AWS Database Blog
Automate Oracle PL/SQL to PostgreSQL migration with Amazon Bedrock and Strands Agents
In Oracle-to-PostgreSQL migrations, schema objects like tables and indexes convert readily. Stored procedures, functions, packages, and triggers are where the work becomes time-consuming, resource-intensive, and challenging. These objects contain complex PL/SQL logic that takes senior database architects days or weeks to rewrite manually, creating a bottleneck that delays migrations and increases cost.
AWS Database Migration Service Schema Conversion (AWS DMS SC) handles schema and DML conversion well and includes generative AI–powered conversion capabilities. Complex PL/SQL patterns such as transaction control, exception handling, and Oracle-specific functions still have cases where automated conversion is incomplete. Those remaining objects end up in a manual queue.
In this post, you learn how to build a generative AI–powered migration assistant that helps automate portions of the last mile of code conversion. Using Anthropic’s Claude Sonnet 4.6 on Amazon Bedrock, the Strands Agents framework, and the AWS Knowledge MCP Server, you can automate the conversion and validation of PL/SQL objects against Amazon Aurora PostgreSQL-Compatible Edition. The assistant reads the AWS DMS SC assessment CSV, fetches live PL/SQL source from Oracle, converts each object, deploys the result to Aurora PostgreSQL through AWS Lambda, and runs automated tests, in a single pipeline.
The complete reference implementation is available on the aws-samples GitHub repository.
Solution overview
The SQL migration assistant is a Streamlit-based tool that orchestrates the full conversion pipeline. It reads the AWS DMS SC assessment CSV, fetches live PL/SQL source from Oracle, converts each object using an Amazon Bedrock agent, deploys the result to Aurora PostgreSQL through Lambda, and runs automated tests in a single pipeline.
The following diagram shows the system architecture and circuit flow.
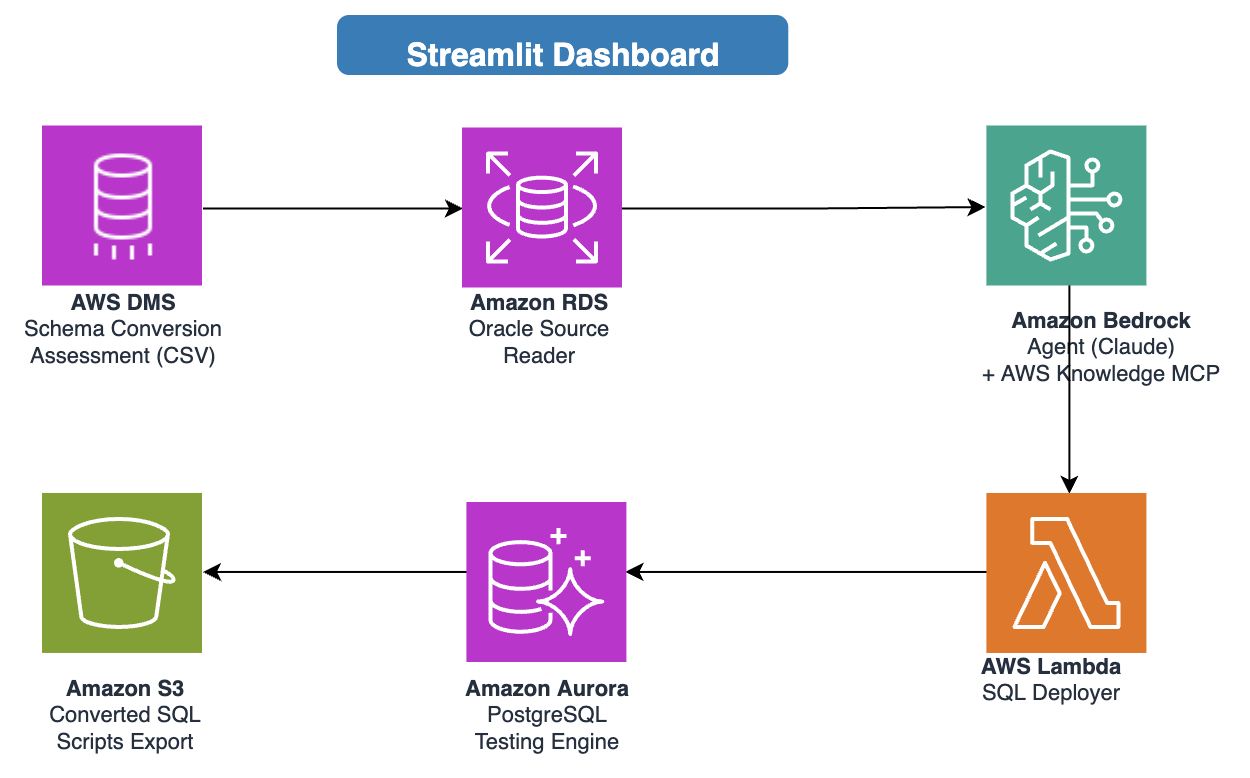
AWS services used
| Service | Role |
| Amazon Bedrock | Hosts Claude Sonnet 4.6 for PL/SQL-to-PL/pgSQL code generation |
| Amazon Aurora PostgreSQL-Compatible Edition | Target database for converted procedures, functions, and triggers |
| AWS Lambda | Runs SQL deployment and validation inside the VPC |
| Amazon Simple Storage Service (Amazon S3) | Stores converted scripts, assessment reports, and audit logs |
| Amazon Relational Database Service (Amazon RDS) for Oracle | Source database for live PL/SQL extraction |
| AWS Database Migration Service Schema Conversion (AWS DMS SC) | Initial schema assessment and action item identification |
| AWS Knowledge MCP Server | Real-time access to AWS migration documentation during conversion |
