AWS Database Blog
Migrate data from Apache HBase to Amazon DynamoDB
Over the last few years, organizations have started adopting a cloud first strategy, and we are seeing enterprises migrate their mission-critical applications, along with their data platforms, to the cloud. Occasionally, organizations need guidance in selecting the right service and solution in the cloud, along with an approach to assist with the migration. In this post, we describe how you can migrate data from your on-premises Apache HBase database to Amazon DynamoDB. We also describe the rationale for migrating to DynamoDB, along with potential approaches and considerations.
Migration considerations
Before we start focusing on the migration, it’s important to design the solution that meets your requirements. We see some customers use Hadoop-based Apache HBase database for their non-relational NoSQL data store requirements. HBase is a column-oriented, distributed, scalable, big data store that runs on top of Apache Hadoop Distributed File System (HDFS), and stores data in multiple key-value pairs. It’s popular for fast writes and random-access queries across large datasets in terabytes and petabytes. But when you’re migrating workloads to the cloud, you have the opportunity to explore solution characteristics along with functional and non-functional requirements, and use the right AWS service for the solution.
Customers find that DynamoDB is sometimes a better fit due to its serverless, fully managed architecture that removes operational overhead. The other advantages are its elasticity and automated scaling capabilities, virtually unlimited throughput, consistent performance at any scale, and integration with other AWS services for logging, auditing, monitoring, security, analytics, and more. DynamoDB supports Amazon DynamoDB Accelerator (DAX), a fully managed, highly available, in-memory cache for DynamoDB that provides response times in microseconds. Using DynamoDB with DAX enables use cases that require response times in microseconds.
However, customers need to make sure that their workload profile, data types, use cases, and data model are the right fit when choosing a new database. The Comparing the Use of Amazon DynamoDB and Apache HBase for NoSQL whitepaper is an excellent resource in providing guidance on selecting the right data store—DynamoDB or Apache HBase—to meet your requirements.
Use cases and identifying the data to be migrated
We’ve come across scenarios where HBase is used to support multiple applications and workloads. It’s a good practice to separate these use cases and look at them individually to select the best database and data store solutions. Quite often you’ll see a workload or monolith can be broken into multiple applications, and some of these applications are better suited to use different data stores such as DynamoDB or Amazon Aurora instead of HBase.
HBase can store tables and data across workloads. After performing your analysis based on workload profiles, data models, data access and usage pattern, and cost, you can identify target data stores per workload or application. For example, if one of the workloads using HBase as a database is a high-volume web application, or an application with a single-digit millisecond response time, DynamoDB would be a good fit. But if your workload is a batch-oriented application with large historical datasets needed for historical trend analysis, Apache HBase might be a good choice because of its high read and write throughput and efficient storage of sparse data. You can read about common use cases for DynamoDB and HBase to help with database selection.
Based on your analysis, you can break the HBase application to align with the best architectural practices. In some cases, a workload would be a better fit to continue using Apache HBase, and you can migrate these workloads and associated HBase to AWS using the guidelines and best practices recommended by AWS.
Solution approaches
Now that we’ve identified the workload and data suited to be migrated to DynamoDB, let’s look at various approaches you can use for the migration. The intent is not to compare different solutions but to share different approaches available for the migration. There’s no “best” solution; the right solution depends on your organization’s requirements, IT ecosystem, skills and expertise, amount of data to be migrated, and use case.
The approaches are divided into two sections: one for migrating (querying and ingesting) data from an on-premises HBase database to Amazon Simple Storage Service (Amazon S3), and one for ingesting the data from Amazon S3 into DynamoDB. The reason for this categorization is that in some cases organizations want to ingest data into a data lake, transform the data, and then move the data to DynamoDB, instead of migrating the data directly into DynamoDB. This would allow organizations to cater to multiple use cases with the same data, and make the data available to multiple data stores based on their requirements. Depending on your approach, you can skip to the section that suits your requirements. We’ve also touched upon a third optional approach for a change data capture (CDC) and streaming scenario, in case your use case warrants it.
