process and view your historical data now available in Amazon SageMaker Lakehouse, retrieve the query results by using the get-statement-result API call:
With your zero-ETL integration now active, you can demonstrate real-time data streaming by adding new data to your source Aurora MySQL instance. Execute the following INSERT query to add a new row, which will show how changes are automatically replicated in near real time:
You can verify that the new changes from your source database have been replicated to the target environment within seconds. Use the same Amazon Redshift Data API workflow you used earlier to confirm the real-time replication:
Finally, retrieve the query results by using the get-statement-result API call to confirm that your newly inserted data has been successfully replicated to the target Amazon SageMaker Lakehouse environment:
This verification process confirms that your zero-ETL integration from Aurora MySQL (or RDS for MySQL) to Amazon SageMaker Lakehouse is fully operational and continuously replicating both historical and real-time data. Although zero-ETL integration significantly simplifies data replication, it’s important to understand certain limitations regarding supported data types, schema change handling, and data filtering capabilities. For comprehensive details about these considerations and best practices, see Aurora zero-ETL integrations and Amazon RDS zero-ETL integrations.
Clean up
After confirming that your zero-ETL integration is working correctly and all test data has been successfully replicated. When you delete a zero-ETL integration, the existing transactional data remains intact in both your source Aurora (or RDS for MySQL) database instance and the target AWS Glue managed catalog. However, Amazon Aurora will stop sending new changes to the AWS Glue managed catalog, effectively ending the real-time data synchronization while preserving all previously replicated data.This section guides you through the cleanup process to remove the resources and components you created during this walkthrough. Proper cleanup helps avoid unnecessary costs and maintains good resource management practices in your AWS environment.
Delete the zero-ETL Integration: Begin the cleanup process by removing the integration between your source Amazon RDS database and the AWS Glue managed catalog. Execute the following command to delete the integration:
Delete the AWS Glue managed catalog: After successfully deleting the integration, delete the AWS Glue managed catalog that served as your zero-ETL target destination. Use the following command to remove the catalog:
Deleting the managed catalog permanently removes all associated table metadata and Amazon Redshift managed storage references from the managed catalog, effectively freeing up storage resources and eliminating any ongoing costs related to the zero-ETL integration’s target environment.
Delete the Aurora DB cluster: If you created the source Aurora DB cluster for this demonstration and you no longer need it, you can complete the cleanup by deleting the entire DB cluster. By skipping the final snapshot option, you avoid retaining any test data and ensure complete resource removal:
Summary
In this post, we showed how to configure zero-ETL integration between Aurora MySQL and your Amazon SageMaker Lakehouse environment using AWS CLI. This integration eliminates the complexity of building and maintaining custom ETL pipelines by automatically replicating data from your MySQL database to a lakehouse in near ML learning workflows to operate on fresh, production-grade data with minimal operational overhead.
As you move forward, consider expanding this zero-ETL approach to additional MySQL-based workloads or other supported data sources to create a centralized data access strategy across your company. You can also explore advanced analytics scenarios by combining zero-ETL integrations with Amazon Redshift capabilities, such as large-scale SQL analytics, Amazon Redshift ML for in-database ML, or federated queries that span multiple data lakes and warehouses. These integrations provide the foundation for building a comprehensive, real-time data platform that scales with your business needs.
To get started, see the AWS zero-ETL documentation for setup guidance, supported configurations, troubleshooting integrations, and architectural best practices.
About the authors
Harpreet Kaur Chawla
Vijay Karumajji