| AWS Identity and Access Management (IAM) | Access control for service interactions |
| AWS Secrets Manager | Secure credential storage and runtime retrieval |
| Strands Agents framework | Agent orchestration, tool calling, and audit trail generation |
How this solution fits into the AWS migration ecosystem
AWS offers several generative AI–powered migration capabilities:
- AWS DMS SC with generative AI adds large language model (LLM)-powered conversion directly inside the AWS DMS console. It improves conversion rates by 5–10 percent and converts an additional 15–20 percent of unconverted code. The end result is up to 90 percent of code converted.
- Amazon Bedrock can be used interactively to convert individual procedures through prompt engineering.
This solution complements those capabilities by providing a transparent, end-to-end pipeline specifically for Oracle PL/SQL migration. It takes the AWS DMS SC assessment CSV as input, fetches live source code from Oracle, uses a Strands Agents agent backed by Amazon Bedrock with real-time AWS documentation access through the AWS Knowledge MCP Server, deploys converted code to Aurora PostgreSQL through Lambda for immediate syntax validation, runs nine automated tests per object, generates per-issue confidence scores and reasoning, and offers an interactive chat interface for follow-up questions about specific conversions.
This approach scales to hundreds of objects without human intervention per object. It provides full transparency into conversion decisions and automated validation. The architecture is extensible to other dialect pairs that AWS DMS SC supports.
How AWS DMS SC action items drive the conversion
When you migrate from Oracle to Aurora PostgreSQL, AWS DMS SC generates a detailed assessment report identifying code objects it could not fully convert. AWS DMS SC includes generative AI capabilities for conversion, but for complex PL/SQL patterns it produces action items: specific issues that require additional handling.
Example action item codes:
5034: Transaction control statements (COMMIT/ROLLBACK) inside procedures that PostgreSQL handles differently.5035: Exception handling blocks with embedded transaction control.5444: Machine learning (ML)-assisted conversions flagged for human review.5584: Oracle-specific functions (SYSDATE,NVL,DECODE) that need PostgreSQL equivalents.
These are only a subset. AWS DMS SC can produce thousands of action item codes covering data types, cursors, packages, sequences, dynamic SQL, and more. The tool reads whatever action items AWS DMS SC reports in the CSV file, passes them to the Amazon Bedrock agent along with the Oracle source code, and the agent addresses them in the conversion.
