AWS Database Blog
Create an AWS Glue Data Catalog with AWS DMS
Businesses need near realtime access to the latest data and metadata available from many silos to perform analytics. AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML) and application development. AWS Glue Data Catalog is a centralized metadata store that integrates with Amazon Simple Storage Service (Amazon S3) and provides immediate data querying using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum. However, the need to run a crawler or additional extract, transform, and load (ETL) jobs to create this catalog manually can be time-consuming.
AWS Database Migration Service (AWS DMS) is a managed migration and replication service that helps you move your databases and analytics workloads to AWS quickly and securely. The source database remains fully operational during the migration, minimizing downtime to applications that rely on the database. AWS DMS also provides ongoing data replication from many structured, unstructured, and semi-structured data sources with Amazon S3 as a target. AWS DMS announced an expanded feature of Amazon S3 as a target by adding the ability to create an AWS Glue Data Catalog of the objects identified by AWS DMS during data migration or replication. In this post, we show you how to automatically create an AWS Glue Data Catalog of desired tables, including ones without data, from a relational database using AWS DMS and then query that data using Amazon Athena.
Solution Overview
For the purpose of this post, all AWS resources are within a single AWS account, Amazon Virtual Private Cloud (VPC), and AWS Region. The following resources are components of this post:
- Source database: Any AWS DMS supported sources for data migration to migrate initial data load or ongoing data changes. This post references a source database in AWS only as an example.
- S3 bucket: Using Amazon S3 as a target for AWS DMS to store the data files generated by AWS DMS.
- AWS DMS replication instance: Runs replication tasks to migrate data from the source database to the target S3 bucket.
- AWS Identity and Access Management (IAM) role and policy: Allows AWS DMS to access the S3 bucket, AWS Glue Data Catalog, and Amazon Athena.
- AWS Glue: AWS Glue Data Catalog generated via AWS DMS.
- Amazon Athena: Queries the AWS Glue Data Catalog and displays results.
The following diagram illustrates the architecture of this solution.

Walkthrough
You will provision AWS resources with specific configurations needed for this solution, including required Amazon VPC networking components and review expected results.
The following steps walk you through the order of provisioning and configuring resources needed to verify results:
- Create IAM role and policy
- Create needed Amazon VPC endpoints
- Create AWS DMS resources
- Run the AWS DMS migration task
- Review results
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- An Amazon VPC with at least 2 availability zones
- A source database containing data to migrate
- An S3 bucket and a bucket folder in the same region as your Amazon VPC
- Network connectivity between your source database and Amazon VPC with a Security Group configured to allow traffic
Let’s get started by signing in to the AWS Management Console. Be sure to verify the AWS Region and that you have access to the services identified in the solution overview.
Prepare IAM resources
Create the IAM policy needed for Using AWS Glue Data Catalog with an Amazon S3 target. Follow the instructions from Creating IAM policies and use the following JSON policy document, substituting <YOUR ACCOUNT NUMBER> with your AWS account number and <YOUR BUCKET NAME> with your S3 bucket name:
Now create an IAM role by following the instructions from Creating a role for an AWS service, choosing AWS DMS (dms.amazonaws.com) as a trusted entity and selecting the policy you just created. You should have the following IAM role represented by dms-s3-glue-athena-role with an attached policy of dms-s3-glue-athena-policy.


Prepare Amazon VPC endpoints
AWS DMS version 3.5.1 is required to support the automatic generation of your AWS Glue Data Catalog with Amazon S3 as a target. If Amazon VPC endpoints do not exist for Amazon S3 and Amazon Athena, follow the instructions for Configuring VPC endpoints as AWS DMS source and target endpoints to create each Amazon VPC endpoint. You should have the following endpoints created for your Amazon VPC and attached routes for the subnets.

Prepare AWS DMS components
AWS DMS consists of these components:
- Replication instance – Managed instance to host AWS DMS software.
- Endpoints – Connection descriptions for sources (database) and targets (Amazon S3).
- Database migration tasks – Describes the particular data load and/or change data capture (CDC) rules.
The replication instance is required to support endpoints and migration tasks. To create the replication instance, the instance type must be properly selected. For more information on how to choose an instance class, see Choosing the right AWS DMS replication instance for your migration.
On the AWS DMS console, choose Replication instances and select Create replication instance. Follow Creating a replication instance instructions and choose 3.5.1 for Engine version, and for Virtual private cloud (VPC) for IPv4 choose the same Amazon VPC where your S3 bucket resides. The default option is for a publicly available replication instance, we recommend to deselect that option to keep access restricted to within your VPC.