Migrating on-premises HBase data to Amazon S3
There are multiple approaches to migrate data from an on-premises HBase cluster to Amazon S3. In this post, we discuss just two.
Apache Spark HBase connector
You can use the Apache Spark HBase Connector for extracting the HBase data. This open-source connector can be used along with AWS Glue to ingest the data from HBase. Another variant of this approach is to create your own custom connector for AWS Glue and use it to extract data from the on-premises HBase cluster.
CData AWS Glue Connector for Apache HBase
This option uses the AWS Marketplace Glue Connector for Apache HBase provided from CData. The connector is easy to configure and can migrate the data from on-premises HBase to DynamoDB using AWS Glue. The advantage of this approach is that you can transform the data using AWS Glue, it’s a serverless solution so you don’t need to manage any servers, and the connector is supported by the vendor (CData) so if the connector doesn’t work as intended or needs additional capabilities, you can work with CData to address the challenges. This connector uses Amazon Elastic Container Service (Amazon ECS) for setup. You can also download the connector directly from CData’s website, store the CData JDBC driver for HBase in Amazon S3, and create a custom AWS Glue connector using the JDBC driver. The AWS Glue connector works similarly to the AWS Marketplace connector, and we use this approach in this post.
Migrate data from Amazon S3 into DynamoDB
After the data is migrated from on-premises HBase to Amazon S3, we can move to the next part of the solution: migrating or ingesting this data from Amazon S3 into DynamoDB.
Import Amazon S3 data into a new DynamoDB table
The import table feature allows you to perform a bulk import of data from Amazon S3 into DynamoDB. It’s a fully managed feature that doesn’t require writing code or managing infrastructure. The limitation of this approach is that the data can’t be imported to existing DynamoDB tables.
AWS Glue
You can use AWS Glue to read the data from Amazon S3 and insert data into DynamoDB. The benefit of this approach is that you can transform the data while loading the data, it’s a serverless and fully managed approach, and the data can be added to an existing DynamoDB table.
External Hive table and Amazon EMR
In this approach, you create an Amazon EMR cluster, create an external Hive table that points to the Amazon S3 location that stores the data, create another external Hive table that points to the DynamoDB table, and use the INSERT OVERWRITE command to write the data to the DynamoDB table.
Some of the approaches we’ve mentioned are referenced in the AWS Knowledge Center post How do I issue a bulk upload to a DynamoDB table?
CDC streaming approach
This CDC-based approach streams Apache HBase edits for real-time analytics. With the approach, you can stream the changes using Amazon Kinesis Data Streams to update DynamoDB in near-real time. This approach would make sense if you’re planning to retain the on-premises HBase database and want to replicate changes from HBase to DynamoDB. This could act as the tactical, short-term transitional solution while you’re migrating your workloads to AWS, and you need to support applications both on premises and in AWS for a short duration.
Solution overview
So far, we’ve discussed various approaches for migrating data from on-premises HBase to DynamoDB. In the following sections, we migrate data using a custom AWS Glue connector using the CData HBase JDBC driver.
Prerequisites
The following are the prerequisites for the migration:
- An AWS account where the target DynamoDB table will be created
- An Apache HBase source database, deployed either on premises or on a cloud platform
- Networking connectivity between the environment where the source Apache HBase database is deployed and the target environment (AWS)
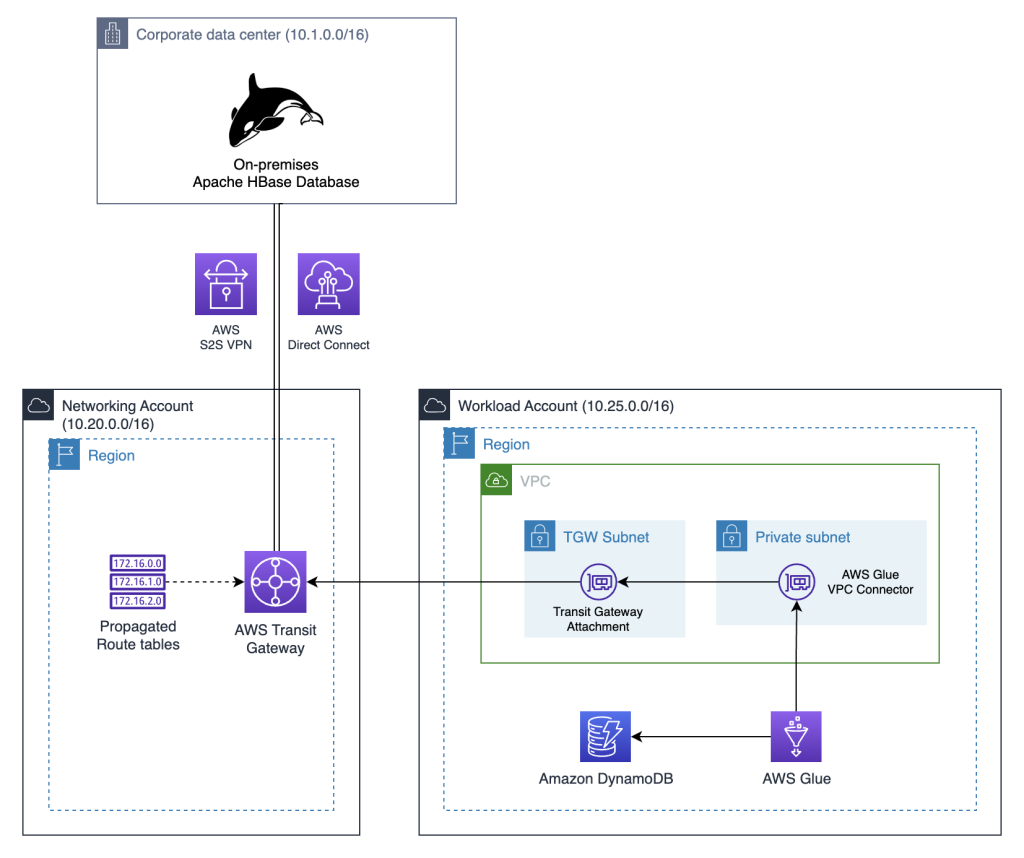
Many of our customers have adopted AWS Control Tower as a foundation for their multi-account strategy to achieve the twin objectives of business agility and centralized governance. The following figure shows an example setup that includes a centralized networking account to define and manage network connectivity required for this solution using AWS Transit Gateway.
Set up the CData AWS Glue Connector for Apache HBase
This section shows the steps to set up and use the CData AWS Glue Connector for Apache HBase, which simplifies the process of connecting AWS Glue jobs to extract and load data from HBase. There are two options to set up the connector:
- Via AWS Marketplace, which hosts the connector on either Amazon ECS or an Amazon Elastic Kubernetes Service (Amazon EKS) cluster
- Download the connector and JDBC driver from CData’s website and store it in Amazon S3
Both approaches work the same way with AWS Glue, and there’s no functional difference between the two. In this post, we use the second option (downloading the connector from CData’s website). Complete the following steps:
- Download the CData JDBC driver and upload it to an S3 bucket.