Prerequisites
To follow this post, you need intermediate knowledge of Oracle PL/SQL, PostgreSQL administration, and AWS services. You need the following:
- An AWS account with sufficient permissions to provision and operate the services used in this solution: Amazon RDS for the source and target databases, AWS Lambda for the deployment function, Amazon Bedrock for model invocation, Amazon S3 for artifact storage, and AWS Secrets Manager for credential storage. Scope each role to the minimum permissions required for the actions and resources you use, following the IAM least-privilege guidance. For service-specific permission references, see the IAM documentation for Amazon RDS, AWS Lambda, Amazon Bedrock, Amazon S3, and AWS Secrets Manager.
- An Oracle database instance with PL/SQL stored procedures, functions, and triggers. For testing this solution, we recommend Oracle Database 19c or Oracle Database Express Edition (XE) running on Amazon Elastic Compute Cloud (Amazon EC2), which provides full PL/SQL compatibility with Oracle Enterprise Edition without requiring a commercial license. To set up Oracle on Amazon EC2, launch an EC2 instance using the Oracle Linux Amazon Machine Image (AMI) from AWS Marketplace, then install the Oracle Database 19c RPM by following the Oracle installation guide.
- An Amazon Aurora PostgreSQL-Compatible Edition cluster, or an Amazon RDS for PostgreSQL instance, as the target database. RDS for PostgreSQL is typically a lower-cost option for testing this solution, while Aurora PostgreSQL is recommended for production workloads requiring higher performance and availability.
- AWS DMS SC configured and connected to your Oracle source database.
- A Lambda function configured inside the Aurora VPC with access to the target database.
- Access to Amazon Bedrock with the Anthropic Claude Sonnet 4.6 model enabled in your AWS Region.
- The Strands Agents framework installed in your development environment.
- Database credentials stored in AWS Secrets Manager.
- For production deployments, integrate the conversion engine into continuous integration and continuous delivery (CI/CD) pipelines, a production web framework, or as a step in an AWS Step Functions workflow.
Implementation steps
The following steps walk you through configuring the Amazon Bedrock agent, deploying the Lambda SQL deployer, running the conversion pipeline, and validating each converted object with the testing engine.
Step 1: Configure the Amazon Bedrock agent
The core of the migration assistant is a Strands Agents framework-based agent backed by Amazon Bedrock. This step covers the two key configuration decisions that most affect conversion quality: the choice of agent framework and the system prompt rules.
1.1 Why Strands Agents and MCP
The Strands Agents framework provides a clean abstraction for building generative AI agents with tool access. Combined with the AWS Knowledge MCP Server, the agent looks up official AWS migration documentation in real time during conversion. The agent actively consults the Migration Playbook for specific conversion patterns rather than relying solely on training data.
Each conversion trace records whether MCP was used and which documentation pages were consulted, providing a full audit trail.
1.2 Configure the system prompt
Conversion quality depends heavily on the system prompt. Through iterative testing, several critical rules were added:
- Functional equivalence: Every behavior in the Oracle source must exist in the PostgreSQL target. The model must not improve or simplify the code. If a trigger fires on
INSERT,UPDATE, andDELETEin Oracle, it must fire on all three in PostgreSQL. - Parameter fidelity: The model must not add, remove, or reorder parameters. Oracle callers depend on positional arguments, so changing the parameter list breaks compatibility. This rule was added after we discovered that the model would sometimes add
OUTparameters that didn’t exist in the source. - Type consistency in function and procedure signatures: in the converted PL/pgSQL definitions, Oracle
NUMBERparameters and return types always map to PostgreSQLNUMERIC, neverBIGINT. This prevents function overloading issues whereCREATE OR REPLACEcreates a duplicate instead of replacing, because PostgreSQL treats different parameter types as different function signatures. This rule applies to function and procedure signatures specifically. Oracle table column types may be mapped differently. For example, aNUMBER(10)primary key column commonly becomesBIGINTin the target table, and the agent treats those independently. - Trigger event preservation: A mandatory rule requires the model to copy the exact event list from the Oracle source. Early testing revealed the model would sometimes simplify
AFTER INSERT OR UPDATE OR DELETEto onlyAFTER UPDATE, silently dropping events. - Post-processing safety net: Even with strong prompt rules, the model occasionally produces unexpected output. A
_fix_trigger_code()function runs after every trigger conversion to remove schema prefixes fromCREATE TRIGGERnames and verify and correct the trigger event list against the Oracle source. This gives you a reliable safety net when the model deviates from the rules.