Next, create the AWS DMS endpoint for your source database following the instructions Creating source and target endpoints. Be sure to follow any prerequisites and configurations required for your source database engine as documented in the Sources for data migration guide. The following image illustrates an AWS DMS source endpoint of an Amazon Relational Database Service (Amazon RDS) for PostgreSQL database.
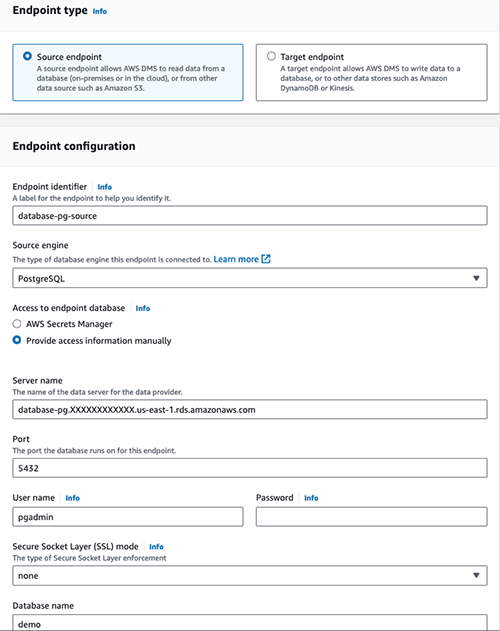
Now, create the AWS DMS target endpoint:
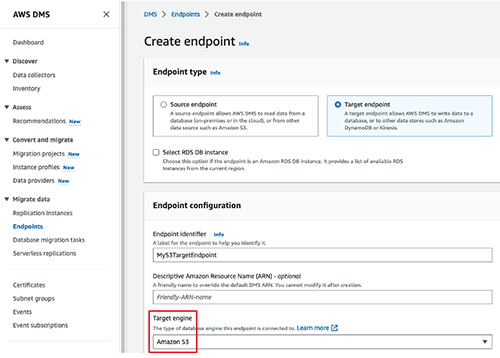
Create the AWS DMS target endpoint for your S3 bucket
- Go to the AWS DMS console.
- From the left navigation panel, choose Endpoints.
- Select the Create endpoint button.
- Choose Target Endpoint.
- In the Endpoint identifier text box, enter the name for this endpoint.
- For the Target engine, select Amazon S3.
- In Amazon Resource Name (ARN) for service access role, enter the Amazon resource name of the IAM role you created.
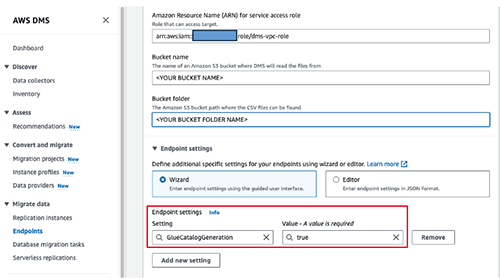
- In Bucket name, enter your S3 bucket name identified in the IAM role you created.
- In Bucket folder, enter your S3 bucket folder name.
- Select Endpoint settings to expand options, select the Add new setting button, and choose GlueCatalogGeneration from the list of available parameters. Add other desired Endpoint settings when using Amazon S3 as a target for AWS DMS, excluding PreserveTransactions and CdcPath.
- Enter
trueinto Value – A value is required. - Choose the Create endpoint button.
Now create an AWS DMS migration task following the instructions Creating a task to migrate your data from your source database to the S3 bucket folder while AWS DMS generates your AWS Glue Data Catalog for you. Additionally, you can use the AWS DMS Transformation rules and actions rule-action=Rename to control the S3 subfolder and AWS Glue Data Catalog names.
Let’s run the AWS DMS migration task and review the results.
Review results
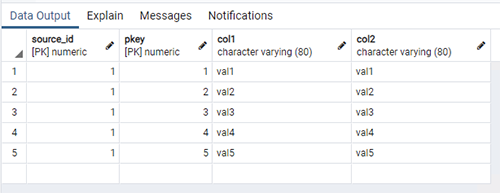
The following image illustrates a representative source database schema named demo with two tables: source_table containing five records and empty_table containing no data.
The following image illustrates AWS DMS data migration results created in the target S3 bucket. Notice that demo.source_table data was successfully migrated to Amazon S3 and that demo.empty_table is absent. This is the expected outcome since AWS DMS creates associated folders only for tables containing data. Also notice AWS DMS creates a folder named athena_query_results as part of the generation of the AWS Glue Data Catalog.
 |
 |
 |
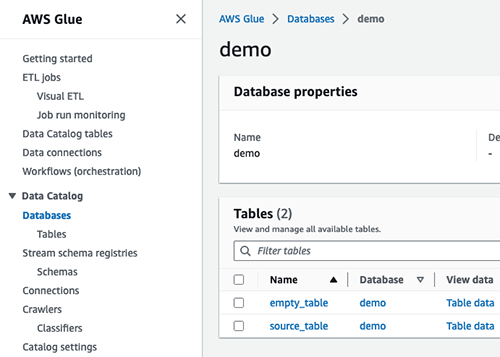
Now let’s look at the AWS Glue Data Catalog. Notice the demo database was created by AWS DMS that include both the source_table and empty_table tables. This provides a consistent schema that matches the source database for the tables included in the AWS DMS data migration task regardless of data existence.
In this illustration, we use Amazon Athena to query the AWS Glue Data Catalog created by AWS DMS to verify the data migration results from the demo.source_table. Notice the same five records are returned. A query of demo.empty_table returns no results as expected.


Cleaning up
To avoid incurring future charges, delete any resources provisioned to experiment with this feature.
- Delete any AWS Glue databases created by AWS DMS.
- Delete any data objects created in Amazon S3 by AWS DMS, including buckets and folders, if no longer used.
- Delete AWS DMS migration tasks, endpoints, and replication instances.
- Delete associated IAM policy and role.
Conclusion
In this post, we showed you how to use AWS DMS to automatically create an AWS Glue Data Catalog with Amazon S3 as a migration target. With this integration, you have more immediate access to perform analytics on your data and metadata without needing to run crawlers or ETL jobs to create a catalog. Furthermore, the AWS Glue Data Catalog contains a consistent schema of identified tables, including those without data.
To learn more about featured services shared in this post, refer to the AWS Database Migration Service User Guide and the AWS Glue Developer Guide.
We welcome your feedback and encourage you to share your insights, ask questions, or offer alternatives by adding comments below.
About the Author

Don Gaudreau is a Database Specialist Solutions Architect at AWS. He works with our customers to provide architecture guidance and database solutions in support of their data strategy.