- Provide a real-time key in the RTK property in the JDBC URL—you can obtain the key from CData team.
- Once you have the RTK, you can use AWS Secrets Manager to store it, instead of having to hard-code it in the AWS Glue job, which is the recommended approach.
- Store the source host and port information in the secret, as shown in the following screenshot.

- Because AWS Glue will need to get the CData JDBC driver from Amazon S3, the RTK from Secrets Manager, and write data to DynamoDB, ensure that the AWS Identity and Access Manager (IAM) service role used by the AWS Glue job has appropriate permissions.
- To create a new AWS Glue custom connector, go to the AWS Glue Studio console. On the AWS Glue Studio console, choose Data connections in the navigation pane, then choose Create custom connector.

- Provide all the required custom connector properties:
- For Connector S3 URL, browse Amazon S3 and choose the .jar file you uploaded earlier (be sure to choose the actual file and not just the bucket containing the .jar file).
- For Name, enter a unique name.
- For Connector type, choose JDBC.
- For Class name, enter
cdata.jdbc.apachehbase.ApacheHBaseDriver. This is the class name for the CData HBase JDBC driver. - For JDBC URL Base, enter
jdbc:apachehbase:Server=${host};Port=${port};RTK=${RTK}. The values forhost,port, andRTKwill come from the secret you created in Secrets Manager. - For URL parameter delimiter, enter a semi-colon (
;).
- Choose Create connector.

- After the custom connector is successfully created, choose Create a new connection.

- On the Create connection page, the custom connector will be pre-selected. Enter a unique name for the connection and an optional description.

- In the Connection access section, enter the following values:
- For Connection credential type, choose default.
- For AWS Secret, choose the secret you created earlier.
- Leave the fields for your connection properties blank. The values are pulled from Secrets Manager.

- To allow AWS Glue access to the on-premises Apache HBase using a private DNS, complete the Network options section:
- Provide a VPC and subnet.
- Make sure that the security group you choose allows access to the Apache HBase database’s server and port.
- Choose Create connection.

Migrate the data
The following architecture represents how the solution comes together. Depending on your organization’s requirements, you may decide to follow a slightly different solution. For example, in the solution described in this post, we’re transforming and migrating the data from HBase to DynamoDB in a single step. But your organization may break up the process into two or more parts:
- Migrate the data from HBase to Amazon S3.
- Transform the data as per enterprise policies, and then load the data into DynamoDB.
This second step can be broken into two parts: for instance, store the transformed data back to Amazon S3, and then subsequently load the data into DynamoDB.
The approach that you implement depends on various factors, such as whether you’re implementing a data lake and want to ingest the data in Amazon S3, multiple potential consumers or applications want to consume the HBase data, different transformations need to be applied to the same data depending on the scenario or end-users, different security and access policies need to be applied to the same dataset, and more. No matter which approach your organization follows, the HBase to DynamoDB data migration solution remains similar.