Step 2: Deploy the AWS Lambda SQL deployer
Deploy the SQL deployment Lambda function inside the Aurora VPC. PostgreSQL validates PL/pgSQL function bodies at CREATE time, so deploying through Lambda gives you immediate syntax validation.
Follow these steps:
- On the Lambda console, choose Create function. Select the latest supported Python runtime (Python 3.12 was used here; 3.11 and newer also work. Match the runtime version when building the psycopg2 layer in the next step). Set memory to 256 MB and timeout to 60 seconds.
- Configure VPC access: select the same VPC and private subnets as your Aurora cluster. Create a security group allowing outbound TCP traffic to the Aurora security group on the port your cluster listens on (5432 by default; check your cluster configuration if you customized it). The Aurora security group must allow inbound traffic from the Lambda security group on the same port.
- Attach an AWS Identity and Access Management (IAM) execution role with
AWSLambdaVPCAccessExecutionRoleand a scoped Secrets Manager policy: - Add a psycopg2 layer to your Lambda function. Since psycopg2 is a compiled package, it must match the Lambda runtime’s underlying Linux: Python 3.11 runs on Amazon Linux 2, while Python 3.12 and newer run on Amazon Linux 2023. Build the layer in a container that matches the runtime:
Then attach the layer to your function under Configuration → Layers.
- In the handler, set
autocommit=Trueon the connection and return PostgreSQL error details on failure:
Important: Set autocommit=True for the database connection. Without this, DDL might not persist if the transaction isn’t committed before the connection closes. The Lambda appears to succeed but objects don’t persist. This was a subtle bug discovered during development.
Lambda deployment also provides immediate syntax validation: if the converted code has PostgreSQL syntax errors, the deployment fails with a specific error message (using e.pgerror) that can be fed back to the agent.
Step 3: Run the conversion pipeline
The SQL migration assistant orchestrates the full conversion pipeline. Follow these steps to convert your Oracle objects.
3.1 Export the AWS DMS SC assessment report
- Open AWS DMS SC and connect to your source Oracle database.
- Run the schema assessment to identify unconverted objects.
- Export the assessment results as a CSV file. The file contains action item codes for each database object.
- Upload the CSV to the migration assistant tool.
Note: AWS DMS SC exposes APIs for the assessment workflow, so you can automate this entire export step end to end. We use the manual export here for clarity. An API-driven version is a natural next iteration.
3.2 Fetch Oracle source code
The source reader component connects directly to the source Oracle database to fetch live PL/SQL source code. It queries the following Oracle catalog views:
USER_SOURCE: for procedures and functions.USER_TRIGGERSandUSER_SOURCE: for trigger DDL reconstruction.
Oracle stores trigger definitions as compiled objects without the original DDL. The solution reconstructs trigger DDL by querying USER_TRIGGERS and USER_SOURCE tables, then reassembling the CREATE TRIGGER statement, including timing (BEFORE/AFTER), event list (INSERT/UPDATE/DELETE), table name, and row level (FOR EACH ROW).
3.3 Convert objects with Amazon Bedrock
The migration assistant groups action items by database object and submits each object to the Amazon Bedrock agent. The agent uses the Strands Agents framework and consults the AWS Knowledge MCP Server for real-time migration documentation access.
Example conversion:
Oracle source procedure (SQL):
PostgreSQL target procedure (generated by the model, plpgsql):
Key conversions applied:
NUMBERtoNUMERIC: Applied to all parameters and variables.SYSDATEtoclock_timestamp()::DATE: Cast toDATEbecause the parameter type isDATE. ForTIMESTAMPparameters, useclock_timestamp()directly.seq_order.NEXTVALtonextval('seq_order'): Standard PostgreSQL sequence syntax.DBMS_OUTPUT.PUT_LINEtoRAISE NOTICE: PostgreSQL equivalent for output messages.- Removed explicit
COMMIT/ROLLBACK: PostgreSQL auto-commits procedures called outside an explicit transaction. - Added
LANGUAGE plpgsqldeclaration: Required for PL/pgSQL procedures in PostgreSQL. - Changed delimiter to
$$ ... $$: Standard PostgreSQL procedure body delimiter.
3.4 Handle trigger conversions
Triggers require special handling because Oracle stores trigger definitions as compiled objects without the original DDL. The solution reconstructs trigger DDL and applies the following rules during conversion:
- Event preservation:
BEFORE INSERT OR UPDATE ON ordersmust be copied exactly. The model can’t drop events. - Row-level specification: Add
FOR EACH ROWif present in the Oracle source. NEW/OLDreferences: Convert:NEWtoNEWand:OLDtoOLD(removing the colon prefix).WHENclause migration: Preserve trigger firing conditions, converting Oracle syntax to PostgreSQL equivalents.
Step 4: Run the automated testing engine
Each converted object goes through 9 automated test scenarios covering syntax validation, deployment verification, functional testing, and dependency checking. The testing engine runs these tests automatically after each conversion.
| # | Test | Type | What it checks |
| 1 | Deploy to Aurora | Syntax | Sends CREATE OR REPLACE to Aurora using Lambda. PostgreSQL parses and compiles the PL/pgSQL body. |
| 2 | Object exists | Run | Queries information_schema to confirm the object persisted in the correct schema. |
| 3 | NULL input handling | Functional | Function/procedure handles NULL inputs gracefully without crashing. |
| 4 | Oracle syntax residue | Static | No Oracle-specific keywords remain (SYSDATE, NVL, DECODE, DBMS_OUTPUT, and so on). |
| 5 | CREATE OR REPLACE |
Static | Objects use CREATE OR REPLACE syntax for idempotent deployment. |
| 6 | Schema qualification | Run | Objects are created in the correct schema namespace. |
| 7 | Dependency validation | Hybrid | Referenced objects exist and are accessible at compile time. |
| 8 | Trigger event validation | Run | Trigger events match Oracle source exactly (BEFORE/AFTER, INSERT/UPDATE/DELETE). |
| 9 | Permission check | Run | Deployment user has necessary privileges to create the object. |
Results
The internal test converted 6 objects successfully (3 procedures, 2 functions, 1 trigger) in a controlled environment. AWS DMS SC action item codes were cleared, and documentation references were captured and logged for audit trail purposes. Results will vary for larger or more complex schemas.
| Metric | Value | Notes |
| Objects converted | 6 | Three procedures, Two functions, One trigger |
| Avg. confidence | 92 percent | Per converted object |
| Avg. conversion time | 60–75 sec | Per object (includes Amazon Bedrock inference, MCP documentation lookup, Lambda deployment, and 9-test validation) |
| Test conversion cost | $0.15–$0.30 | Amazon Bedrock cost for the 6-object conversion (Anthropic Claude Sonnet 4.6 pricing). Lambda and Aurora costs are negligible. |
| Est. enterprise cost | $15–$30 | Estimated Amazon Bedrock cost for 500 objects |
Challenges and lessons learned
Model non-determinism at temperature 0
Even at temperature 0, the model exhibited three manifestations of non-determinism that required mitigation:
- Inconsistent whitespace: Resolved with post-processing normalization.
- Variable naming variations: Mitigated through explicit naming conventions in the system prompt.
- Optional clause ordering: Standardized through template enforcement in the prompt.
Oracle source reader: header vs body
Oracle stores trigger definitions as compiled objects without the original DDL. The solution reconstructs trigger DDL by querying USER_TRIGGERS and USER_SOURCE tables, then reassembling the CREATE TRIGGER statement, including timing (BEFORE/AFTER), event list (INSERT/UPDATE/DELETE), table name, and row level (FOR EACH ROW).
Lambda autocommit requirement
Initial testing used autocommit=False, which caused DDL statements to be lost on connection close. Setting autocommit=True resolves this and ensures DDL persistence outside explicit transactions. To help you avoid this issue, the Lambda deployer code in this solution has autocommit=True pre-configured with an inline comment explaining why it is required.