In the following example script, we load the customer profile information from the Apache HBase table to a target table defined in DynamoDB. We also show how you can add additional transformations, such as ApplyMapping, while performing the full load to the DynamoDB table. Complete the following steps to transform and move the data to DynamoDB:
- Define the DynamoDB table:
- Specify the table name and partition key.
- Optionally, you can specify a sort key and custom settings.

- Create and run a crawler to catalog the DynamoDB table in the AWS Glue Data Catalog.
- Enter a name and optional description, then choose Next.

- For Data sources, choose Add a data source.

- Choose the DynamoDB table that you created and choose Add a DynamoDB data source.

- Select the data source and choose Next.

- Choose the IAM role you created earlier and choose Next.

- Add or choose the AWS Glue database where the metadata table will be added and choose Next.

- Review your settings and choose Create crawler.

- On the crawler details page, choose Run crawler.

Upon a successful crawler run, verify that the table was created in the AWS Glue Data Catalog. Note that the schema will be empty because we haven’t added any data to the table yet. If the table had data, the schema would be populated accordingly.

- Choose Jobs in the navigation pane, then create a job using the Visual with a source and target option.
- For Source, choose the CData custom connector.
- For Target, choose the AWS Glue Data Catalog.

- In the visual editor, choose the data source and then choose HBase-Connection on the Connection drop-down menu.
- Specify the table name to read data from the source database for full load. You can alternatively specify a query code or filter predicate when you create and add a connector to AWS Glue Studio.

Next, you will need to add schema for your data source.
- Choose the Data preview tab to generate a preview.

- On the Output schema tab, choose Use data preview schema.

- Choose the ApplyMapping transformation and add the necessary mappings. You can add other transformations as needed.

- On the Data target properties – Data Catalog tab, choose the target database and table.

- On the Job details tab, under Basic properties, choose the IAM role created during setup.

- Under Connections, choose the JDBC connection defined in the setup.

- Save and run the job.

Upon a successful job run, the DynamoDB table is populated with the data from the corresponding HBase table.

Clean up
To avoid future charges in your AWS account, delete the resources you created in this walkthrough if you don’t intend to use them further:
- Delete the AWS Glue resources you created: the job, table, database, connection, and connector.
- Remove the CData JDBC connector JAR file that was stored in the S3 bucket and was used by the AWS Glue job. Don’t renew the license when it expires.
- Delete the DynamoDB tables you created while following the post.
Conclusion
In this post, we discussed multiple approaches to migrate data from on-premises Apache HBase to DynamoDB, along with various considerations. The post also showed how you can migrate the data using AWS Glue and the CData JDBC driver for Apache HBase. Although we described a single approach, we highly recommend choosing the appropriate approach based on your organization’s requirements, and test different approaches before finalizing the solution, as per the best practices for developing in the cloud.
If you have any questions or feedback, leave them in the comments section.
About the Authors
 Amandeep Bajwa is a Senior Solutions Architect at AWS supporting Financial Services enterprises. He helps organizations achieve their business outcomes by identifying the appropriate cloud transformation strategy based on industry trends, and organizational priorities. Some of the areas Amandeep consults on are cloud migration, cloud strategy (including hybrid & multicloud), digital transformation, data & analytics, and technology in general.
Amandeep Bajwa is a Senior Solutions Architect at AWS supporting Financial Services enterprises. He helps organizations achieve their business outcomes by identifying the appropriate cloud transformation strategy based on industry trends, and organizational priorities. Some of the areas Amandeep consults on are cloud migration, cloud strategy (including hybrid & multicloud), digital transformation, data & analytics, and technology in general.
 Deevanshu Budhiraja is a Senior Solutions Architect at AWS with a chronicle of success in designing business & technology strategy, cloud adoption framework and datacenter migrations for enterprise customers across the globe.
Deevanshu Budhiraja is a Senior Solutions Architect at AWS with a chronicle of success in designing business & technology strategy, cloud adoption framework and datacenter migrations for enterprise customers across the globe.
 Simran Singh is a Senior Solutions Architect at AWS. In this position he helps our customers navigate their journey to the cloud to achieve their business outcomes. He is also a proud owner of coveted golden jacket – for achieving all active AWS certifications.
Simran Singh is a Senior Solutions Architect at AWS. In this position he helps our customers navigate their journey to the cloud to achieve their business outcomes. He is also a proud owner of coveted golden jacket – for achieving all active AWS certifications.