Dependency validation gap
PostgreSQL performs stricter compile-time dependency checking than Oracle. Functions referencing non-existent tables fail at CREATE time, requiring dependency-ordered deployment. The testing engine’s dependency validation test (Test 7) catches these issues before they reach production.
Security considerations
This solution implements the following security best practices:
- SQL identifier sanitization: Object names are validated against a strict regex (
^[a-zA-Z_][a-zA-Z0-9_]{0,62}$) before being used in DDL statements, rejecting names with special characters, semicolons, or comment sequences. Dynamic SQL uses PostgreSQL’squote_ident()for identifiers andquote_literal()for string values. - No credentials in code: Database credentials are retrieved from Secrets Manager at runtime. The Lambda’s IAM role is scoped to access only the specific secret ARN required.
- Lambda VPC isolation: Lambda runs in private subnets with no internet access. Its security group permits only outbound PostgreSQL traffic (port 5432) to the Aurora security group, with no other outbound or inbound traffic. If compromised, it cannot reach external endpoints or exfiltrate data.
- Read-only source access: The Oracle source database connection uses a read-only user with
SELECTonUSER_SOURCEandUSER_TRIGGERSonly. No write operations are performed against the source.
Extending this solution
The architecture leaves clear extension points if you want to adapt it to your environment:
- Idempotent deployments: add
DROP IF EXISTSbeforeCREATE OR REPLACEin environments where signature conflicts arise from prior partial migrations. - Parameter signature validation: compare Oracle and PostgreSQL parameter lists programmatically to catch mismatches before deployment.
- Parallel conversion: process multiple objects concurrently for large enterprise schemas (10–20 objects in parallel is a reasonable starting point given Amazon Bedrock throughput).
- Rollback: keep a version history of deployed objects so a failed validation can revert to the prior known-good state.
- CI/CD integration: wrap the agent in a GitHub Actions or AWS CodePipeline workflow to run conversions and tests on every commit.
- Other dialect pairs: the pipeline is dialect-agnostic. Only the system prompt and conversion rules are Oracle-to-PostgreSQL specific. The same architecture (AWS DMS SC CSV parsing, source extraction, generative AI conversion, deployment, testing) applies to other AWS DMS SC source-target pairs such as SQL Server to Aurora MySQL or Oracle to Amazon Redshift.
Clean up
To avoid ongoing charges, delete the resources you created as part of this solution:
- Delete the Lambda SQL deployer function.
- Terminate or delete the Aurora PostgreSQL cluster if you created it for this exercise.
- Terminate or delete the Amazon RDS Oracle instance if you created it for this exercise.
- Delete the Amazon S3 buckets you created to store the converted scripts and assessment reports.
- Remove the IAM roles and policies created for Lambda execution and database access.
- Delete the secrets stored in Secrets Manager for database credentials.
- Disable or remove Amazon Bedrock model access if no longer needed.
Conclusion
In this post, you saw how to automate the last mile of Oracle to Amazon Aurora PostgreSQL code migration using Amazon Bedrock, the Strands Agents framework, and the AWS Knowledge MCP Server. The solution picks up where AWS DMS SC leaves off, handling the complex PL/SQL patterns (transaction control, exception handling, Oracle-specific functions) that require reasoning beyond rule-based conversion. The architectural guardrails are what make it reliable in practice: real-time access to the Oracle to Aurora PostgreSQL migration playbook through the MCP server, immediate syntax validation by deploying to Aurora through AWS Lambda, and a 9-scenario testing engine that validates each converted object before it reaches a human reviewer. In our internal testing, the agent converted procedures, package bodies, functions, and triggers at 92 percent average confidence in 60–75 seconds per object.
To try this yourself, run AWS DMS SC against your Oracle source, point the agent at the resulting CSV report, and validate the output against an Aurora PostgreSQL test cluster. The complete reference implementation is on aws-samples on GitHub, and the broader Oracle-to-Aurora migration guidance lives in the AWS Prescriptive Guidance library. We are interested in hearing how this works on your schemas. Share your experience in the comments.